This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
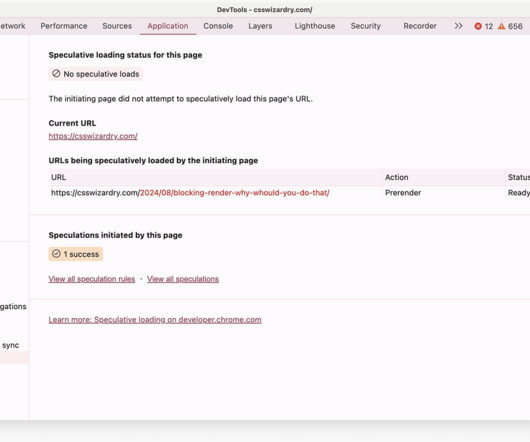
What is the availability, configurability, and efficacy of each? ?️ Caching them at the other end: How long should we cache files on a user’s device? This is because, at present, algorithms like Gzip and Brotli become more effective the more historical data they have to play with. Cache This is the easy one.
By: Rajiv Shringi , Oleksii Tkachuk , Kartik Sathyanarayanan Introduction In our previous blog post, we introduced Netflix’s TimeSeries Abstraction , a distributed service designed to store and query large volumes of temporal event data with low millisecond latencies. Today, we’re excited to present the Distributed Counter Abstraction.
Caching is the process of storing frequently accessed data or resources in a temporary storage location, such as memory or disk, to improve retrieval speed and reduce the need for repetitive processing.
We introduce a caching mechanism in the API gateway layer, allowing us to offload processing from singleton leader elected controllers without giving up strict data consistency and guarantees clients observe. Active data includes jobs and tasks that are currently running. Titus Gateway handles user requests.
For the longest time now, I have been obsessed with caching. I think every developer of any discipline would agree that caching is important, but I do tend to find that, particularly with web developers, gaps in knowledge leave a lot of opportunities for optimisation on the table. Want to know everything (and more) about HTTP cache?
If you work in customer support for any kind of tech firm, you’re probably all too used to talking people through the intricate, tedious steps of clearing their cache and clearing their cookies. set ( ' Clear-Site-Data ' , ' cache ' ); } else { res. Well, there’s an easier way! status ( 403 ). Tread carefully!
Central to this infrastructure is our use of multiple online distributed databases such as Apache Cassandra , a NoSQL database known for its high availability and scalability. Second, developers had to constantly re-learn new data modeling practices and common yet critical data access patterns.
These media focused machine learning algorithms as well as other teams generate a lot of data from the media files, which we described in our previous blog , are stored as annotations in Marken. Similarly, client teams don’t have to worry about when or how the data is written. in a video file.
At Netflix, we periodically reevaluate our workloads to optimize utilization of available capacity. We also see much higher L1 cache activity combined with 4x higher count of MACHINE_CLEARS. a usage pattern occurring when 2 cores reading from / writing to unrelated variables that happen to share the same L1 cache line.
Rajiv Shringi Vinay Chella Kaidan Fullerton Oleksii Tkachuk Joey Lynch Introduction As Netflix continues to expand and diversify into various sectors like Video on Demand and Gaming , the ability to ingest and store vast amounts of temporal data — often reaching petabytes — with millisecond access latency has become increasingly vital.
Frequently, practitioners want to experiment with variants of these flows, testing new data, new parameterizations, or new algorithms, while keeping the overall structure of the flow or flowsintact. The standard dictionary subscript notation is also available. This has been a guiding design principle with Metaflow since its inception.
Furthermore, it was difficult to transfer innovations from one model to another, given that most are independently trained despite using common data sources. Key insights from this shiftinclude: A Data-Centric Approach : Shifting focus from model-centric strategies, which heavily rely on feature engineering, to a data-centric one.
