This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
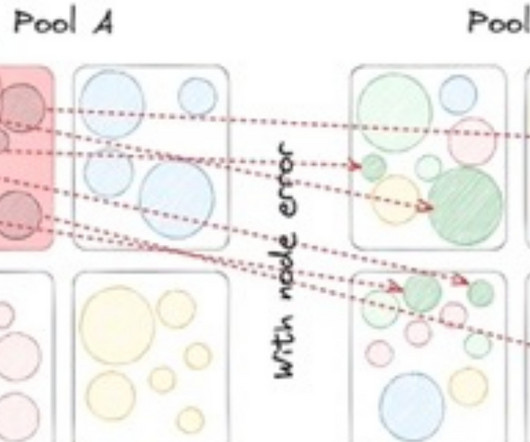
By: Rajiv Shringi , Oleksii Tkachuk , Kartik Sathyanarayanan Introduction In our previous blog post, we introduced Netflix’s TimeSeries Abstraction , a distributed service designed to store and query large volumes of temporal event data with low millisecond latencies. Today, we’re excited to present the Distributed Counter Abstraction.
What is the availability, configurability, and efficacy of each? ?️ Caching them at the other end: How long should we cache files on a user’s device? Plotted on the same horizontal axis of 1.6s, the waterfalls speak for themselves: 201ms of cumulative latency; 109ms of cumulative download. Cache This is the easy one.
This gives fascinating insights into the network topography of our visitors, and how much we might be impacted by high latency regions. Round-trip-time (RTT) is basically a measure of latency—how long did it take to get from one endpoint to another and back again? What is RTT? That’s exactly what this article is about.
We introduce a caching mechanism in the API gateway layer, allowing us to offload processing from singleton leader elected controllers without giving up strict data consistency and guarantees clients observe. We started seeing increased response latencies and leader servers running at dangerously high utilization.
Caching is the process of storing frequently accessed data or resources in a temporary storage location, such as memory or disk, to improve retrieval speed and reduce the need for repetitive processing. Bandwidth optimization: Caching reduces the amount of data transferred over the network, minimizing bandwidth usage and improving efficiency.
“Latency” is the duration from the execution of a load instruction (to an address that misses in all the caches), and the completion of that load instruction when the data is returned from memory. . The example below is for a 2005-era processor with 60 ns memory latency and 6.4
Yet, many are confined to a brief temporal window due to constraints in serving latency or training costs. In recommendation systems, context windows during inference are often limited to hundreds of eventsnot due to model capability but because these services typically require millisecond-level latency.
We note that for MongoDB update latency is really very low (low is better) compared to other dbs, however the read latency is on the higher side. The latency table shows that 99th percentile latency for Yugabyte is quite high compared to others (lower is better). Again Yugabyte latency is quite high. Conclusion.
The GraphQL shim enabled client engineers to move quickly onto GraphQL, figure out client-side concerns like cache normalization, experiment with different GraphQL clients, and investigate client performance without being blocked by server-side migrations. To launch Phase 1 safely, we used AB Testing. How does it work?
Because microprocessors are so fast, computer architecture design has evolved towards adding various levels of caching between compute units and the main memory, in order to hide the latency of bringing the bits to the brains. This avoids thrashing caches too much for B and evens out the pressure on the L3 caches of the machine.
Users might already have the file cached. If website-a.com links to [link] , and a user goes from there to website-b.com who also links to [link] , then the user will already have that file in their cache. On a slower, higher-latency connection, the story is much, mush worse. Penalty: Caching. Myth: Cross-Domain Caching.
Central to this infrastructure is our use of multiple online distributed databases such as Apache Cassandra , a NoSQL database known for its high availability and scalability. It also serves as central configuration of access patterns such as consistency or latency targets.
The good news is that you can maximize availability and prevent website crashes by designing websites specifically for these events. There are also online optimization tools available like Tinify , as well as advanced image editing software like Photoshop or GIMP : Image format is also a key consideration. Lets jump right in!
