This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Site reliability engineering (SRE) plays a vital role in ensuring Java applications' high availability, performance, and scalability. This discipline merges software engineering and operations, aiming to create a robust infrastructure that supports seamless user experiences.
Implementing clustering and quorum queues in RabbitMQ significantly improves load distribution and data redundancy, ensuring high availability and fault tolerance for messaging services. Classic queues can be used in clusters, emphasizing their behavior during node failures, particularly regarding durability and availability.
.” While this methodology extends to every layer of the IT stack, infrastructure as code (IAC) is the most prominent example. Here, we’ll tackle the basics, benefits, and bestpractices of IAC, as well as choosing infrastructure-as-code tools for your organization. What is infrastructure as code?
In this blog, I would like to share a few bestpractices for creating High Available (HA) Applications in Mule 4 from an infrastructure perspective ONLY ( CloudHub in this article refers to CloudHub 1.0
By proactively implementing digital experience monitoring bestpractices and optimizing user experiences , organizations can increase long-term customer satisfaction and loyalty, drive business value , and accelerate innovation. The post 10 digital experience monitoring bestpractices appeared first on Dynatrace news.
By following key log analytics and log management bestpractices, teams can get more business value from their data. Challenges driving the need for log analytics and log management bestpractices As organizations undergo digital transformation and adopt more cloud computing techniques, data volume is proliferating.
Dynatrace, available as an Azure-native service , has a longstanding partnership with Microsoft, deeply rooted in a strong “build with” approach to deliver seamless user experience. This enables Dynatrace customers to achieve faster time-to-value and accelerate innovation.
In a Dynatrace Perform 2024 session, Kristof Renders, director of innovation services, discussed how a stronger FinOps strategy coupled with observability can make a significant difference in helping teams to keep spiraling infrastructure costs under control and manage cloud spending. On-demand payment is the most expensive pricing option.
Streamlining observability with Dynatrace OneAgent on AWS Image Builder In our ongoing collaboration with AWS, we’re excited to make the Dynatrace OneAgent available as a first-class integration on AWS Image Builder via the AWS Marketplace.
Without SRE bestpractices, the observability landscape is too complex for any single organization to manage. Like any evolving discipline, it is characterized by a lack of commonly accepted practices and tools. Like any evolving discipline, it is characterized by a lack of commonly accepted practices and tools.
It’s more important than ever for organizations to ensure they’re taking appropriate measures to secure and protect their applications and infrastructure. With the increasing frequency of cyberattacks, it is imperative to institute a set of cybersecurity bestpractices that safeguard your organization’s data and privacy.
Keeping pace with modern digital transformation requires ensuring that applications are responsive, resilient, and always available amid increased complexity. There are now many more applications, tools, and infrastructure variables that impact an application’s performance and availability.
By gaining insights into how your Kubernetes workloads utilize computing and memory resources, you can make informed decisions about how to size and plan your infrastructure, leading to reduced costs. The outlined SLOs for Kubernetes clusters guide you in implementing SRE bestpractices in monitoring your Kubernetes environment.
Whether you’re a seasoned IT expert or a marketing professional looking to improve business performance, understanding the data available to you is essential. With Dashboards , you can monitor business performance, user interactions, security vulnerabilities, IT infrastructure health, and so much more, all in real time.
To solve this problem , Dynatrace offers a fully automated approach to infrastructure and application observability including Kubernetes control plane, deployments, pods, nodes, and a wide array of cloud-native technologies. Embracing cloud native bestpractices to increase automation. Monitoring such an application is easy.
Protecting IT infrastructure, applications, and data requires that you understand security weaknesses attackers can exploit. Cloud infrastructure analysis ensures the secure configuration of cloud infrastructure including virtual machines, containers, cloud-hosted databases, and serverless services. Dynatrace news.
As file sizes grow and workflows become more complex, these issues are magnified, leading to inefficiencies that slow down post-production and reduce the available time spent on creativework. Depending on the market, or production budget, cutting-edge technology might not be available or affordable. So what isit?
With more organizations taking the multicloud plunge, monitoring cloud infrastructure is critical to ensure all components of the cloud computing stack are available, high-performing, and secure. Website monitoring examines a cloud-hosted website’s processes, traffic, availability, and resource use. Website monitoring.
This article strips away the complexities, walking you through bestpractices, top tools, and strategies you’ll need for a well-defended cloud infrastructure. Get ready for actionable insights that balance technical depth with practical advice.
You can either continue with the custom infrastructure metrics dashboard you created in Part I or use the dashboard we prepared here (Dynatrace login required). exploring your data when you know your desired outcome but are unfamiliar with the available data. Add Transmit/Receive (Tx/Rx) bytes using Davis CoPilot.
Central engineering teams enable this operational model by reducing the cognitive burden on innovation teams through solutions related to securing, scaling and strengthening (resilience) the infrastructure. All these micro-services are currently operated in AWS cloud infrastructure.
The development of internal platform teams has taken off in the last three years, primarily in response to the challenges inherent in scaling modern, containerized IT infrastructures. Platform engineering bestpractices for delivering a highly available, secure, and resilient Internal Development Platform: Centralize and standardize.
Many of these projects are under constant development by dedicated teams with their own business goals and development bestpractices, such as the system that supports our content decision makers , or the system that ranks which language subtitles are most valuable for a specific piece ofcontent.
Because of this, preserving the availability and integrity of the data stored in MySQL databases requires regular backups. By understanding the different backup strategies and types available, you can select the best approach for your organization and ensure your data is properly protected.
