This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The nirvana state of system uptime at peak loads is known as “five-nines availability.” In its pursuit, IT teams hover over system performance dashboards hoping their preparations will deliver five nines—or even four nines—availability. But is five nines availability attainable? What is always-on infrastructure?
Microsoft Azure is one of the most popular cloud providers in the world, and a natural fit for database hosting on applications leveraging Microsoft across their infrastructure. While Microsoft offers their own Azure Database product, there are other alternatives available that may be able to help you improve your MySQL performance.
IT infrastructure is the heart of your digital business and connects every area – physical and virtual servers, storage, databases, networks, cloud services. We’ve seen the IT infrastructure landscape evolve rapidly over the past few years. What is infrastructure monitoring? . Dynatrace news.
Its design prioritizes high availability and efficient data transfer with minimal overhead, making it a practical choice for handling real-time data pipelines and distributed event processing. It follows a push-based approach, ensuring messages are distributed to consumers as soon as they become available.
The open source model is not only popular with the developer market, but also enterprise companies looking to modernize their infrastructure and reduce spend. You can see a detailed breakdown of this performance benchmark in their Comparing PostgreSQL DigitalOcean Performance & Pricing: ScaleGrid vs. DigitalOcean Managed Databases post.
A significant feature of Chronicle Queue Enterprise is support for TCP replication across multiple servers to ensure the high availability of application infrastructure. This is the first time I have benchmarked it with a realistic example.
Instead, they can ensure that services comport with the pre-established benchmarks. SLOs can be a great way for DevOps and infrastructure teams to use data and performance expectations to make decisions, such as whether to release and where engineers should focus their time. Availability. SLOs improve software quality.
As an open source database, it’s a highly popular choice for enterprise applications looking to modernize their infrastructure and reduce their total cost of ownership, along with startup and developer applications looking for a powerful, flexible and cost-effective database to work with. PostgreSQL Benchmark Setup. Benchmark Tool.
MySQL DigitalOcean Performance Benchmark. In this benchmark, we compare equivalent plan sizes between ScaleGrid MySQL on DigitalOcean and DigitalOcean Managed Databases for MySQL. We are going to use a common, popular plan size using the below configurations for this performance benchmark: Comparison Overview. DigitalOcean.
The standard dictionary subscript notation is also available. As a central ML and AI platform team, our role is to empower our partner teams with tools that maximize their productivity and effectiveness, while adapting to their specific needs (not the other way around). You can access Configs of any past runs easily through the Client API.
To make data count and to ensure cloud computing is unabated, companies and organizations must have highly available databases. This guide provides an overview of what high availability means, the components involved, how to measure high availability, and how to achieve it. How does high availability work?
Microsoft Azure is one of the most popular cloud providers in the world, and a natural fit for database hosting on applications leveraging Microsoft across their infrastructure. While Microsoft offers their own Azure Database product, there are other alternatives available that may be able to help you improve your MySQL performance.
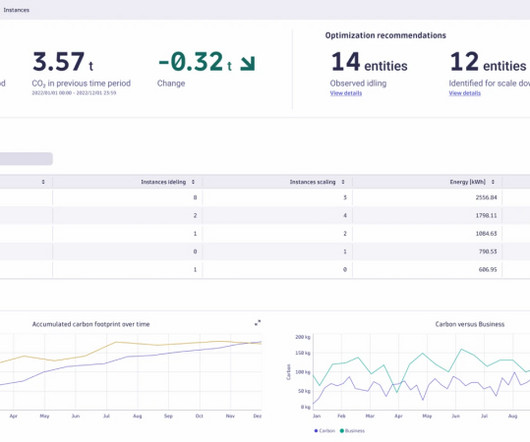
How Dynatrace tracks and mitigates its own IT carbon footprint Like many tech companies, Dynatrace is experiencing increased demand for its SaaS-based Dynatrace platform , which we host on cloud infrastructure. As we onboard more customers, the platform requires more infrastructure, leading to increased carbon emissions.
December 2 1pm-2pm CMP 326-R Capacity Management Made Easy with Amazon EC2 Auto Scaling Vadim Filanovsky , Senior Performance Engineer & Anoop Kapoor, AWS Abstract :Amazon EC2 Auto Scaling offers a hands-free capacity management experience to help customers maintain a healthy fleet, improve application availability, and reduce costs.
