This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
By: Rajiv Shringi , Oleksii Tkachuk , Kartik Sathyanarayanan Introduction In our previous blog post, we introduced Netflix’s TimeSeries Abstraction , a distributed service designed to store and query large volumes of temporal event data with low millisecond latencies. Today, we’re excited to present the Distributed Counter Abstraction.
We introduce a caching mechanism in the API gateway layer, allowing us to offload processing from singleton leader elected controllers without giving up strict data consistency and guarantees clients observe. The cache is kept in sync with the current leader process. How do I know that my cache is up to date? of the data.
How To Design For High-Traffic Events And Prevent Your Website From Crashing How To Design For High-Traffic Events And Prevent Your Website From Crashing Saad Khan 2025-01-07T14:00:00+00:00 2025-01-07T22:04:48+00:00 This article is sponsored by Cloudways Product launches and sales typically attract large volumes of traffic.
To harness this data effectively, we employ a process of interaction tokenization, ensuring meaningful events are identified and redundancies are minimized. Even with such strategies, interaction histories from active users can span thousands of events, exceeding the capacity of transformer models with standard self attention layers.
Because microprocessors are so fast, computer architecture design has evolved towards adding various levels of caching between compute units and the main memory, in order to hide the latency of bringing the bits to the brains. This avoids thrashing caches too much for B and evens out the pressure on the L3 caches of the machine.
The standard dictionary subscript notation is also available. For instance, you can use a Config to define a default value for a parameter which can be overridden by a real-time event as a run is triggered. this could take a few minutes) All packages already cached in s3. All environments already cached in s3.
“Latency” is the duration from the execution of a load instruction (to an address that misses in all the caches), and the completion of that load instruction when the data is returned from memory. GB/s peak DRAM bandwidth, requiring 6 concurrent 64-byte cache line accesses to be pending at all times to maintain full bandwidth.
The GraphQL shim enabled client engineers to move quickly onto GraphQL, figure out client-side concerns like cache normalization, experiment with different GraphQL clients, and investigate client performance without being blocked by server-side migrations. To launch Phase 1 safely, we used AB Testing. How does it work?
That trend will likely continue as Kubernetes security awareness further rises and a new class of security solutions becomes available. Of the organizations in the Kubernetes survey, 71% run databases and caches in Kubernetes, representing a +48% year-over-year increase.
Amazon compute solutions are designed to streamline resource provisioning and container management with two services: AWS Lambda : Lambda provides serverless compute infrastructure that lets you run code in response to predetermined events or conditions and automatically manage all compute resources required for these processes. Data Store.
The RAG process begins by summarizing and converting user prompts into queries that are sent to a search platform that uses semantic similarities to find relevant data in vector databases, semantic caches, or other online data sources. Observing AI models Running AI models at scale can be resource-intensive.
The Tech Hollow , an OSS technology we released a few years ago, has been best described as a total high-density near cache : Total : The entire dataset is cached on each node?—?there there is no eviction policy, and there are no cache misses. Near : the cache exists in RAM on any instance which requires access to the dataset.
Streams provide you with the underlying infrastructure to create new applications, such as continuously updated free-text search indexes, caches, or other creative extensions requiring up-to-date table changes. At launch, an item’s change record is available in the stream for 24 hours after it is created.
Performance Game Changer: Browser Back/Forward Cache. Performance Game Changer: Browser Back/Forward Cache. With that caveat out of the way, let’s get to the guts of the article: What is the Back/Forward Cache and why does it matter so much? Didn’t The HTTP Cache Do All That Anyway? Barry Pollard.
Moreover, common database optimizations like caching recently queried data don’t really work for alerting queries because, generally speaking, the last received datapoint is required for correctness. This is especially true when either the data is not available in Atlas or the query is not supported because of (say) cardinality constraints.
To make data count and to ensure cloud computing is unabated, companies and organizations must have highly available databases. This guide provides an overview of what high availability means, the components involved, how to measure high availability, and how to achieve it. How does high availability work?