Andreas Andreakis , Ioannis Papapanagiotou Overview Change-Data-Capture (CDC) allows capturing committed changes from a database in real-time and propagating those changes to downstream consumers [1][2]. Designed with High Availability in mind. This is crucial for repairs downstream when data has been lost or corrupted.
This blog post explores how AI observability enables organizations to predict and control costs, performance, and data reliability. It also shows how data observability relates to business outcomes as organizations embrace generative AI. GenAI is prone to erratic behavior due to unforeseen data scenarios or underlying system issues.
The study analyzes factual Kubernetes production data from thousands of organizations worldwide that are using the Dynatrace Software Intelligence Platform to keep their Kubernetes clusters secure, healthy, and high performing. Big data : To store, search, and analyze large datasets, 32% of organizations use Elasticsearch.
The GraphQL shim enabled client engineers to move quickly onto GraphQL, figure out client-side concerns like cache normalization, experiment with different GraphQL clients, and investigate client performance without being blocked by server-side migrations. In such cases, we were not testing for response data but overall behavior.
Andreas Andreakis , Ioannis Papapanagiotou Overview Change-Data-Capture (CDC) allows capturing committed changes from a database in real-time and propagating those changes to downstream consumers [1][2]. Designed with High Availability in mind. This is crucial for repairs downstream when data has been lost or corrupted.
Because microprocessors are so fast, computer architecture design has evolved towards adding various levels of caching between compute units and the main memory, in order to hide the latency of bringing the bits to the brains. This avoids thrashing caches too much for B and evens out the pressure on the L3 caches of the machine.
One of these solutions is Micrometer which provides 17+ pre-instrumented JVM-based frameworks for data collection and enables instrumentation code with a vendor-neutral API. That’s a large amount of data to handle. This creates a lot of complexity given different data sources, components, and tools. of Micrometer.
the order of the rows on your Netflix home page, issuing content licenses when you click play, finding the Open Connect cache closest to you with the content you requested, and many more). In the Reliability space, our data teams focus on two main approaches. All these micro-services are currently operated in AWS cloud infrastructure.
Last week, I posted a short update on LinkedIn about CrUX’s new RTT data. Chrome have recently begun adding Round-Trip-Time (RTT) data to the Chrome User Experience Report (CrUX). Where Does CrUX’s RTT Data Come From? RTT data should be seen as an insight and not a metric. RTT isn’t a you-thing, it’s a them-thing.
As part of the Platform Extensions team, I’m one of those responsible for services that include the Dynatrace OneAgent SDKs, which are libraries that allow us to extend end-to-end visibility for technologies and frameworks for which there is no code module available yet. Instrument key portions of your application. Web Requests entry points.
Atlas is an in-memory time-series database that ingests multiple billions of time-series per day and retains the last two weeks of data. Moreover, common database optimizations like caching recently queried data don’t really work for alerting queries because, generally speaking, the last received datapoint is required for correctness.
In my previous post , I reviewed historical data on single-core/single-thread memory bandwidth in multicore processors from Intel and AMD from 2010 to the present. “Concurrency” is the amount of data that must be “in flight” between the core and the memory in order to maintain a steady-state system. .
This translates to a large number of app configurations to toggle feature availability and optimize the in-app experience for each production. These expressions are evaluated in the current app session context, and can access data such as A/B test assignments, locality, device attributes, etc.
Browsers will cache tools popular among vocal, leading-edge developers. There's plenty of space for caching most popular frameworks. The best available proxy data also suggests that shared caches would have a minimal positive effect on performance. Suppose a user has only downloaded part of the cache.
Performance Game Changer: Browser Back/Forward Cache. Performance Game Changer: Browser Back/Forward Cache. With that caveat out of the way, let’s get to the guts of the article: What is the Back/Forward Cache and why does it matter so much? Didn’t The HTTP Cache Do All That Anyway? Barry Pollard.
To make data count and to ensure cloud computing is unabated, companies and organizations must have highly available databases. This guide provides an overview of what high availability means, the components involved, how to measure high availability, and how to achieve it. More in the following sub-section.)
