This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
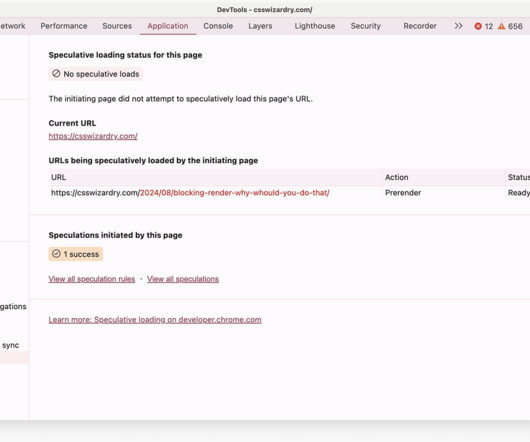
What is the availability, configurability, and efficacy of each? ?️ Caching them at the other end: How long should we cache files on a user’s device? Cache This is the easy one. Which brings me nicely on to… The important part of this section is cache busting. main.af8a22.css main.af8a22.css
For the longest time now, I have been obsessed with caching. I think every developer of any discipline would agree that caching is important, but I do tend to find that, particularly with web developers, gaps in knowledge leave a lot of opportunities for optimisation on the table. Want to know everything (and more) about HTTP cache?
Both categories share common requirements, such as high throughput and high availability. It allows users to choose between different counting modes, such as Best-Effort or Eventually Consistent , while considering the documented trade-offs of each option. Let’s take a closer look at the structure and functionality of the API.
The standard dictionary subscript notation is also available. Consider these examples from the updated documentation: You can choose the right level of runtime configurability versus fixed deployments by mixing Parameters and Configs. Take a look at two interesting examples of this pattern in the documentation.
Spring Boot 2 uses Micrometer as its default application metrics collector and automatically registers metrics for a wide variety of technologies, like JVM, CPU Usage, Spring MVC, and WebFlux request latencies, cache utilization, data source utilization, Rabbit MQ connection factories, and more. To learn more, see our documentation.
That trend will likely continue as Kubernetes security awareness further rises and a new class of security solutions becomes available. Of the organizations in the Kubernetes survey, 71% run databases and caches in Kubernetes, representing a +48% year-over-year increase. Databases : Among databases, Redis is the most used at 60%.
The RAG process begins by summarizing and converting user prompts into queries that are sent to a search platform that uses semantic similarities to find relevant data in vector databases, semantic caches, or other online data sources. Observing AI models Running AI models at scale can be resource-intensive.
Application example: user profile cache, where profiles are constructed elsewhere (e.g., All of these dbs are available free of cost for download / install and it will be fairly straightforward to run these tests in your environment for further analysis. Workload C: Read only. This workload is 100% read.
Performance Game Changer: Browser Back/Forward Cache. Performance Game Changer: Browser Back/Forward Cache. Plus, they’ve created some more transparency about this, both in documentation and tooling. All those navigations can benefit from the Back/Forward Cache to instantly restore the page. Barry Pollard.
AWS AppSync: AppSync offers a fully managed approach to developing APIs with GraphQL — connecting to AWS DynamoLB or Lambda along with adding caches and client-side data. Amazon S3: The Simple Storage Service stores and retrieves data from anywhere with scalability, data availability, security, performance, and a high degree of durability.
Browsers will cache tools popular among vocal, leading-edge developers. There's plenty of space for caching most popular frameworks. The best available proxy data also suggests that shared caches would have a minimal positive effect on performance. Suppose a user has only downloaded part of the cache.
If you must kill the script at this point, there are two options available: SCRIPT KILL command can be used to stop a script that hasn’t yet done any writes. The complete information on methods to kill the script execution and related behavior are available in the documentation. Any data written by the script will be lost.
Best of all, our page can load much faster since everything is cached in Elasticsearch. Once all documents have been indexed with no errors, we swap the alias from the currently active index to the newly built index. Keeping Everything Up To Date Indexing the data once isn’t enough. Our data changes constantly?—?
To make data count and to ensure cloud computing is unabated, companies and organizations must have highly available databases. This guide provides an overview of what high availability means, the components involved, how to measure high availability, and how to achieve it. How does high availability work?
and is constantly stopping and starting as different part of the document block it. We’re bound to an inefficient caching strategy: a change to, say, the background colour of the currently-selected day on a date picker used on only one page, would require that we cache-bust the entirety of app.css.
