This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
These developments gradually highlight a system of relevant database building blocks with proven practical efficiency. In this article I’m trying to provide more or less systematic description of techniques related to distributed operations in NoSQL databases. Data Placement. System Coordination. Read/Write latency. Fault-tolerance.
To make data count and to ensure cloud computing is unabated, companies and organizations must have highly availabledatabases. This guide provides an overview of what high availability means, the components involved, how to measure high availability, and how to achieve it.
The good news is that you can maximize availability and prevent website crashes by designing websites specifically for these events. There are also online optimization tools available like Tinify , as well as advanced image editing software like Photoshop or GIMP : Image format is also a key consideration. Lets jump right in!
The strongest Kubernetes growth areas are security, databases, and CI/CD technologies. Strongest Kubernetes growth areas are security, databases, and CI/CD technologies. That trend will likely continue as Kubernetes security awareness further rises and a new class of security solutions becomes available. Java, Go, and Node.js
With OneAgent installed on an application server, Davis, the Dynatrace AI causation engine, continuously analyzes all database statements within the context of your applications. Now, with Oracle database insights, we’re going even deeper, giving you visibility into what’s going on in the database layer.
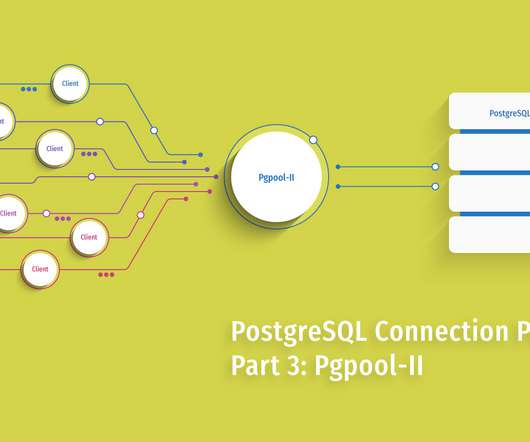
It supports high-availability, provides automated load balancing, and has the intelligence to balance load between masters and slaves so write loads are always directed at masters, while read loads are directed to slaves. The Pgpool-II parent process forks 32 child processes by default – these are available for connection.
The RAG process begins by summarizing and converting user prompts into queries that are sent to a search platform that uses semantic similarities to find relevant data in vector databases, semantic caches, or other online data sources. Observing AI models Running AI models at scale can be resource-intensive.
As part of the Platform Extensions team, I’m one of those responsible for services that include the Dynatrace OneAgent SDKs, which are libraries that allow us to extend end-to-end visibility for technologies and frameworks for which there is no code module available yet. Database calls. The sqllite database. Messaging calls.
This article is to simply report the YCSB bench test results in detail for five NoSQL databases namely Redis, MongoDB, Couchbase, Yugabyte and BangDB and compare the result side by side. I have used latest versions for each NoSQL DB and have followed the recommendations to run all the databases in optimized conditions. Load and 2.
Ruchir Jha , Brian Harrington , Yingwu Zhao TL;DR Streaming alert evaluation scales much better than the traditional approach of polling time-series databases. It allows us to overcome high dimensionality/cardinality limitations of the time-series database. It opens doors to support more exciting use-cases.
a Fast and Scalable NoSQL Database Service Designed for Internet Scale Applications. Today is a very exciting day as we release Amazon DynamoDB , a fast, highly reliable and cost-effective NoSQL database service designed for internet scale applications. Werner Vogels weblog on building scalable and robust distributed systems.
Central to this infrastructure is our use of multiple online distributed databases such as Apache Cassandra , a NoSQL database known for its high availability and scalability. Over time as new key-value databases were introduced and service owners launched new use cases, we encountered numerous challenges with datastore misuse.
If you must kill the script at this point, there are two options available: SCRIPT KILL command can be used to stop a script that hasn’t yet done any writes. The complete information on methods to kill the script execution and related behavior are available in the documentation. Behavior on Sentinel-Monitored High Availability Systems.