It’s more important than ever for organizations to ensure they’re taking appropriate measures to secure and protect their applications and infrastructure. This approach helps organizations deliver more secure software and infrastructure with greater efficiency and speed. federal government and the IT security sector.
The core benefits of an AIOps-automated software analytics platform include the following: Infrastructure monitoring. Automatically connect distributed traces with logs for improved application availability, performance, and agility. Applications and microservices monitoring. Application security. Automate DevSecOps processes at scale.
ShuffleBench i s a benchmarking tool for evaluating the performance of modern stream processing frameworks. Failures can occur unpredictably across various levels, from physical infrastructure to software layers. In Kafka Streams, a large configuration space is available for potential optimizations.
Distributing accounts across the infrastructure is an architectural decision, as a given account often has similar usage patterns, languages, and sizes for their Lambda functions. A cold start occurs when there’s no instance of the requested Lambda function available. file uploaded to AWS Lambda. The Lambda execution life cycle.
Organizations use APM to ensure system availability, optimize service performance and response times, and improve user experiences. By carefully considering the various APM tools available and how well they meet your needs, you’ll have the best chance of picking the right one for your organization. APM solutions: A primer.
The key information displayed on the standard Dynatrace Problems app and the Infrastructure and Operations App became the basis of their team’s remediation plan. By simulating user interactions and running tests from various locations worldwide, synthetic monitoring provides a comprehensive view of application performance and availability.
High-quality operational data in a central data lakehouse that is available for instant analytics is often teams’ preferred way to get consistent and accurate answers and insights. Additionally, teams should perform continuous audits to evaluate data against benchmarks and implement best practices for ensuring data quality.
Document these metrics, including the benchmark values and any insights gained from analysis, to use as a reference for tracking progress and evaluating the effectiveness of optimization efforts over time. When analyzing the data, consider factors such as time of day, device types, geographic locations, and user demographics.
Dynatrace Synthetic Monitoring allows you to proactively monitor the availability of your public as well as your internal web applications and API endpoints from locations around the globe or important internal locations such as branch offices. This is definitely a great starting benchmark against which to optimize your application.
Many good security tools provide that function, and benchmarks from the Center for Internet Security (CIS) are clear and prescriptive. Use scripts to configure hosts properly based on the CIS benchmarks. Consider using one of the many good secrets management systems that are commercially available. Remove privileges.
The ideal end user experience is friction-free: users can access available and functional applications how, when, and where they want. In addition, as part of the Dynatrace observability offering (including Apps & Microservices and Infrastructure), Dynatrace provides end-to-end visibility with AIOps and automation. Dynatrace news.
“If we’re spending a ton of time in post-mortems, it’s because we’re not spending enough time ensuring availability of applications,” he said. “I Service-level objectives (SLOs) are key to the SRE role; they are agreed-upon performance benchmarks that represent the health of an application or service.
Every browser available on iOS is simply a wrapper around Safari. Further, and by chance, iOS usage is strongly correlated with regions we generally find to have better infrastructure. In short, it’s easy to see why Safari gets left out in the cold. Why This Is a Problem. Chrome for iOS? It’s Safari with your Chrome bookmarks.
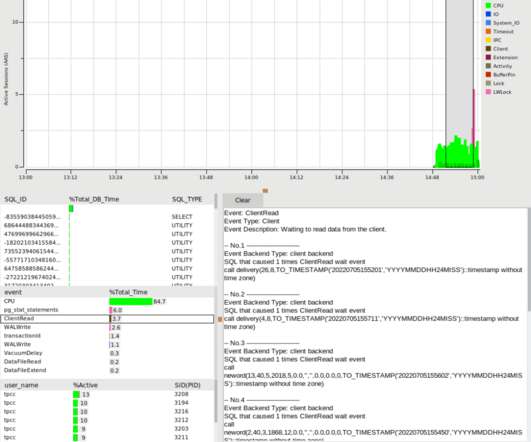
Python is a popular programming language, especially for beginners, and consequently we see it occurring in places where it just shouldn’t be used, such as database benchmarking. We use stored procedures because, as the introductory post shows, using single SQL statements turns our database benchmark into a network test).