While web browsers and mobile phones have gigabytes of memory available for graphics, our devices are constrained to mere MBs. Our UI runs on top of a custom rendering engine which uses what we call a “surface cache” to optimize our use of graphics memory. The majority of legacy devices run at 28MB of surface cache.
Moreover, features like Instant Run and the Gradle Build Cache weren’t supported. Out-of-the-box support for Instant Run and the Gradle Build Cache make the auto-instrumentation process barely noticeable. All auto-instrumentation settings are available as Gradle configuration properties. Supportability.
The default storage engine in earlier versions was MMAPv1, which utilized memory-mapped files and document-level locking. However, it is limited by the available free memory amount, and all data is lost when the server stops. It uses a filesystem cache and write-ahead log for crash recovery.
There was no appetite from them to do so, so I decided to make it all available for free anyway—a faster web benefits everyone. To further exacerbate the problem, the 302 response has a Cache-Control: must-revalidate, private. There was no appetite for providing or even documenting the alternative (i.e. Closing Thoughts.
In practice, session recording solutions make use of the document object model (DOM), which is a programming interface for web pages and document. Streamlined asset caching: Asset caching is critical for creating accurate replays. Make sure you know what assets your replay tool is recording and how you can access them.
This allows the app to query a list of “paths” in each HTTP request, and get specially formatted JSON (jsonGraph) that we use to cache the data and hydrate the UI. You can find a lot more details about how this works in the Spinnaker canaries documentation. ecosystem and the rich selection of npm packages available.
Marken Architecture Our goal was to help teams at Netflix to create data pipelines without thinking about how that data is available to the readers or the client teams. We store all OperationIDs which are in STARTED state in a distributed cache (EVCache) for fast access during searches. They pass annotations along with the OperationID.
As I have talked about before, one of the reasons why we built Amazon DynamoDB was that Amazon was pushing the limits of what was a leading commercial database at the time and we were unable to sustain the availability, scalability, and performance needs that our growing Amazon.com business demanded. The opposite is true.
This has been available since quite early on via the @next tag, but now it's officially released. You can now start executing a procedure on the server in a RSC, pick up the pending promise on the client, and automatically hydrate the React Query cache clientside. You can read more in our Server Components documentation.
Spring Boot 2 uses Micrometer as its default application metrics collector and automatically registers metrics for a wide variety of technologies, like JVM, CPU Usage, Spring MVC, and WebFlux request latencies, cache utilization, data source utilization, Rabbit MQ connection factories, and more. To learn more, see our documentation.
Spring Boot 2 uses Micrometer as its default application metrics collector and automatically registers metrics for a wide variety of technologies, like JVM, CPU Usage, Spring MVC, and WebFlux request latencies, cache utilization, data source utilization, Rabbit MQ connection factories, and more. To learn more, see our documentation.
Even if a browser doesn't support WebP, our WebP caching feature will ensure that the correct image format is delivered. WebP delivery doesn't require any change on the origin server with the WebP caching feature. The available operations are listed in our documentation. Enable the Cache Key Host setting.
Microsoft word documents, spreadsheets, Google docs always rear their heads up when working with content authors. But where do they preview the content before it is made available to the general public? A preview feature must be available in the pricing plan you have chosen for the headless CMS of your choice. Content Previews.
However, storing and querying such data presents a unique set of challenges: High Throughput : Managing up to 10 million writes per second while maintaining high availability. The service extracts these fields from events as they stream in, indexing the resultant documents into Elasticsearch. Also, with Cassandra 4.x,
This allows resource requests, including the HTML document itself, to be enriched with data during its lifecycle, and that information can be inspected for measuring the attributes of that resource! For the top-level HTML document, it is fetched upon user navigation but is still a resource request.
The service workers enable the offline usage of the PWA by fetching cached data or informing the user about the absence of an Internet connection. When developing a PWA, you can cache the application shell’s resources and assets in the browser. Cached content with IndexedDB. Cache first, then network. Service Workers.
sec) However, we can still find a warning in the official documentation , even for the 8.1 version, like this: ANALYZE TABLE removes the table from the table definition cache, which requires a flush lock. This makes the query wait for any long-running queries to finish but also can trigger cascading waiting for other incoming requests.