Growing awareness and increasing regulatory scrutiny have propelled carbon emissions data into the public consciousness. Evaluating these on three levels—data center, host, and application architecture (plus code)—is helpful. Level 1: Data centers This is the starting point for most organizations. A PUE of 1.0
Berg , Romain Cledat , Kayla Seeley , Shashank Srikanth , Chaoying Wang , Darin Yu Netflix uses data science and machine learning across all facets of the company, powering a wide range of business applications from our internal infrastructure and content demand modeling to media understanding.
This is guest post by Sachin Sinha who is passionate about data, analytics and machine learning at scale. Load stage is to load the data and then run stage we run the test. Load is consistent for all dbs for all tests as expected as this phase is to load the data. Author & founder of BangDB. Workload C: Read only.
Gatekeeper accomplishes its prescribed task by aggregating data from multiple upstream systems, applying some business logic, then producing an output detailing the status of each video in each country. there is no eviction policy, and there are no cache misses. there is no eviction policy, and there are no cache misses.
I wanted to leverage Dynatrace’s Environment APIs, for example to export timeseries data, get problem stats, or change configuration settings, like enforcing a certain data privacy setting. TenantCache: a cache to store tenant information and API token information and semi-permanent data to avoid unnecessary roundtrips. ?
If you must kill the script at this point, there are two options available: SCRIPT KILL command can be used to stop a script that hasn’t yet done any writes. The complete information on methods to kill the script execution and related behavior are available in the documentation. Behavior on Sentinel-Monitored High Availability Systems.
Amazon EventBridge: EventBridge to bridges the data gap between your applications and other services, such as Lambda or specific SaaS apps. Users control where their data goes in real-time, making it possible to create app architectures that respond to data sources on demand. Data Store. Improving data processing.
Because of its scalability and distributed architecture, thousands of companies trust it to run their cloud and hybrid-based workloads at high availability without compromising performance. From there, you can dive deeper into infrastructure metrics (cluster, datacenter, racks, and nodes) and data metrics (keyspaces and tables).
We have several YouTube Tutorials and blog posts available that show how you can use Dynatrace RUM data for Web Performance & User Experience Optimization. Missing Cache Settings – Make sure you cache resources that don’t change often on the browser or use a CDN. Digital Performance improvement.
And according to recent data from Enterprise Strategy Group, 59% of survey respondents indicated spending on public cloud applications would increase in 2023. We also couldn’t compromise on performance and availability.” “We can analyze the data from those services in context.”
This allowed Android engineers to have much more control and observability over how we get our data. Background The Netflix Android app uses the falcor data model and query protocol. For example, the artwork service is separate from the video metadata service, but we need the data from both in the detail key.
Logging provides additional data but is typically viewed in isolation of a broader system context. Observability is the ability to understand a system’s internal state by analyzing the data it generates, such as logs, metrics, and traces. Monitoring typically provides a limited view of system data focused on individual metrics.
The shortcomings and drawbacks of batch-oriented data processing were widely recognized by the Big Data community quite a long time ago. This system has been designed to supplement and succeed the existing Hadoop-based system that had too high latency of data processing and too high maintenance costs.
It can happen on an edge API system servicing customer devices, between the edge and mid-tier services, or from mid-tiers to data stores. It provides a good read on the availability and latency ranges under different production conditions. For instance, envision a response payload that delivers media streams for a playback session.
OpenTelemetry, the open source observability tool, has emerged as an industry-standard solution for instrumenting application telemetry data to make it observable. OpenTelemetry then renders those connection details—such as connect, send, and receive times, connection status, and transmitted data size—back to the client.
These workflows also utilize Davis® , the Dynatrace causal AI engine, and all your observability and security data across all platforms, in context, at scale, and in real-time. Storing frequently accessed data in faster storage, usually in-memory caching, improves data retrieval speed and overall system performance. Beyond
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content