This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Site reliability engineering (SRE) plays a vital role in ensuring Java applications' high availability, performance, and scalability. This discipline merges software engineering and operations, aiming to create a robust infrastructure that supports seamless user experiences.
Implementing clustering and quorum queues in RabbitMQ significantly improves load distribution and data redundancy, ensuring high availability and fault tolerance for messaging services. Classic queues can be used in clusters, emphasizing their behavior during node failures, particularly regarding durability and availability.
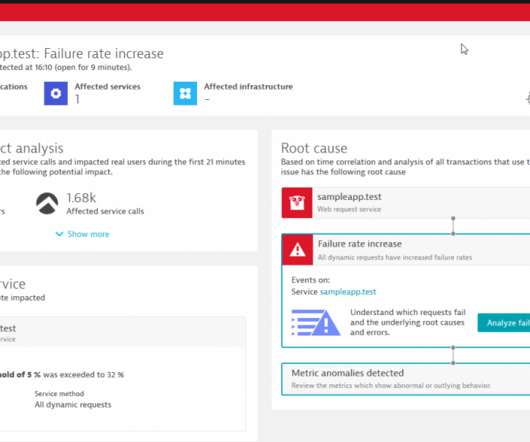
Digital experience monitoring (DEM) is crucial for organizations to meet this demand and succeed in today’s competitive digital economy. DEM solutions monitor and analyze the quality of digital experiences for users across digital channels. The time taken to complete the page load.
Service-level objectives are typically used to monitor business-critical services and applications. However, due to the fact that they boil down selected indicators to single values and track error budget levels, they also offer a suitable way to monitor optimization processes while aligning on single values to meet overall goals.
Dynatrace, available as an Azure-native service , has a longstanding partnership with Microsoft, deeply rooted in a strong “build with” approach to deliver seamless user experience. The solution also allows customers to combine alerts from best-in-class security solutions. Runtime application protection.
As businesses compete for customer loyalty, it’s critical to understand the difference between real-user monitoring and synthetic user monitoring. These development and testing practices ensure the performance of critical applications and resources to deliver loyalty-building user experiences. What is real user monitoring?
By following key log analytics and log management bestpractices, teams can get more business value from their data. Challenges driving the need for log analytics and log management bestpractices As organizations undergo digital transformation and adopt more cloud computing techniques, data volume is proliferating.
Empowering teams to manage their FinOps practices, however, requires teams to have access to reliable multicloud monitoring and analysis data. Flexible pricing models that offer discounts based on commitment or availability can greatly reduce cloud waste. On-demand payment is the most expensive pricing option.
Streamlining observability with Dynatrace OneAgent on AWS Image Builder In our ongoing collaboration with AWS, we’re excited to make the Dynatrace OneAgent available as a first-class integration on AWS Image Builder via the AWS Marketplace.
Here, we’ll tackle the basics, benefits, and bestpractices of IAC, as well as choosing infrastructure-as-code tools for your organization. Infrastructure as code is a practice that automates IT infrastructure provisioning and management by codifying it as software. Exploring IAC bestpractices. Consistency.
Without SRE bestpractices, the observability landscape is too complex for any single organization to manage. Like any evolving discipline, it is characterized by a lack of commonly accepted practices and tools. In a talent-constrained market, the best strategy could be to develop expertise from within the organization.
Keeping pace with modern digital transformation requires ensuring that applications are responsive, resilient, and always available amid increased complexity. There are now many more applications, tools, and infrastructure variables that impact an application’s performance and availability. availability.
With the increasing frequency of cyberattacks, it is imperative to institute a set of cybersecurity bestpractices that safeguard your organization’s data and privacy. Continuously monitoring your runtime environments for vulnerabilities will also reveal security issues that may have only shown themselves during production.
Sometimes, introducing new IT solutions is delayed or canceled because a single business unit can’t manage the operating costs alone, and per-department cost insights that could facilitate cost sharing aren’t available. In scenarios like these, automated and precise cost allocation can make a huge difference.
