This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Without SRE bestpractices, the observability landscape is too complex for any single organization to manage. Like any evolving discipline, it is characterized by a lack of commonly accepted practices and tools. In a talent-constrained market, the best strategy could be to develop expertise from within the organization.
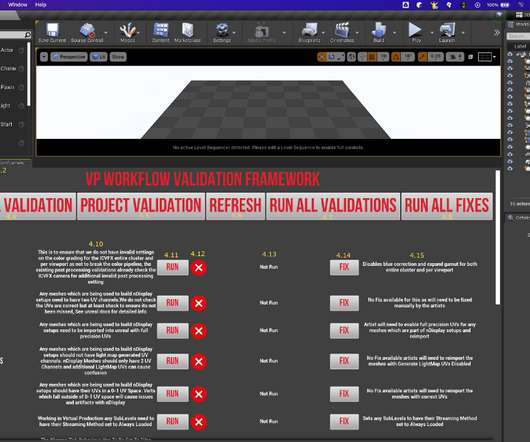
Virtual Production?—?A A Validation Framework For Unreal Engine By Adam Davis, Jimmy Fusil, Bhanu Srikanth and Girish Balakrishnan Game Engines in Virtual Production The use of Virtual Production and real time technologies has markedly accelerated in the past few years.
With over 80% of workloads worldwide virtualized, virtualization security is a concern for organizations regardless of size, goal, and industry. Proper protection systems for a particular organization's workloads and data are necessary to support production and service availability. In this post, we explain:
While selecting a Kubernetes segment, the selector provides a dynamic list of available resources. Segments can implement variables to dynamically provide, for example, a list of entities to users, such as available Kubernetes clusters, for unmatched flexibility and dynamic segmentation. What are Dynatrace Segments? Figure 4.
With more organizations taking the multicloud plunge, monitoring cloud infrastructure is critical to ensure all components of the cloud computing stack are available, high-performing, and secure. Cloud monitoring is a set of solutions and practices used to observe, measure, analyze, and manage the health of cloud-based IT infrastructure.
Query your data with natural language Davis CoPilot is an excellent virtual assistant that helps you create queries using natural language. While the Explore interface is useful for quickly visualizing known metrics, Davis CoPilot is great for exploring your data when you know your desired outcome but are unfamiliar with the available data.
These organizations rely heavily on performance, availability, and user satisfaction to drive sales and retain customers. AvailabilityAvailability SLO quantifies the expected level of service availability over a specific time period. Availability is typically expressed in 9’s, such as 99.9%. or 99.99% of the time.
Dynatrace support for AWS Data Firehose includes AWS Lambda logs, Amazon Virtual Private Cloud (VPC) flow logs, Amazon S3 logs, and Amazon CloudWatch. In addition, ready-made dashboards are available for a quick and easy overview, allowing you to see the Kubernetes data you want alongside the observability data you need, all in one place.
Cloud providers then manage physical hardware, virtual machines, and web server software management. Increased availability. Because FaaS is a cloud-native approach, it makes great use of multisite cloud architecture to improve availability and reliability. Functional FaaS bestpractices.
This transition to public, private, and hybrid cloud is driving organizations to automate and virtualize IT operations to lower costs and optimize cloud processes and systems. Besides the traditional system hardware, storage, routers, and software, ITOps also includes virtual components of the network and cloud infrastructure.
To make data count and to ensure cloud computing is unabated, companies and organizations must have highly available databases. This guide provides an overview of what high availability means, the components involved, how to measure high availability, and how to achieve it. How does high availability work?
Getting precise root cause analysis when dealing with several layers of virtualization in a containerized world. The Framework is built on five pillars of architectural bestpractices: Cost optimization. Analyzing user experience to ensure uniform performance after migration. Operational excellence. Performance efficiency.
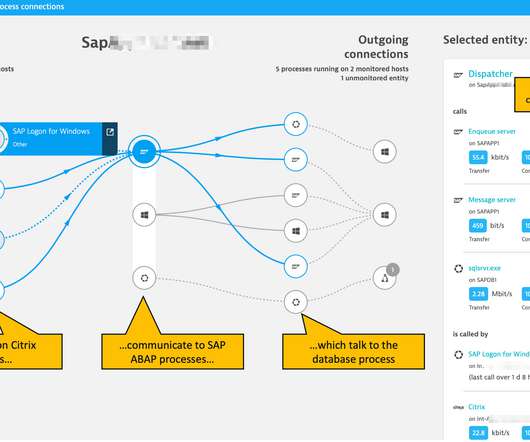
Having released this functionality in a Preview Release back in May 2019, we’re now happy to announce the General Availability of our SAP ABAP monitoring extension. Vertical infrastructure dependencies characterize how SAP depends on virtual and physical infrastructure performance. Dynatrace news.
