This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
What is the availability, configurability, and efficacy of each? ?️ Caching them at the other end: How long should we cache files on a user’s device? Cache This is the easy one. Which brings me nicely on to… The important part of this section is cache busting. main.af8a22.css main.af8a22.css
By: Rajiv Shringi , Oleksii Tkachuk , Kartik Sathyanarayanan Introduction In our previous blog post, we introduced Netflix’s TimeSeries Abstraction , a distributed service designed to store and query large volumes of temporal event data with low millisecond latencies. Today, we’re excited to present the Distributed Counter Abstraction.
How To Design For High-Traffic Events And Prevent Your Website From Crashing How To Design For High-Traffic Events And Prevent Your Website From Crashing Saad Khan 2025-01-07T14:00:00+00:00 2025-01-07T22:04:48+00:00 This article is sponsored by Cloudways Product launches and sales typically attract large volumes of traffic.
We introduce a caching mechanism in the API gateway layer, allowing us to offload processing from singleton leader elected controllers without giving up strict data consistency and guarantees clients observe. The cache is kept in sync with the current leader process. How do I know that my cache is up to date? of the data.
These insights have shaped the design of our foundation model, enabling a transition from maintaining numerous small, specialized models to building a scalable, efficient system. At inference time, when multi-step decoding is needed, we can deploy KV caching to efficiently reuse past computations and maintain lowlatency.
This has been a guiding design principle with Metaflow since its inception. The standard dictionary subscript notation is also available. this could take a few minutes) All packages already cached in s3. All environments already cached in s3. You can access Configs of any past runs easily through the Client API.
The RAG process begins by summarizing and converting user prompts into queries that are sent to a search platform that uses semantic similarities to find relevant data in vector databases, semantic caches, or other online data sources. Observing AI models Running AI models at scale can be resource-intensive.
Users might already have the file cached. If website-a.com links to [link] , and a user goes from there to website-b.com who also links to [link] , then the user will already have that file in their cache. Penalty: Caching. This makes it very safe and sensible to enforce a reasonably aggressive cache policy.
Making Google’s CalDAV and CardDAV APIs available for everyone ( Google Developers Blog). Pandora launches new HTML5 site for TVs and gaming consoles, available now on PS3 and Xbox 360 ( The Next Web). Simpler UI Testing with CasperJS ( Architects Zone – Architectural Design Patterns & Best Practices). Hacker News).
Because microprocessors are so fast, computer architecture design has evolved towards adding various levels of caching between compute units and the main memory, in order to hide the latency of bringing the bits to the brains. This avoids thrashing caches too much for B and evens out the pressure on the L3 caches of the machine.
RTT is designed to replace Effective Connection Type (ECT) with higher resolution timing information. However, there are a handful of ways available to us—some are, admittedly, more easy and free than others. What follows is overall best-practice advice for designing with latency in mind. Where Does CrUX’s RTT Data Come From?
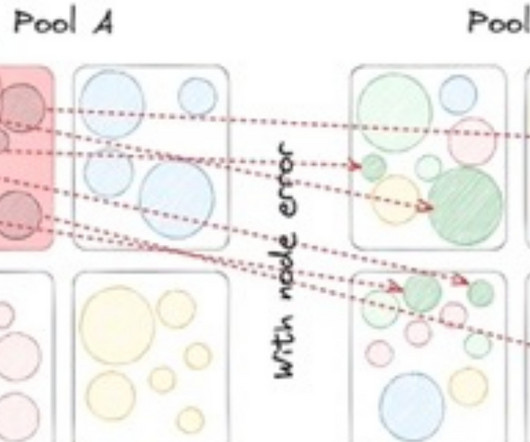
Central to this infrastructure is our use of multiple online distributed databases such as Apache Cassandra , a NoSQL database known for its high availability and scalability. Data Model At its core, the KV abstraction is built around a two-level map architecture. Developers just provide their data problem rather than a database solution!
Instead of worrying about infrastructure management functions, such as capacity provisioning and hardware maintenance, teams can focus on application design, deployment, and delivery. The first benefit is simplicity. But which are the best fit for your business, and where do they make the most sense in your serverless application stack?
Browsers will cache tools popular among vocal, leading-edge developers. There's plenty of space for caching most popular frameworks. The best available proxy data also suggests that shared caches would have a minimal positive effect on performance. Suppose a user has only downloaded part of the cache.