In fact, according to a Dynatrace global survey of 1,300 CIOs , 99% of enterprises utilize a multicloud environment and seven cloud monitoring solutions on average. What is cloud monitoring? Cloud monitoring is a set of solutions and practices used to observe, measure, analyze, and manage the health of cloud-based IT infrastructure.
A team looking for metrics, traces, and logs no longer needs to file a ticket to get their app monitored in their own environments. Embracing cloud native bestpractices to increase automation. The application consists of several microservices that are available as pod-backed services.
Whether you’re a seasoned IT expert or a marketing professional looking to improve business performance, understanding the data available to you is essential. With Dashboards , you can monitor business performance, user interactions, security vulnerabilities, IT infrastructure health, and so much more, all in real time.
Keeping ownership teams and their properties up to date is essential, as is having the right contact information available when needed. Finally, the best information is still useless if users can’t retrieve it quickly when needed and use it accordingly. Dynatrace offers several ways to ingest ownership team information.
We’re happy to announce the General Availability of cross-environment dashboarding capabilities (having released this functionality in an Early Adopter release with Dynatrace version 1.172 back in June 2019). Monitoring the enterprise cloud poses many challenges when it comes to scale. Dynatrace news.
Cloud security monitoring is key—identifying threats in real-time and mitigating risks before they escalate. This article strips away the complexities, walking you through bestpractices, top tools, and strategies you’ll need for a well-defended cloud infrastructure. What does it take to secure your cloud assets effectively?
While selecting a Kubernetes segment, the selector provides a dynamic list of available resources. Segments can implement variables to dynamically provide, for example, a list of entities to users, such as available Kubernetes clusters, for unmatched flexibility and dynamic segmentation. What are Dynatrace Segments?
We’re excited to announce our verified HashiCorp Terraform integration is now available for Dynatrace customers. With this integration, Dynatrace customers can now leverage Terraform to manage their monitoring infrastructure as code,” said Asad Ali, Senior Director of Sales Engineering at Dynatrace. What is monitoring as code?
Building services that adhere to software bestpractices, such as Object-Oriented Programming (OOP), the SOLID principles, and modularization, is crucial to have success at this stage. Implement proactive monitoring for each of these endpoints. Track real-time title impressions from the NetflixUI. there is a dedicated collector.
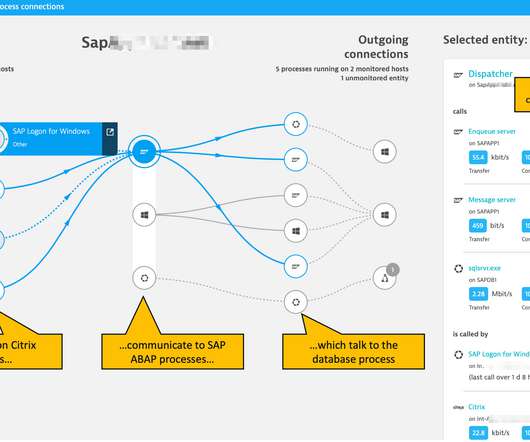
Having released this functionality in a Preview Release back in May 2019, we’re now happy to announce the General Availability of our SAP ABAP monitoring extension. Why SAP ABAP platform monitoring in Dynatrace? What is ABAP platform monitoring? Monitoring is purely remote and implemented using public SAP ABAP interfaces.
Various test tools are available for different types of testing, including unit testing, integration testing, and more. In addition to automating testing tasks, test tools can produce test data, monitor system performance, and report on test results.
Organizations can now accelerate innovation and reduce the risk of failed software releases by incorporating on-demand synthetic monitoring as a metrics provider for automatic, continuous release-validation processes. Dynatrace combines Synthetic Monitoring with automatic release validation for continuous quality assurance across the SDLC.
Because of this, preserving the availability and integrity of the data stored in MySQL databases requires regular backups. By understanding the different backup strategies and types available, you can select the best approach for your organization and ensure your data is properly protected.
