This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
By following key log analytics and log management bestpractices, teams can get more business value from their data. Challenges driving the need for log analytics and log management bestpractices As organizations undergo digital transformation and adopt more cloud computing techniques, data volume is proliferating.
Flexible pricing models that offer discounts based on commitment or availability can greatly reduce cloud waste. This includes spot instances such as unused cloud capacity that’s available at a discounted price. Hyperscaler cloud service providers such as AWS, Microsoft Azure, and Google Cloud Platform can do this, too.
Keeping pace with modern digital transformation requires ensuring that applications are responsive, resilient, and always available amid increased complexity. There are now many more applications, tools, and infrastructure variables that impact an application’s performance and availability. availability.
These items are the fruits of those ideas, the items I deemed worthy from my Google Reader feeds. Making Google’s CalDAV and CardDAV APIs available for everyone ( Google Developers Blog). Pandora launches new HTML5 site for TVs and gaming consoles, available now on PS3 and Xbox 360 ( The Next Web). Hacker News).
In what follows, we explore some of these bestpractices and guidance for implementing service-level objectives in your monitored environment. Bestpractices for implementing service-level objectives. Availability. To measure availability, we can rely on an HTTP monitor from Dynatrace Synthetic Monitoring.
Cloud providers such as Google, Amazon Web Services, and Microsoft also followed suit with frameworks such as Google Cloud Functions , AWS Lambda , and Microsoft Azure Functions. Increased availability. Functional FaaS bestpractices. The FaaS model of cloud computing debuted in 2014 with startups like hook.io.
SRE is the transformation of traditional operations practices by using software engineering and DevOps principles to improve the availability, performance, and scalability of releases by building resiliency into apps and infrastructure. Designating and managing Service Level Objectives (SLOs) as availability targets for a service.
As a discipline, SRE focuses on improving software system reliability across key categories including availability, performance, latency, efficiency, capacity, and incident response. ” According to Google, “SRE is what you get when you treat operations as a software problem.” SRE focuses on automation. Solving for SR.
As a discipline, SRE focuses on improving software system reliability across key categories including availability, performance, latency, efficiency, capacity, and incident response. ” According to Google, “SRE is what you get when you treat operations as a software problem.” SRE focuses on automation. Solving for SR.
This is a set of bestpractices and guidelines that help you design and operate reliable, secure, efficient, cost-effective, and sustainable systems in the cloud. But how can you ensure that your applications meet these pillars and deliver the best outcomes for your business?
Typically, an SRE team spends a good amount of time selecting the best indictor metrics for their given services, which then leads to well-defined SLOs that reflect the service quality. The Google Site Reliability Engineering page is a great read for understanding and embracing the idea of defining SLOs for reliable global IT services.
These organizations rely heavily on performance, availability, and user satisfaction to drive sales and retain customers. AvailabilityAvailability SLO quantifies the expected level of service availability over a specific time period. Availability is typically expressed in 9’s, such as 99.9%. or 99.99% of the time.
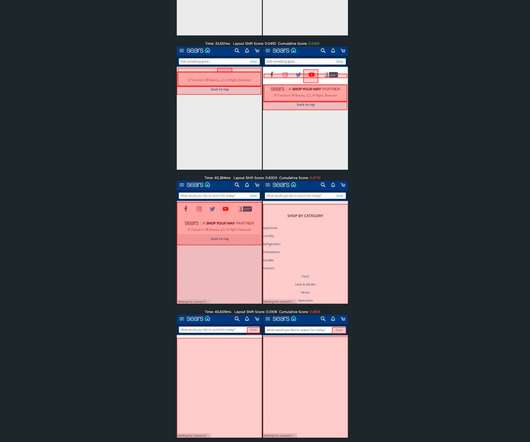
Every organization’s goal is to keep its systems available and resilient to support business demands. This view shows the availability SLO for key application functions, like login and vehicle list, as well as a large set of timeframes, like last 30 minutes, last hour, today, and last six days. Dynatrace news.