Building on these foundational abstractions, we developed the TimeSeries Abstraction — a versatile and scalable solution designed to efficiently store and query large volumes of temporal event data with low millisecond latencies, all in a cost-effective manner across various use cases. For example: {“device_type”: “ios”}.
Browsers will cache tools popular among vocal, leading-edge developers. There's plenty of space for caching most popular frameworks. The best available proxy data also suggests that shared caches would have a minimal positive effect on performance. Suppose a user has only downloaded part of the cache.
Central to this infrastructure is our use of multiple online distributed databases such as Apache Cassandra , a NoSQL database known for its high availability and scalability. In addition to storing item size information in the page token, the server also estimates the average item size for a given namespace and caches it locally.
Dynatrace AutomationEngine workflows automate release validation using AWS Well-Architected pillars With Dynatrace, you can create workflows that automate various tasks based on events, schedules or Davis problem triggers. Workflows are powered by a core platform technology of Dynatrace called the AutomationEngine.
This would also mean I need a service that detects any new environments, creates API tokens for them, refreshes API tokens on expiry and ensures that there is always a valid API token available. TenantCache: a cache to store tenant information and API token information and semi-permanent data to avoid unnecessary roundtrips. ?
These integrations are implemented through Metaflow’s extension mechanism which is publicly available but subject to change, and hence not a part of Metaflow’s stable API yet. Explainer flow is event-triggered by an upstream flow, such Model A, B, C flows in the illustration.
After identifying about 100 idle host instances to be shut down, they learned that these hosts were provisioned in anticipation of upscaling to support an upcoming major sales event. Implement appropriate caching layers (for example, read-only cache for static data). Reduce inter-process communications overhead.
If you must kill the script at this point, there are two options available: SCRIPT KILL command can be used to stop a script that hasn’t yet done any writes. The complete information on methods to kill the script execution and related behavior are available in the documentation. Behavior on Sentinel-Monitored High Availability Systems.
Have you ever been on a website and noticed a popup notification that suggests that there is a new version of the site available? This is where a pop up notification like Google’s Inbox provides the user with a means of always having the latest version of cached resources. then(cache => cache.addAll([ './dog.jpg'
The other main use case was RENO, the Rapid Event Notification System mentioned above. Throughout this evolution, we’ve been able to maintain high availability and a consistent message delivery rate, with Pushy successfully maintaining 99.999% reliability for message delivery over the last few months.
However, there are a handful of ways available to us—some are, admittedly, more easy and free than others. If you want resources to load faster on high-latency connections, making them smaller is still a sensible idea, although file size typically correlates more with available bandwidth as file sizes increase.
Best of all, our page can load much faster since everything is cached in Elasticsearch. Luckily, we have Kafka events that are emitted each time a piece of data changes. The first step is to listen to those events and act accordingly. Keeping Everything Up To Date Indexing the data once isn’t enough.
And while these events are a great opportunity for us Dynatracers to share our thoughts with our users, it’s also an amazing opportunity to for us to learn from our users about how they use Dynatrace to optimize digital experiences and digital operations in both the public and private sector. Dynatrace news. APAC Series.
Lambda then takes a snapshot of the memory and disk state of the initialized execution environment, persists the encrypted snapshot, and caches it for low-latency access. Saving your cloud operations and site reliability engineering teams hours of guesswork and manual tagging, the Davis AI engine analyzes billions of events in real time.
Think of a session replay like a movie based on real events. These changes are known as “events,” and they occur any time a user interacts with your site or application, such as when they swipe the screen, move the mouse or input text. Streamlined asset caching: Asset caching is critical for creating accurate replays.
In databases like MySQL and PostgreSQL, transaction logs are the source of CDC events. In order to be supported, a database is required to fulfill a set of features that are commonly available in systems like MySQL, PostgreSQL, MariaDB, and others. Some of DBLog’s features are: Processes captured log events in-order.
In databases like MySQL and PostgreSQL, transaction logs are the source of CDC events. In order to be supported, a database is required to fulfill a set of features that are commonly available in systems like MySQL, PostgreSQL, MariaDB, and others. Some of DBLog’s features are: Processes captured log events in-order.