We’re proud to announce the Early Access Program (EAP) for monitoring of SAP ABAP performance from the infrastructure and ABAP application platform perspective. Why SAP ABAP platform monitoring in Dynatrace? What is ABAP platform monitoring? Monitoring is purely remote and implemented using public SAP ABAP interfaces.
Configuring monitoring and observability is no stranger to that paradigm and it was also highlighted in the latest State of DevOps 2020 report. Defining what to monitor and what to be alerted on must be as easy for developers as checking in a monitoring configuration file into version control along with the applications source code.
In what follows, we explore some of these bestpractices and guidance for implementing service-level objectives in your monitored environment. Bestpractices for implementing service-level objectives. Availability. To measure availability, we can rely on an HTTP monitor from Dynatrace Synthetic Monitoring.
Taking those into account and understanding how we use Dynatrace for self-monitoring, our analysis suggests that using unified observability and security from Dynatrace can lead to saving up to 50% – 70% of the effort required to manage DORA compliance.
Our enhanced host monitoring dashboard that highlights disk usage includes AI forecasting for CPU usage. While the Explore interface is useful for quickly visualizing known metrics, Davis CoPilot is great for exploring your data when you know your desired outcome but are unfamiliar with the available data. Looking for something?
While many large-scale environments use OpenShift Container Platform (OCP) as their Kubernetes distribution of choice, teams typically still lack intelligent observability and centralized alerting despite the monitoring system included with the platform. This results in performance issues or even downtime that could easily be prevented.
Also called continuous monitoring or synthetic monitoring , synthetic testing mimics actual users’ behaviors to help companies identify and remediate potential availability and performance issues. Types of synthetic testing There are three broad types of synthetic testing: availability, web performance, and transaction.
A Kubernetes-centric Internal Development Platform (IDP) enables platform engineering teams to provide self-service capabilities and features to their DevSecOps teams who need resilient, available, and secure infrastructure to build and deploy business-critical customer applications. All important health signals are highlighted.
Once automated, steps like testing and provisioning can be integrated into development and performed as soon as needed instead of waiting for humans to be available to do it. Bestpractices for adopting continuous delivery. Here are some bestpractices to consider for automating delivery effectively.
While this is a key capability, as k8s will restart pods that are unhealthy, it doesn’t guarantee that services exposed via Ingress are also available and responding within your SLAs to those that rely on these services: your end-users or service consumers outside k8s that call your services. sending problems to a specific team slack.
Properly monitoring a Kubernetes cluster or any related environment can be difficult. Service-level objectives (SLOs) are often used to monitor business-critical services and applications for customers. However, they can also be used to monitor optimization processes effectively.
Because all these resources generate huge amounts of data in various locations, it makes it difficult to monitor. These challenges make Azure observability critical for building and monitoring cloud-native applications. One of the key monitoring strategies in the Cloud Adoption Framework is observability.
Monitoring SAP products can present challenges Monitoring SAP systems can be challenging due to the inherent complexity of using different technologies—such as ABAP, Java, and cloud offerings—and the sheer amount of generated data. SAP Basis teams have established bestpractices for managing their SAP systems.
In this blog post, we’ll discuss the methods we used to ensure a successful launch, including: How we tested the system Netflix technologies involved Bestpractices we developed Realistic Test Traffic Netflix traffic ebbs and flows throughout the day in a sinusoidal pattern. Basic with ads was launched worldwide on November 3rd.
The predefined set of files monitored for configuration alterations is maintained within ruxitagentproc.conf. Although Dynatrace can detect configuration changes, the bestpractice is to systematically ingest a configuration change or deployment change event each time the team modifies a configuration file.
After investigating, the software engineering team discovered that it wasn’t leveraging application performance monitoring (APM) tooling data to its full potential. The team constructed dashboards to monitor their progress toward achieving those key performance indicators (KPIs) over time. Here’s the approach they chose.
Most monitoring tools for migrations, development, and operations focus on collecting and aggregating the three pillars of observability— metrics, traces, and logs. The Framework is built on five pillars of architectural bestpractices: Cost optimization. Continuously monitor cost and optimize your capacity needs.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content