Keptn: A reference implementation of Google’s SRE principles. Software engineer Taras Tsugrii of Meta (formerly Facebook) paid Keptn a high compliment, saying it feels like a reference implementation of Google’s SRE principles , which are the search giant’s techniques for ensuring the integrity of its sites and services.
service availability with <50ms latency for an application with no revenue impact. If an SLO is not tied back to a key business objective or external SLAs, it is best to reconsider or recalibrate the objective. The best investment is in managing SLOs for customer-facing, revenue-generating, high visibility applications.
During a breakout session at Dynatrace’s Perform 2021 event, Senior Product Marketing Manager Logan Franey and Product Manager Dominik Punz shared mobile app monitoring bestpractices to maximize business outcomes. And those are just the tools for monitoring the tech stack. These teams may also have a separate mobile crash tool.
Organizations are constantly being measured against the bestavailable digital experiences — coming from Google, Amazon, Facebook, and other industry leaders. Some of the factors that affect user experience include: Availability : Is the touchpoint available when the user wants to use it? Break down silos.
From site reliability engineering to service-level objectives and DevSecOps, these resources focus on how organizations are using these bestpractices to innovate at speed without sacrificing quality, reliability, or security. Learn more about DevOps and bestpractices to achieve it at scale.
If you’re new to SLOs and want to learn more about them, how they’re used, and bestpractices, see the additional resources listed at the end of this article. According to the Google Site Reliability Engineering (SRE) handbook, monitoring the four golden signals is crucial in delivering high-performing software solutions.
As businesses and applications increasingly rely on MySQL databases to manage their critical data, ensuring data reliability and availability becomes paramount. MySQL itself does not provide the capability for taking file system snapshots but it is available using third-party solutions such as LVM or ZFS. Did you look at the file size?
In fact, giants like Google and Microsoft once employed monolithic architectures almost exclusively. Smaller teams can launch services much faster using flexible containerized environments, such as Kubernetes, or serverless functions, such as AWS Lambda, Google Cloud Functions, and Azure Functions. Serverless platforms. Service mesh.
Let’s explore this concept as we look at the bestpractices and solutions you should keep in mind to overcome the wall and keep up with today’s fast-paced and intricate cloud landscape. But what exactly is this “wall,” and what are the big-picture implications for your organization?
DevOps bestpractices include testing within the CI/CD pipeline, also known as shift-left testing. In production, SREs utilize Cloud Automation to, for example, continuously validate the availability of their applications across the globe from our 80-plus global Synthetic Monitoring locations.
In the free ebook “ A Beginner’s Guide to DevOps ,” DevOps is defined as a set of software development and delivery bestpractices to close the gap between software development and IT operations. DevOps is a framework that aims to eliminate organizational silos to streamline successful software delivery.
While Google’s SRE Handbook mostly focuses on the production use case for SLIs/SLOs, Keptn is “Shifting-Left” this approach and using SLIs/SLOs to enforce Quality Gates as part of your progressive delivery process. If an alert is triggered, Keptn automates operational tasks such as triggering remediation actions.
Fortunately, monitoring solutions are available to analyze and display such data, provide deep insights, and take automated actions based on those insights (for example, alerting or remediation). A wide range of monitoring products with distinct functions, alerting methods, and integrations are available. The Kubernetes experience.
However, there are a handful of ways available to us—some are, admittedly, more easy and free than others. What follows is overall best-practice advice for designing with latency in mind. However, a lot of the things I have discussed are either: trivial to implement just by using a decent CDN, and; bestpractice anyway.
These organizations rely heavily on performance, availability, and user satisfaction to drive sales and retain customers. AvailabilityAvailability SLO quantifies the expected level of service availability over a specific time period. Availability is typically expressed in 9’s, such as 99.9%. or 99.99% of the time.
While you may assume a great majority of the cloud database deployments are run on AWS, Azure, or Google Cloud Platform, small to medium-sized businesses in particular are gravitating towards the developer-friendly cloud provider, DigitalOcean , for their hosting for MongoDB® needs. MongoDB Replication Strategies.
The most beautiful, spectacular site in the world won’t do anyone much good if people can’t find it on Google (or Bing, or DuckDuckGo). Following bestpractice usually means a better website, more organic traffic, and happier visitors. Google Keyword Planner. Google Trends. Google Mobile-Friendly Test.