The Four LCP Subparts LCP subparts split the Largest Contentful Paint metric into four different components: Time to First Byte (TTFB) : How quickly the server responds to the document request. Large preview ) Time To First Byte The first step to display the largest page element is fetching the document HTML. Sign up for a free trial.
ChatGPT: The InnoDB buffer pool is used by MySQL to cache frequently accessed data in memory. Since your dataset is 100 GB and you have 500 GB of RAM, you can allocate a significant portion of the available memory to the InnoDB buffer pool. So this answer was inaccurate and evasive. and moved my datadir to another location.
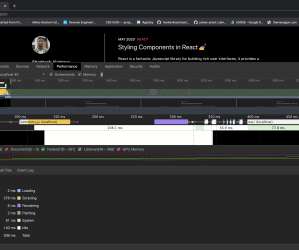
Instead, use the measurement tools available to analyze the performance of your React app and get a detailed report of what might be slowing it down. According to React’s documentation , in react-dom 16.5+ and react-native 0.57+, enhanced profiling capabilities are available in developer mode using React Developer Tools Profiler.
In order to be supported, a database is required to fulfill a set of features that are commonly available in systems like MySQL, PostgreSQL, MariaDB, and others. Designed with High Availability in mind. Providing high availability for real-time events. Some of DBLog’s features are: Processes captured log events in-order.
Now there’s a massive range of Jamstack CMSs available, which bring all the advantages of static sites while allowing non-technical folk to update content. What’s interesting is there was little mention of static sites in MoveableType’s documentation at all. These use cases include: Documentation. Large preview ).
When deciding what to pick, there are many things to consider, like where the proxy needs to be, if it “just” needs to redirect the connections, or if more features need to be in, like caching and filtering, or if it needs to be integrated with some MySQL embedded automation. Given that, there never was a single straight answer.
MB , that suggests I’ve got around 29 pages in my budget, although probably a few more than that if I’m able to stay on the same sites and leverage browser caching. There’s a trade-off to be made here, as external stylesheets can be cached but inline ones cannot (unless you get clever with JavaScript ). Let’s talk about caching.
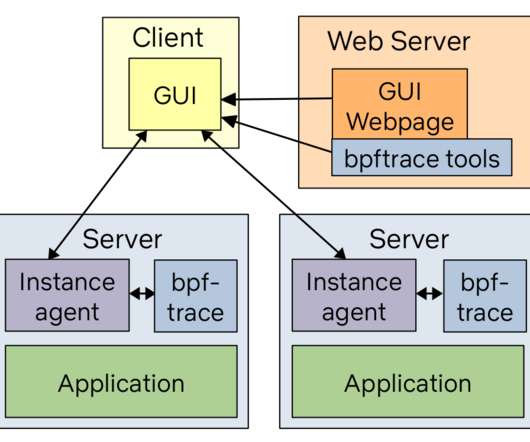
cachestat File system cache statistics line charts. There is already documentation as man pages and example files in the bcc and bpftrace repositories that you can link to, to help your customers understand the tool output. BPF didn't exist on those versions, so I used basic Ftrace capabilities that were available on Linux 3.2.
In order to be supported, a database is required to fulfill a set of features that are commonly available in systems like MySQL, PostgreSQL, MariaDB, and others. Designed with High Availability in mind. Providing high availability for real-time events. High Availability DBLog uses active-passive architecture. Figure 3?—?DBLog
The book PostgreSQL 14 Internals has been available in PDF format for quite a while, but recently, the ability to order a printed copy became available ( [link] ). This 548-page tome from PostgresPro covers the spectrum from data organization to details on the many available indexing options. Is this an easy read?
< p > The document is less than 600px wide. </ < p > The document is at least 600px wide. </ The browser has to run the JS that injects the HTML to the document, parse it and start requesting the referenced assets. This post is also available in Spanish Did you see any typo or wrong information?
The general idea is to cache and replay results, saving repeated executions of inner-side operators wherever possible. When a spool is able to replay cached results, this is known as a rewind. You may find it helpful to think of a spool rebind as a cache miss, and a rewind as a cache hit. Lazy Table Spool. Rule Matching.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content