A common question that I get is why do we offer so many database products? To do this, they need to be able to use multiple databases and data models within the same application. Seldom can one database fit the needs of multiple distinct use cases. Seldom can one database fit the needs of multiple distinct use cases.
Where you decide to host your cloud databases is a huge decision. But, if you’re considering leveraging a managed databases provider, you have another decision to make – are you able to host in your own cloud account or are you required to host through your managed service provider? Where to host your cloud database?
This translates to a large number of app configurations to toggle feature availability and optimize the in-app experience for each production. For our use-case, we’re configuring the availability of production, version, and region specific app feature sets.
This means you no longer have to provision, scale, and maintain servers to run your applications, databases, and storage systems. AWS AppSync: AppSync offers a fully managed approach to developing APIs with GraphQL — connecting to AWS DynamoLB or Lambda along with adding caches and client-side data. Data Store.
I am excited to share with you that today we are expanding DynamoDB with streams, cross-region replication, and database triggers. Streams provide you with the underlying infrastructure to create new applications, such as continuously updated free-text search indexes, caches, or other creative extensions requiring up-to-date table changes.
October 2, 2019 – ScaleGrid, a rapidly growing leader in the Database-as-a-Service (DBaaS) space, has just launched their new fully managed Redis on Azure service. Redis, the #1 key-value store and top 10 database in the world, has grown by over 300% in popularity over that past 5 years, per the DB-Engines knowledge base.
Infrastructure Optimization: 100% improvement in Database Connectivity. We have several YouTube Tutorials and blog posts available that show how you can use Dynatrace RUM data for Web Performance & User Experience Optimization. Digital Performance: 99% reduction in Response Time, from 18.2s Impressive results I have to say!
Apache Cassandra is an open-source, distributed, NoSQL database. Because of its scalability and distributed architecture, thousands of companies trust it to run their cloud and hybrid-based workloads at high availability without compromising performance. Microsoft Azure offers multiple ways to manage Apache Cassandra databases.
We also couldn’t compromise on performance and availability.” “Caching’s one of the key components of any commerce application,” as it has a major impact on performance, Bollampally said. . “Over the last few years, the priorities have shifted with the ways consumers are shopping,” he said.
Heading into 2024, SQL databases will remain essential in data management, increasingly using distributed systems to meet growing needs for scalability and reliability. According to 2023 statistics, 49% of web applications use an SQL-based database , with SQL having a 75% adoption rate in the IT industry.
RevenueCat extensively uses caching to improve the availability and performance of its product API while ensuring consistency. The company shared its techniques to deliver the platform, which can handle over 1.2 billion daily API requests. By Rafal Gancarz
Reduce the volume of data volumes requested from databases (for example, request all, filter in memory). Implement appropriate caching layers (for example, read-only cache for static data). A few examples: Reduce roundtrips between services (for example, the N+1 query pattern). Reduce inter-process communications overhead.
For example, when monitoring a database, you’ll want to know about any latency when writing data to a disk or average query response time. Experienced database administrators learn to spot patterns that can lead to common problems. DevOps practitioners struggle to maintain highly available and scalable applications.
October 2, 2019 – ScaleGrid, a rapidly growing leader in the Database-as-a-Service (DBaaS) space, has just launched their new fully managed Hosting on Azure for Redis™ service. Redis™, the #1 key-value store and top 10 database in the world, has grown by over 300% in popularity over that past 5 years, per the DB-Engines knowledge base.
Specifically, how our team uses the relationships and schemas defined within GraphQL to automatically build and maintain a search database. Each service could potentially implement its own search database, but then we would still need an aggregator. Best of all, our page can load much faster since everything is cached in Elasticsearch.