Examples include a spike in memory utilization, a decrease in cache hit ratio, or an increase in CPU utilization. Log entries describe events, such as starting a process, handling an error, or simply completing some part of a workload. DevOps practitioners struggle to maintain highly available and scalable applications.
Another example of a dataset that needs to be disseminated is the result of a machine-learning model: the results of these models may be used by several teams, but the ML teams behind the model aren’t necessarily interested in maintaining high-availability services in the critical path. it is meant purely for data versioning and propagation.
It provides a good read on the availability and latency ranges under different production conditions. In this approach, we record the requests and responses for the service that needs to be updated or replaced to an offline event stream asynchronously. It helps expose memory leaks, deadlocks, caching issues, and other system issues.
By adding Flutter support, we’re giving you more freedom to choose what best fits your use case and available resources. User actions in Dynatrace are more than just simple events. This flushes the cache on the Dynatrace Cluster; you should see events in the web UI shortly thereafter. What’s next.
This has been available since quite early on via the @next tag, but now it's officially released. You can now start executing a procedure on the server in a RSC, pick up the pending promise on the client, and automatically hydrate the React Query cache clientside. We recommend using this in the first instance going forward.
In the unlikely event that you don’t have access to the CSS file that contains the @import. We’re bound to an inefficient caching strategy: a change to, say, the background colour of the currently-selected day on a date picker used on only one page, would require that we cache-bust the entirety of app.css. in your HTML.
the order of the rows on your Netflix home page, issuing content licenses when you click play, finding the Open Connect cache closest to you with the content you requested, and many more). Security Events Platform See open source project such as StreamAlert and Siddhi to get some general ideas.
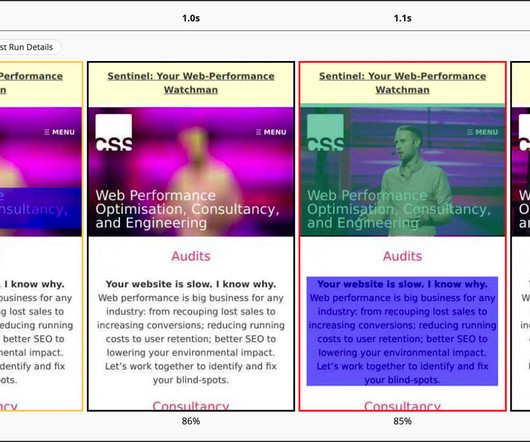
Notice below how our is momentarily considered our LCP candidate at 1.0s , before ultimately being replaced by the at 2.5s : Blue shading shows an LCP candidate; green shading and/or a red border shows the actual LCP element and event. we get our LCP event in full. What if Chrome finds a later element of the same size?
Effectively, the memory available for pages of the table gets less. The more indexes, the more the requirement of memory for effective caching. If we don’t increase the available memory, this starts hurting the entire performance of the system. Indexes like B-Tree indexes are known to cause more random writes.
The benefits of modeling data as events as a mechanism to evolve our software systems. Enter streams of events, specifically the kinds of streams that technology like Kafka makes possible. Continue reading Microservices, events, and upside-down databases. The concepts may well seem odd at first, but stick with them.
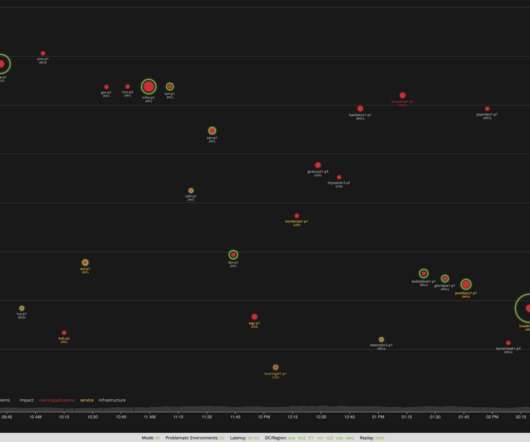
Figure 1 – Individual Host pages show performance metrics, problem history, event history, and related processes for each host. Missing caching layers. With the reliability pillar of the Well-Architected Framework, organizations must ensure they build resilient and available applications.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content