As organizations continue to migrate to the cloud, it’s important to get in front of performance issues, such as high latency, low throughput, and replication lag with higher distances between your users and cloud infrastructure. MySQL Performance Benchmark Configuration. community edition. innodb_buffer_pool_size. sync_binlog.
Compare PostgreSQL vs. Oracle functionality across available tools, capabilities and services. These new applications are a great way for enterprise companies to test out PostgreSQL before migrating their entire infrastructure. Not available. Not available. Not available. Compare Functionality. Compare Ease of Use.
With so much at stake, database high availability and fault tolerance have become must-have items, but many companies just aren’t certain which one they must have. This blog article will examine shared attributes of high availability (HA) and fault tolerance (FT). What does high availability mean?
December 2 1pm-2pm CMP 326-R Capacity Management Made Easy with Amazon EC2 Auto Scaling Vadim Filanovsky , Senior Performance Engineer & Anoop Kapoor, AWS Abstract :Amazon EC2 Auto Scaling offers a hands-free capacity management experience to help customers maintain a healthy fleet, improve application availability, and reduce costs.
December 2 1pm-2pm CMP 326-R Capacity Management Made Easy with Amazon EC2 Auto Scaling Vadim Filanovsky , Senior Performance Engineer & Anoop Kapoor, AWS Abstract :Amazon EC2 Auto Scaling offers a hands-free capacity management experience to help customers maintain a healthy fleet, improve application availability, and reduce costs.
Netflix engineers run a series of tests and benchmarks to validate the device across multiple dimensions including compatibility of the device with the Netflix SDK, device performance, audio-video playback quality, license handling, encryption and security. The library is available in the artifactory repository for easy installation.
Testing and Validation Post-upgrade, its vital to conduct performance benchmarking to confirm that the new setup operates within acceptable parameters. Conducting load tests on the new MongoDB setup can help verify that it meets expected performance benchmarks. This helps prevent any disruptions or functionality issues post-upgrade.
By applying software engineering principles to operations and infrastructure practices, SRE enables organizations to streamline and automate IT processes. Teams still need to make progress to ensure they have more time available for these tasks. Experimentation is critical to SRE. SREs need the license to prioritize strategic work.
As organizations continue to migrate to the cloud, it’s important to get in front of performance issues, such as high latency, low throughput, and replication lag with higher distances between your users and cloud infrastructure.
This article analyzes cloud workloads, delving into their forms, functions, and how they influence the cost and efficiency of your cloud infrastructure. All rely heavily on utilizing allocated portions from existing pools made available through specific providers as part of their service offerings.
As Kinsta’s DevOps Engineer, you will be instrumental in making sure that our infrastructure is always on the bleeding edge of technology, remaining stable and high-performing at all times. No more hassles of benchmarking and tuning algorithms or building and maintaining infrastructure for vector search.
As Kinsta’s DevOps Engineer, you will be instrumental in making sure that our infrastructure is always on the bleeding edge of technology, remaining stable and high-performing at all times. No more hassles of benchmarking and tuning algorithms or building and maintaining infrastructure for vector search.
As Kinsta’s DevOps Engineer, you will be instrumental in making sure that our infrastructure is always on the bleeding edge of technology, remaining stable and high-performing at all times. No more hassles of benchmarking and tuning algorithms or building and maintaining infrastructure for vector search.
As Kinsta’s DevOps Engineer, you will be instrumental in making sure that our infrastructure is always on the bleeding edge of technology, remaining stable and high-performing at all times. No more hassles of benchmarking and tuning algorithms or building and maintaining infrastructure for vector search.
This post mines publicly available data on the pace of compatibility fixes and feature additions to assess the claim. As an engineer on a browser team, I'm privy to the blow-by-blow of various performance projects, benchmark fire drills, and the ways performance marketing (deeply) impacts engineering priorities. Higher is better.
Traditional self-managed ones give organizations full control over their database infrastructure, such as picking the software and scaling it up. Thereby streamlining their database infrastructure without any major complications or stress accompanying doing the same effectively resulting in fewer worries when setting out sail onboard!
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content