Today, we added two important choices for customers running high performance apps in the cloud: support for Redis in Amazon ElastiCache and a new high memory database instance (db.cr1.8xlarge) for Amazon RDS. No single database architecture or solution can meet all of Amazon.com’s or our customers’ needs.
PostgreSQL is a popular open source relational database management system many organizations use to store and manage their data. However, as the size of your database grows, it can become challenging to manage and optimize its performance. This can significantly improve query response times and reduce the load on your database servers.
only to find that the resource they’re requesting isn’t in that PoP ’s cache. Database queries: Pages that require data from a database will incur a cost when searching over it. This is exactly what we did at BBC iPlayer last year: The newly-available Server-Timing header can be added to any response.
Andreas Andreakis , Ioannis Papapanagiotou Overview Change-Data-Capture (CDC) allows capturing committed changes from a database in real-time and propagating those changes to downstream consumers [1][2]. In databases like MySQL and PostgreSQL, transaction logs are the source of CDC events. Designed with High Availability in mind.
version, like this: ANALYZE TABLE removes the table from the table definition cache, which requires a flush lock. This makes the query wait for any long-running queries to finish but also can trigger cascading waiting for other incoming requests. In short, ANALYZE could lead to nasty stalls in busy production environments. x are all safe.
There are many naive solutions possible for this problem for example: Write different runs in different databases. Instead our challenge was to implement this feature on top of Cassandra and ElasticSearch databases because that’s what Marken uses. This is obviously very expensive. Write algo runs into files.
Andreas Andreakis , Ioannis Papapanagiotou Overview Change-Data-Capture (CDC) allows capturing committed changes from a database in real-time and propagating those changes to downstream consumers [1][2]. In databases like MySQL and PostgreSQL, transaction logs are the source of CDC events. Designed with High Availability in mind.
I’ve used a fourth instance to host a PMM server to monitor servers A and B and used the data collected by the PMM agents installed on the database servers to compare performance. MySQL comes pre-configured to be conservative instead of making the most of the resources available in the server. Why is that?
Key Takeaways Redis offers complex data structures and additional features for versatile data handling, while Memcached excels in simplicity with a fast, multi-threaded architecture for basic caching needs. Redis is better suited for complex data models, and Memcached is better suited for high-throughput, string-based caching scenarios.
ScaleGrid, a rapidly growing leader in the Database-as-a-Service (DBaaS) space, has just launched their new fully managed Redis on Azure service. Redis, the #1 key-value store and top 10 database in the world, has grown by over 300% in popularity over that past 5 years, per the DB-Engines knowledge base.
In the world of databases, data management, and data platforms, this entropy usually takes the form of a simple database or data platform that might be ideal for early use cases evolving (or rather, de volving) into an expensive and unmanageable nightmare due to operational strain from use-case gluttony. How hard can it be?
It has default settings for all of the database parameters. It is primarily the responsibility of the database administrator or developer to tune PostgreSQL according to their system’s workload. It is important to pay attention to performance when writing database queries. PostgreSQL’s Tuneable Parameters. shared_buffer.
WiredTiger excels with operational databases and transactional workloads as it offers b-tree-based storage and well-ordered data structures. However, it is limited by the available free memory amount, and all data is lost when the server stops. It uses a filesystem cache and write-ahead log for crash recovery.
For these, it’s important to turn off auto-completing forms, encrypt data both in transit and at rest with up-to-date encryption techniques, and disable caching on data collection forms. Numerous organizations offer databases of these weaknesses, such as the Snyk Intel Vulnerability Database.
Redis® is an in-memory database that provides blazingly fast performance. This makes it a compelling alternative to disk-based databases when performance is a concern. Redis returns a big list of database metrics when you run the info command on the Redis shell. This blog post lists the important database metrics to monitor.
This post is about PostgreSQL, but most of the problems also apply to other database systems. Effectively, the memory available for pages of the table gets less. The more indexes, the more the requirement of memory for effective caching. Cache requirements for indexes are generally much higher than associated tables.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content