Spring Boot 2 uses Micrometer as its default application metrics collector and automatically registers metrics for a wide variety of technologies, like JVM, CPU Usage, Spring MVC, and WebFlux request latencies, cache utilization, data source utilization, Rabbit MQ connection factories, and more. That’s a large amount of data to handle.
The new Amazon capability enables customers to improve the startup latency of their functions from several seconds to as low as sub-second (up to 10 times faster) at P99 (the 99th latency percentile). This can cause latency outliers and may lead to a poor end-user experience for latency-sensitive applications.
The RAG process begins by summarizing and converting user prompts into queries that are sent to a search platform that uses semantic similarities to find relevant data in vector databases, semantic caches, or other online data sources. Observing AI models Running AI models at scale can be resource-intensive.
It provides a good read on the availability and latency ranges under different production conditions. The upstream service calls the existing and new replacement services concurrently to minimize any latency increase on the production path. It helps expose memory leaks, deadlocks, caching issues, and other system issues.
The first—and often most surprising for people to learn—thing that I want to draw your attention to is that TTFB counts one whole round trip of latency. The reason is because mobile networks are, as a rule, high latency connections. only to find that the resource they’re requesting isn’t in that PoP ’s cache.
Throughout this evolution, we’ve been able to maintain high availability and a consistent message delivery rate, with Pushy successfully maintaining 99.999% reliability for message delivery over the last few months. In our case, we value low latency — the faster we can read from KeyValue, the faster these messages can get delivered.
Because of its scalability and distributed architecture, thousands of companies trust it to run their cloud and hybrid-based workloads at high availability without compromising performance. With the Dynatrace Data Explorer, you can easily analyze metrics, such as client read/write latency by Cassandra nodes and disk space usage by keyspaces.
This allows the app to query a list of “paths” in each HTTP request, and get specially formatted JSON (jsonGraph) that we use to cache the data and hydrate the UI. Being able to canary a new route let us verify latency and error rates were within acceptable limits. ecosystem and the rich selection of npm packages available.
Rajiv Shringi Vinay Chella Kaidan Fullerton Oleksii Tkachuk Joey Lynch Introduction As Netflix continues to expand and diversify into various sectors like Video on Demand and Gaming , the ability to ingest and store vast amounts of temporal data — often reaching petabytes — with millisecond access latency has become increasingly vital.
Moreover, common database optimizations like caching recently queried data don’t really work for alerting queries because, generally speaking, the last received datapoint is required for correctness. The fundamental idea behind Telltale is to detect anomalies on SLI metrics (for example, latency, error rates, etc).
The Tech Hollow , an OSS technology we released a few years ago, has been best described as a total high-density near cache : Total : The entire dataset is cached on each node?—?there there is no eviction policy, and there are no cache misses. Near : the cache exists in RAM on any instance which requires access to the dataset.
The Site Reliability Guardian helps automate release validation based on SLOs and important signals that define the expected behavior of your applications in terms of availability, performance errors, throughput, latency, etc. A study by Amazon found that increasing page load time by just 100 milliseconds costs 1% in sales.
RevenueCat extensively uses caching to improve the availability and performance of its product API while ensuring consistency. The company shared its techniques to deliver the platform, which can handle over 1.2 billion daily API requests. By Rafal Gancarz
These integrations are implemented through Metaflow’s extension mechanism which is publicly available but subject to change, and hence not a part of Metaflow’s stable API yet. Deployment: Cache To produce business value, all our Metaflow projects are deployed to work with other production systems.
But we cannot search or present low latency retrievals from files Etc. Marken Architecture Our goal was to help teams at Netflix to create data pipelines without thinking about how that data is available to the readers or the client teams. This is obviously very expensive. Write algo runs into files.
For example, when monitoring a database, you’ll want to know about any latency when writing data to a disk or average query response time. Examples include a spike in memory utilization, a decrease in cache hit ratio, or an increase in CPU utilization.