Host analysis focuses on operating systems, virtual machines, and containers to understand if there are software components with known vulnerabilities that can be patched. This is done by scanning targets such as application code, network infrastructure, or virtual machines. Identify vulnerabilities. Analyze findings.
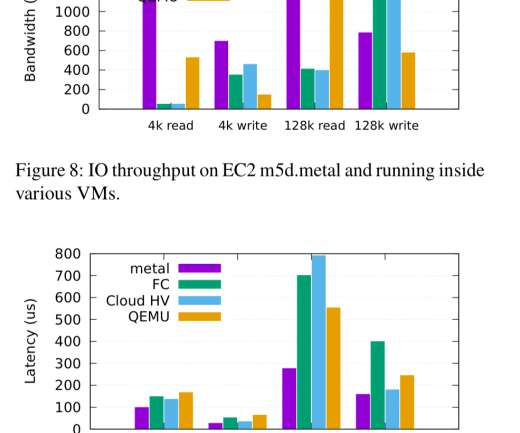
We looked at a couple of papers that had pre-prints available last week, today we’ll be looking at one of the most anticipated papers of this year’s crop: Amazon’s Firecracker. Firecracker is the virtual machine monitor (VMM) that powers AWS Lambda and AWS Fargate, and has been used in production at AWS since 2018.
Site reliability engineering (SRE) is the practice of applying software engineering principles to operations and infrastructure processes to help organizations create highly reliable and scalable software systems. ” According to Google, “SRE is what you get when you treat operations as a software problem.” Solving for SR.
When it comes to access to their applications, users demand instant, reliable, and secure interactions — and that means databases must be highly available. With database high availability (HA), services are largely uninterrupted, and end users are largely satisfied. The obvious answer is this: To achieve high availability.
Nevertheless, there are related components and processes, for example, virtualization infrastructure and storage systems (see image below), that can lead to problems in your Kubernetes infrastructure. A wide range of monitoring products with distinct functions, alerting methods, and integrations are available.
Before writing a OneAgent plugin, it’s always bestpractice to check that the metric(s) you want to add are not already in Dynatrace. For example, the number of threads of your process is already available in Dynatrace in most cases, so there is no need to spend the extra effort. OneAgent & cloud metrics.
Site reliability engineering (SRE) is the practice of applying software engineering principles to operations and infrastructure processes to help organizations create highly reliable and scalable software systems. ” According to Google, “SRE is what you get when you treat operations as a software problem.” Solving for SR.
Unfortunately, container security is much more difficult to achieve than security for more traditional compute platforms, such as virtual machines or bare metal hosts. Bestpractices for container security. Here is a checklist of bestpractices for how to approach container security. Pretty neat, isn’t it?
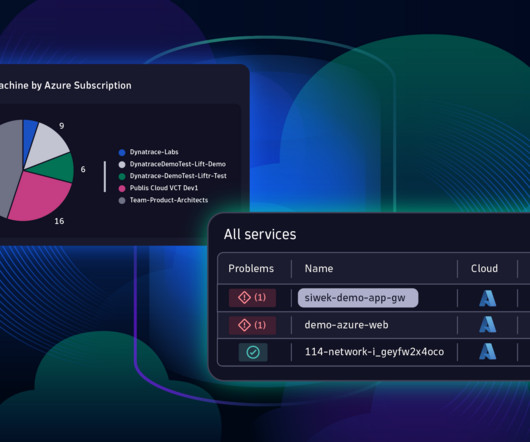
With the AI-powered Dynatrace platform now generally available on Azure, Azure Native Dynatrace Service customers can now leverage the full AI power of the Dynatrace platform directly from Azure. The following shows a simple DQL summarizing all Azure Virtual Machine cores in the connected Azure subscriptions.
Collected metrics are analyzed in Dynatrace, using the SAP expert community’s established best-practice advice on ABAP platform health indicators, including response time breakdowns of the response times between ABAP-specific application server activities, tasks, and database interaction.
These organizations rely heavily on performance, availability, and user satisfaction to drive sales and retain customers. AvailabilityAvailability SLO quantifies the expected level of service availability over a specific time period. Availability is typically expressed in 9’s, such as 99.9%. or 99.99% of the time.
To pass information such as Test Step Name (TSN), Load Test Name (LTN), Load Script Name (LSN), Virtual User Id (VU) and others we can follow the load testing integration bestpractice as documented in Dynatrace and load testing tools integration. The following shows the screenshot of a rule for TSN.