To make data count and to ensure cloud computing is unabated, companies and organizations must have highly available databases. This guide provides an overview of what high availability means, the components involved, how to measure high availability, and how to achieve it. How does high availability work?
This would also mean I need a service that detects any new environments, creates API tokens for them, refreshes API tokens on expiry and ensures that there is always a valid API token available. I wanted a rather lightweight design that is yet versatile. These parameters are then combined into the cache key to query the TenantCache.
RevenueCat extensively uses caching to improve the availability and performance of its product API while ensuring consistency. The company shared its techniques to deliver the platform, which can handle over 1.2 billion daily API requests. By Rafal Gancarz
Performance Game Changer: Browser Back/Forward Cache. Performance Game Changer: Browser Back/Forward Cache. With that caveat out of the way, let’s get to the guts of the article: What is the Back/Forward Cache and why does it matter so much? Didn’t The HTTP Cache Do All That Anyway? Barry Pollard.
Options at each level offer significant potential benefits, especially when complemented by practices that influence the design and purchase decisions made by IT leaders and individual contributors. Implement appropriate caching layers (for example, read-only cache for static data). Reduce inter-process communications overhead.
Application example: user profile cache, where profiles are constructed elsewhere (e.g., All of these dbs are available free of cost for download / install and it will be fairly straightforward to run these tests in your environment for further analysis. Workload C: Read only. This workload is 100% read. Conclusion.
The goal of this experience from a UX design perspective was to bring together a tightly-related set of original titles that, though distinct entities on their own, also share a connected universe. We hypothesized this design would net a far greater visual impact than if the titles were distributed individually throughout the page.
We also couldn’t compromise on performance and availability.” Such testing is critical to identifying customer shopping patterns that inform decisions about application design and user experience. . “Over the last few years, the priorities have shifted with the ways consumers are shopping,” he said.
Applications that rely heavily on a data-store usually can benefit greatly from using the Cache-Aside Pattern. If used correctly, this pattern can improve performance and help maintain consistency between the cache and the underlying data store. This post is part of a Design Patterns series. Lifetime of Cached Data.
Since its inception , Metaflow has been designed to provide a human-friendly API for building data and ML (and today AI) applications and deploying them in our production infrastructure frictionlessly. Deployment: Cache To produce business value, all our Metaflow projects are deployed to work with other production systems.
This allows the app to query a list of “paths” in each HTTP request, and get specially formatted JSON (jsonGraph) that we use to cache the data and hydrate the UI. ecosystem and the rich selection of npm packages available. video titles, descriptions) could be aggressively cached and reused across multiple requests.
Choosing your database architecture may be the most critical decision you’ll make and has a disproportionate impact on the performance, scalability, and availability of your app. Get it right and your application will seamlessly scale from hundreds to tens of millions of users without difficulty, while remaining performant and available.
AWS AWS provides a suite of services that a VFX studio, regardless of size, can use to leverage the cloud, including AWS Thinkbox Deadline , Amazon File Cache , and Render Farm Deployment Kit on AWS (RFDK). via direct plug-ins, and is available on multi-cloud platform services. including AWS Thinkbox Deadline and Pixar’s Tractor.
For these, it’s important to turn off auto-completing forms, encrypt data both in transit and at rest with up-to-date encryption techniques, and disable caching on data collection forms. Use a safe development life cycle with secure design patterns and components. Apply threat modeling and plausibility checks.
What Web Designers Can Do To Speed Up Mobile Websites. What Web Designers Can Do To Speed Up Mobile Websites. I recently wrote a blog post for a web designer client about page speed and why it matters. However, their focus has always been on making a great-looking and effective design. Suzanne Scacca. Minification.
Another example of a dataset that needs to be disseminated is the result of a machine-learning model: the results of these models may be used by several teams, but the ML teams behind the model aren’t necessarily interested in maintaining high-availability services in the critical path. for example to train machine-learned models.
To support this growth, we’ve revisited Pushy’s past assumptions and design decisions with an eye towards both Pushy’s future role and future stability. This also enables things like subscribing to device events to know when another device comes online and when they’re available to pair or send a message to.