Choosing your database architecture may be the most critical decision you’ll make and has a disproportionate impact on the performance, scalability, and availability of your app. Get it right and your application will seamlessly scale from hundreds to tens of millions of users without difficulty, while remaining performant and available.
Key Takeaways Critical performance indicators such as latency, CPU usage, memory utilization, hit rate, and number of connected clients/slaves/evictions must be monitored to maintain Redis’s high throughput and low latency capabilities. It can achieve impressive performance, handling up to 50 million operations per second.
There was no appetite from them to do so, so I decided to make it all available for free anyway—a faster web benefits everyone. To further exacerbate the problem, the 302 response has a Cache-Control: must-revalidate, private. com , which introduces yet more latency for the connection setup. Next up, we get sent to fonts.[client].com
Each of these models is suitable for production deployments and high traffic applications, and are available for all of our supported databases, including MySQL , PostgreSQL , Redis™ and MongoDB® database ( Greenplum® database coming soon). This becomes really important for cache solutions like Redis™. High Availability.
Identifying key Redis metrics such as latency, CPU usage, and memory metrics is crucial for effective Redis monitoring. To achieve optimal tracking results it is important to choose wisely among available tools like Prometheus or Grafana, which offer deeper insights into understanding your Redis instances for better performance optimization.
Key Takeaways Redis offers complex data structures and additional features for versatile data handling, while Memcached excels in simplicity with a fast, multi-threaded architecture for basic caching needs. Redis is better suited for complex data models, and Memcached is better suited for high-throughput, string-based caching scenarios.
Spring Boot 2 uses Micrometer as its default application metrics collector and automatically registers metrics for a wide variety of technologies, like JVM, CPU Usage, Spring MVC, and WebFlux request latencies, cache utilization, data source utilization, Rabbit MQ connection factories, and more. That’s a large amount of data to handle.
Spring Boot 2 uses Micrometer as its default application metrics collector and automatically registers metrics for a wide variety of technologies, like JVM, CPU Usage, Spring MVC, and WebFlux request latencies, cache utilization, data source utilization, Rabbit MQ connection factories, and more. That’s a large amount of data to handle.
It is very gratifying to see all of our learning and experience become available to our customers in the form of an easy-to-use managed service. Amazon DynamoDB offers low, predictable latencies at any scale. It provides multi-data center replication, high availability, and offers rock-solid durability. Consistency. SimpleDBâ??s
Identifying key Redis® metrics such as latency, CPU usage, and memory metrics is crucial for effective Redis monitoring. To monitor Redis® instances effectively, collect Redis metrics focusing on cache hit ratio, memory allocated, and latency threshold.
More importantly, the low resource availability or “out of memory” scenario is one of the common reasons for crashes/kills. Some features (as an example) include Device Type ID, SDK Version, Buffer Sizes, Cache Capacities, UI resolution, Chipset Manufacturer and Brand. Labeling the data?—?Ground of the time (False Positives).
Best of all, our page can load much faster since everything is cached in Elasticsearch. Listening to Kafka events adds little latency, our fan out operations are really quick since we store foreign keys to identify the edges, and looking up data in an inverted index is fast as well. Our data changes constantly?—?
Here’s how the same test performed when running Percona Distribution for PostgreSQL 14 on these same servers: Queries: reads Queries: writes Queries: other Queries: total Transactions Latency (95th) MySQL (A) 1584986 1645000 245322 3475308 122277 20137.61 MySQL (B) 2517529 2610323 389048 5516900 194140 11523.48 Why is that?
As I have talked about before, one of the reasons why we built Amazon DynamoDB was that Amazon was pushing the limits of what was a leading commercial database at the time and we were unable to sustain the availability, scalability, and performance needs that our growing Amazon.com business demanded. The opposite is true.
However, it is limited by the available free memory amount, and all data is lost when the server stops. In-Memory Storage Engine, as the name suggests, stores data in memory for faster performance and lower latencies. It uses a filesystem cache and write-ahead log for crash recovery.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content