Observability is a set of practices and technologies that helps IT teams understand what’s happening across complex environments so that teams can detect and resolve issues quickly, without disruption to users. Keptn includes bestpractices that help developers choose which sequences to use. Charting the course with Keptn.
To address these challenges, architects must design robust and scalable MongoDB databases and adopt appropriate sharding strategies that can efficiently handle increasing workloads while ensuring continuous availability. Sharding is a preferred approach for database systems facing substantial growth and needing high availability.
The team behind Dynatrace University has always pushed themselves to achieve more and provide its users with up to date content.And with that, we’re excited to announce Dynatrace University 2020 is now available! Now available in your language! What’s changing? And that’s not all.
This approach was presented virtually in the on-demand observability clinic, Getting Started with Observability-Driven DevOps and SRE Automation. Dynatrace makes this easy by offering a collection of best-practice SLO definitions for various use cases beyond the observability domain. Check out the full webinar here!
DigitalOcean specialized in SSD-based virtual machines called Droplets that are broken down into four simple categories. If you’re running MongoDB on DigitalOcean in production, it’s bestpractices to deploy using a replica set to ensure high availability and data redundancy for your clusters. DigitalOcean Droplets.
Microservices development is intrinsically optimized for continuous integration/continuous deployment ( CI/CD ) processes that apply agile development bestpractices for the rapid delivery of reliable code. For example, a virtual machine (VM) can replace containers to design and architect microservices.
With the average cost of unplanned downtime running from $300,000 to $500,000 per hour , businesses are increasingly using high availability (HA) technologies to maximize application uptime. Where a high availability design once worked well, it can no longer keep up with more complex requirements. there cannot be high availability.
Support all the mechanisms and best-practices of git-based workflows such as pull requests, merging and approvals. Dynatrace MaaS is an integral part of adopting Autonomous Cloud Enablement bestpractices, where we look at automating everything with, and around, Dynatrace. Stay tuned for an upcoming Performance Clinic !
Our Cloud Automation Roadshow brings the latest cloud-native automation practices to our attendees. Last week we kicked it off with a three-hour virtual hands-on workshop. The initial plan was to do it onsite in Ohio, but – I guess I don’t have to tell you why – we decided to start virtual first.
A CDN (Content Delivery Network) is a network of geographically distributed servers that brings web content closer to where end users are located, to ensure high availability, optimized performance and low latency. Multi-CDN is the practice of employing a number of CDN providers simultaneously. What is Multi-CDN?A
We’re currently in a technological era where we have a large variety of computing endpoints at our disposal like containers, Platform as a Service (PaaS), serverless, virtual machines, APIs, etc. Treating these different processes as code will ensure that bestpractices are followed. with more being added continually.
Various forms can take shape when discussing workloads within the realm of cloud computing environments – examples include order management databases, collaboration tools, videoconferencing systems, virtual desktops, and disaster recovery mechanisms. This applies to both virtual machines and container-based deployments.
In this blog post, we will discuss the bestpractices on the MongoDB ecosystem applied at the Operating System (OS) and MongoDB levels. We’ll also go over some bestpractices for MongoDB security as well as MongoDB data modeling. There is an issue with this, which causes the OS to swap even with memory available.
Authorization and Access Control In RabbitMQ, authorization dictates the operations a user may execute on given virtual hosts. Virtual Hosts and Resource Permissions In RabbitMQ, virtual hosts craft distinct isolated environments that upgrade security and resource segregation by restricting inter-vhost communication.
Join us at Dynatrace Perform 2024 , either on-site or virtuall y, to explore these themes further. Building observability-as-code into platform engineering enables automatic service-level objective creation, defined ownership, enriched context, and problem routing to ensure platforms remain available and reliable for developers.
However, there are a handful of ways available to us—some are, admittedly, more easy and free than others. What follows is overall best-practice advice for designing with latency in mind. Pay Latency Costs Up-Front and Out of Band Even with the best will in the world, we will have to incur some latency.
Virtually every business relies on outside service providers for anything from web servers to third-party APIs enabling their app functionality for the end user. Together they demonstrate our commitment to information security bestpractices and delivering the best value for customers. ISO 27001 Certification.
A CDN (Content Delivery Network) is a network of geographically distributed servers that brings web content closer to where end users are located, to ensure high availability, optimized performance and low latency. Multi-CDN is the practice of employing a number of CDN providers simultaneously. What is Multi-CDN?A
Let’s review the bestpractices we usually follow in Managed Services before using your MySQL server in production and stage env, even for home play purposes. The kernel’s memory allocation function allocates the requested page size, and sometimes more, rounded up to fit within the available memory.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content