SLOs can be a great way for DevOps and infrastructure teams to use data and performance expectations to make decisions, such as whether to release and where engineers should focus their time. In what follows, we explore some of these bestpractices and guidance for implementing service-level objectives in your monitored environment.
Famous for providing out-of-the-box solutions, automation, and smart context across the entire application infrastructure with our unique Davis AI, Dynatrace now delivers two new extensions to assist teams that face the challenges associated with operating self-managed OCP installations. Control plane.
Before we get into the specifics, let’s first recap the benefits OpenTelemetry offers and why using collectors is a bestpractice. Developers and operators can gain insights into their applications and infrastructure without fear of vendor lock-in because OpenTelemetry is fully open source and owned by CNCF.
This enables teams to quickly develop and test key functions without the headaches typically associated with in-house infrastructure management. Infrastructure as a service (IaaS) handles compute, storage, and network resources. Increased availability. Functional FaaS bestpractices. But how does FaaS fit in?
CD is the next step in the process that automates the delivery of applications to selected infrastructure environments, such as a development environment for a related feature, or testing environments to verify feature functionality and proper integration with other parts of the software. Bestpractices for adopting continuous delivery.
By using Cloud Adoption Framework bestpractices, organizations are better able to align their business and technical strategies to ensure success. As organizations adopt more cloud-native technologies, infrastructure and application monitoring can get complex. Best in class observability for Microsoft Azure—and beyond.
From the very first days of Dynatrace development, preventing the injection of malicious code that could potentially compromise customer infrastructure, has been a priority. The signatures are automatically verified during the update process on the customer infrastructure. No manual, error-prone steps are involved.
We’re excited to announce our verified HashiCorp Terraform integration is now available for Dynatrace customers. HashiCorp’s Terraform is an open-source infrastructure as a code software tool that provides a consistent CLI workflow to manage hundreds of cloud services. Terraform codifies cloud APIs into declarative configuration files.
Amazon Elastic Kubernetes Service is a managed infrastructure service offered by Amazon Web Services that executes and scales Kubernetes applications in the AWS cloud. Create web applications that are highly available across multiple availability zones and scales to meet your demanding consumption footprints .
This tier extended existing infrastructure by adding new backend components and a new remote call to our ads partner on the playback path. The availability of replay traffic 24/7 enabled us to refine our systems and boost our launch confidence, reducing stress levels for the team. Basic with ads was launched worldwide on November 3rd.
We’ll answer that question and explore cloud migration benefits and bestpractices for how to go through your migration smoothly. Cloud migration is the process of transferring some or all your data, software, and operations to a cloud-based computing environment that offers unlimited scale and high availability.
While infrastructure has historically been treated as a bottleneck where proper scaling and compute power are applied to improve performance, these aspects are now typically addressed by hyperscalers that offer cloud-based infrastructure and infrastructure as a service.
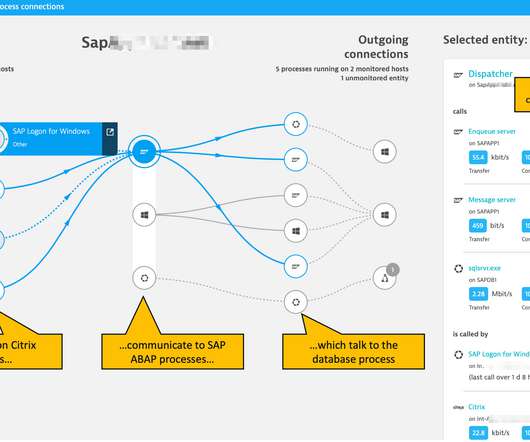
Having released this functionality in a Preview Release back in May 2019, we’re now happy to announce the General Availability of our SAP ABAP monitoring extension. This extends Dynatrace visibility into SAP ABAP performance from the infrastructure and ABAP application platform perspective. What is ABAP platform monitoring?
To make data count and to ensure cloud computing is unabated, companies and organizations must have highly available databases. This guide provides an overview of what high availability means, the components involved, how to measure high availability, and how to achieve it. How does high availability work?
In addition, ready-made dashboards are available for a quick and easy overview, allowing you to see the Kubernetes data you want alongside the observability data you need, all in one place. Applying Service Level Objectives (SLO) to track these indicators is a common bestpractice within site reliability engineering.
These organizations rely heavily on performance, availability, and user satisfaction to drive sales and retain customers. AvailabilityAvailability SLO quantifies the expected level of service availability over a specific time period. Availability is typically expressed in 9’s, such as 99.9%. or 99.99% of the time.
Site reliability engineering (SRE) is the practice of applying software engineering principles to operations and infrastructure processes to help organizations create highly reliable and scalable software systems. ” According to Google, “SRE is what you get when you treat operations as a software problem.”
More recently, teams have begun to apply DevOps bestpractices to infrastructure automation, giving developers a more active role with GitOps as an operational framework. Key components of GitOps are declarative infrastructure as code, orchestration, and observability. How to get started.
Imagine that instead of development teams fending for themselves amidst a sea of tools and infrastructure, well-defined and enterprise-wide templates are provided for the development of all new product services. The new functionality has already been released and is available for your use.
SAP Basis teams have established bestpractices for managing their SAP systems. Teams benefit from a boost in aligning SAP operations practices with the operation of all surrounding systems that SAP depends on and those that depend on SAP. SAP HANA server infrastructure monitored with OneAgent.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content