By integrating bestpractices such as least privilege into an IAM pipeline, we transitioned the security team from being gatekeepers of the cloud into cloud development accelerators. Getting Started ConsoleMe is available on GitHub (Give us a ?!). A quick start guide is available in our documentation. What is ConsoleMe?
We have several YouTube Tutorials and blog posts available that show how you can use Dynatrace RUM data for Web Performance & User Experience Optimization. We have several studies from Google, Facebook & Co that show that faster services and apps ultimately lead to increased user adoption. Impressive results I have to say!
2020, a new game called FAU-G was released on the Google play store. Android’s official application store, the Google play store, hosts 2.87 This number is excluding the third-party hostings which are large in number and are not on the Google play store. million android applications on its platform. Signup here.
Our customers often tell us how much they appreciate the user-friendliness of the articles we create for them, so we recently decided to make them available to everyone (not just SpeedCurve users). Introducing the Web Performance Guide ! Core Web Vitals There are a lot of metrics you need to track, and Core Web Vitals are among them.
Surveying the existing landscape of available developer tools and runtimes, we felt that there is a gap. Our vision with Hydrogen and Oxygen is to unlock the best of both worlds and make building and running the next million of modern — dynamic, contextual, and personalized — storefronts easier, more cost-effective, and fun.
Google Lighthouse Google Lighthouse is a free and open source tool that is part of the Google Chrome DevTools family. Its tailored to enterprise applications that have thousands of users, but limited free edition is available. WebLOAD WebLOAD offers a robust toolset that is top of the line.
Google Fonts. Google Sheets sync. Thousands of avatars available straight from Figma: UI Faces. The plugin has a large library of (literally) millions of logos available at your fingertips. The plugin supports copy and paste from Excel, Google sheet, Numbers and it also can sync with Google Sheets and remote JSON.
to run Google Lighthouse audits via the command line, save the reports they generate in JSON format and then compare them so web performance can be monitored as the website grows and develops. I’m hopeful this can serve as a good introduction for any developer interested in learning about how to work with Google Lighthouse programmatically.
How does page bloat affect other metrics, such as Google's Core Web Vitals? A Google machine-learning study I participated in a few years ago found that the total number of page elements was the single greatest predictor of conversions. You can dive deeper into image optimization and SEO tips in this article in Google Search Central.).
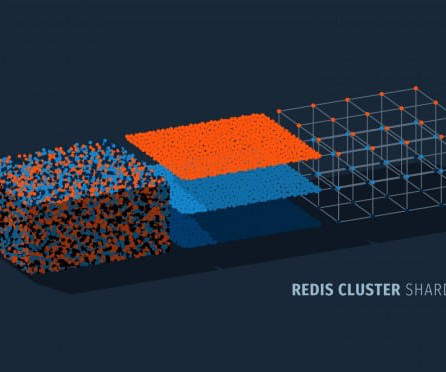
It offers automatic data sharding, master-replica configurations for high availability, and a scalable and flexible architecture to maintain consistent performance. Sharding in Redis involves dividing data across multiple machines to enhance scalability and maintain availability. What is Redis Sharding?
As with many burgeoning fields and disciplines, we don’t yet have a shared canonical infrastructure stack or bestpractices for developing and deploying data-intensive applications. Can’t we just fold it into existing DevOps bestpractices? How can you start applying the stack in practice today?
Heck, typing “database migration plan” into Google and reading this blog could constitute planning. It lacks many of the high availability and security features critical for production environments. Ignoring this valuable resource can also limit your access to updates, patches, and bestpractices.
All rely heavily on utilizing allocated portions from existing pools made available through specific providers as part of their service offerings. Examples include associations with Google Docs, Facebook chat group interactions, streaming live forex market feeds, and managing trading notices.
Smaller HTML means less time for Google to download and process those long strings of text. Both for Google bots (SEO) and to actual clients. Google’s amount of time and resources to crawling a site is commonly called the site’s crawl budget.” — “ Advanced SEO ,” Google Search Central Documentation.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content