This is a set of best practices and guidelines that help you design and operate reliable, secure, efficient, cost-effective, and sustainable systems in the cloud. Storing frequently accessed data in faster storage, usually in-memory caching, improves data retrieval speed and overall system performance. Beyond
Query caching Pgpool-II can cache frequently used queries in memory, reducing the load on your PostgreSQL servers and improving response times. This means that when a query is executed, pgpool-II can check the cache first to see if the results are already available rather than sending the query to the database server.
console.log("I will not run until slow-loading-stylesheet.css is downloaded."); This is by design. We’re bound to an inefficient caching strategy: a change to, say, the background colour of the currently-selected day on a date picker used on only one page, would require that we cache-bust the entirety of app.css.
Key Takeaways Redis offers complex data structures and additional features for versatile data handling, while Memcached excels in simplicity with a fast, multi-threaded architecture for basic caching needs. Redis is better suited for complex data models, and Memcached is better suited for high-throughput, string-based caching scenarios.
The Azure Well-Architected Framework is a set of guiding tenets organizations can use to evaluate architecture and implement designs that will scale over time. Design efficient use of your computing resources as demand changes and technologies evolves. Missing caching layers. What is the Azure Well-Architected Framework?
Building on these foundational abstractions, we developed the TimeSeries Abstraction — a versatile and scalable solution designed to efficiently store and query large volumes of temporal event data with low millisecond latencies, all in a cost-effective manner across various use cases.
Designing far memory data structures: think outside the box Aguilera et al., Far memory brings many potential benefits over near memory: higher memory capacity through disaggregation, separate scaling between processing and far memory, better availability due to separate fault domains for far memory, and better shareability among processors.
Conversely, if users encounter functional issues or poor UI design that frustrate common actions, replays provide clear evidence. Streamlined asset caching: Asset caching is critical for creating accurate replays. However, session recordings provide much-needed context for resolution.
There was no appetite from them to do so, so I decided to make it all available for free anyway—a faster web benefits everyone. To further exacerbate the problem, the 302 response has a Cache-Control: must-revalidate, private. All of the people I have dealt with seem like really, really nice folk. That’s approximately $15.5m
We designed a unique concept called Annotation Operations which allows teams to create data pipelines and easily write annotations without worrying about access patterns of their data from different applications. We store all OperationIDs which are in STARTED state in a distributed cache (EVCache) for fast access during searches.
Today AWS has launched Amazon ElastiCache , a new service that makes it easy to add distributed in-memory caching to any application. Amazon ElastiCache handles the complexity of creating, scaling and managing an in-memory cache to free up brainpower for more differentiating activities. blog comments powered by Disqus. Contact Info.
Effective management of memory stores with policies like LRU/LFU proactive monitoring of the replication process and advanced metrics such as cache hit ratio and persistence indicators are crucial for ensuring data integrity and optimizing Redis’s performance. offers the Software Watchdog specifically designed for this purpose.
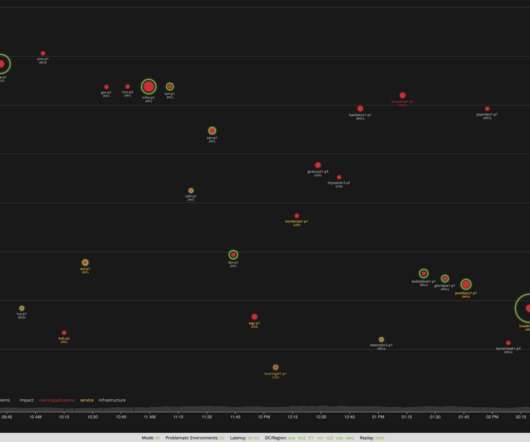
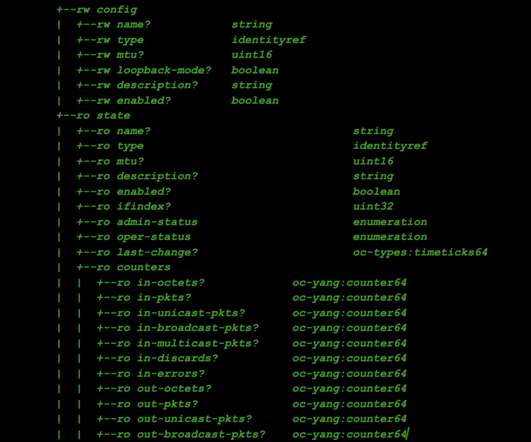
Introducing gnmi-gateway: a modular, distributed, and highly available service for modern network telemetry via OpenConfig and gNMI By: Colin McIntosh, Michael Costello Netflix runs its own content delivery network, Open Connect , which delivers all streaming traffic to our members. The Gateway To fill these gaps?—?under
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content