This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Twilio is a call management system that provides excellent call recording capabilities, but often organizations are in need of automatically downloading and storing these recordings locally or in their preferred cloud storage. However, downloading large numbers of recordings from Twilio can be challenging.
One key factor that significantly affects the performance of data processing is the storage format of the data. This article explores the impact of different storage formats, specifically Parquet, Avro, and ORC on query performance and costs in big data environments on Google Cloud Platform (GCP).
At this scale, we can gain a significant amount of performance and cost benefits by optimizing the storage layout (records, objects, partitions) as the data lands into our warehouse. We built AutoOptimize to efficiently and transparently optimize the data and metadata storage layout while maximizing their cost and performance benefits.
This article analyzes the correlation between block sizes and their impact on storage performance. This paper deals with definitions and understanding of structured data vs unstructured data, how various storage segments react to block size changes, and differences between I/O-driven and throughput-driven workloads.
In this article, Rogerio Robetti discusses the challenges in auto-scaling stateful storage systems and proposes an opinionated design solution to automatically scale up (vertical) and scale out (horizontal) from a single node up to several nodes in a cluster with minimum configuration and interference of the operator.
A horizontally scalable exabyte-scale blob storage system which operates out of multiple regions, Magic Pocket is used to store all of Dropbox’s data. Adopting SMR technology and erasure codes, the system has extremely high durability guarantees but is cheaper than operating in the cloud. By Facundo Agriel
In this article, I will walk through a comprehensive end-to-end architecture for efficient multimodal data processing while striking a balance in scalability, latency, and accuracy by leveraging GPU-accelerated pipelines, advanced neural networks , and hybrid storage platforms.
It is the second of a series of articles that is built on top of that project, representing experiments with various statistical and machine learning models, data pipelines implemented using existing DAG tools, and storage services, both cloud-based and alternative on-premises solutions.
Data migration involves transferring data from on-premise storage to the cloud. This article discusses the challenges and best practices of data migration when transferring on-premise data to the cloud. This article discusses the challenges and best practices of data migration when transferring on-premise data to the cloud.
To resolve the problem it was suggested to find more suitable data storage. It is a key problem which we will try to resolve in this article. For some internal reasons well known Amazon S3 bucket was chosen for this purpose. The choice affected the project's unit test base.
This article outlines the key differences in architecture, performance, and use cases to help determine the best fit for your workload. Message brokers handle validation, routing, storage, and delivery, ensuring efficient and reliable communication. What is RabbitMQ?
High performance, query optimization, open source and polymorphic data storage are the major Greenplum advantages. Polymorphic Data Storage. Greenplum’s polymorphic data storage allows you to control the configuration for your table and partition storage with the freedom to execute and compress files within it at any time.
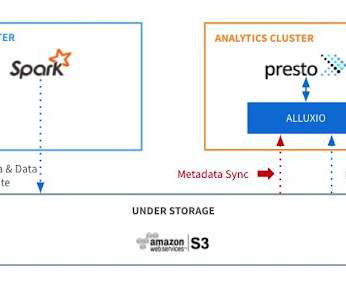
Metadata synchronization (sync) is a core feature in Alluxio that keeps files and directories consistent with their source of truth in under-storage systems, thus making it simple for users to reason the data retrieved from Alluxio. This article describes the design and the implementation in Alluxio to keep metadata synchronized.
It is the first of a series of articles that will be built on top of that project, representing experiments with various statistical and machine learning models, data pipelines implemented using existing DAG tools, and storage services, both cloud-based and alternative on-premises solutions.
We often dwell on the technical aspects of database selection, focusing on performance metrics , storage capacity, and querying capabilities. In a detailed article, we've discussed how to align a NoSQL database with specific business needs.
In this article, we will delve into strategies to ensure that your data pipeline is resource-efficient, cost-effective, and time-efficient. Spark takes full advantage of this storage property by exclusively reading the columns that are involved in subsequent computations.
Users can allocate different storage tiers as the resources for Alluxio workers, including MEM/SSD/HDD, which are further composed of directories. In this article, we analyze the policies of block allocation from the source code. Alluxio workers are responsible for managing local resources, and they store data as blocks.
Moreover, the process of collecting these profiles introduces overhead during application runtime and necessitates the storage and visualization of significantly large datasets. This article explores the concept of low overhead high-frequency profilers, which offer a solution to these challenges.
The load testing for the database needs to be conducted usually so that the impact on the system can be monitored in different scenarios, such as query language rule optimization, storage engine parameter adjustment, etc. The operating system in this article is the x86 CentOS 7.8.
What’s in this article? JSONB storage has some drawbacks vs. traditional columns: PostreSQL does not store column statistics for JSONB columns. JSONB storage results in a larger storage footprint. JSONB storage does not deduplicate the key names in the JSON. Why Store JSON in PostgreSQL? JSONB Indexes.
This article explores the concepts of Medallion Architecture and demonstrates how to implement batch and stream processing pipelines using Azure Databricks and Delta Lake. In Azure Databricks, this architecture can be implemented using Delta Lake to provide reliable data storage and processing capabilities.
This article will explore how these technologies can be used together to create an optimized data pipeline for data processing in the cloud. It provides built-in connectors for various data sources such as databases, file systems, cloud storage, and more.
Taking a proactive and efficient approach to Kubernetes cluster monitoring can help engineering teams identify and predict many critical problems like CPU outage, memory outage, storage issues well in advance of these issues taking a toll on a business.
In this article we’ll share highlights about two increments that are likely to fall into the “barely noticeable” category. Easier rollout thanks to log storage best practices. Easier rollout thanks to log storage best practices. What does this mean for existing installations? No problem.
In this article, we are going to compare three of the most popular cloud providers, AWS vs. Azure vs. DigitalOcean for their database hosting costs for MongoDB® database to help you decide which cloud is best for your business. DigitalOcean using the below instance types: AWS. EC2 instances. VM instances. DigitalOcean.
Our goal was to build a versatile and efficient data storage solution that could handle a wide variety of use cases, ranging from the simplest hashmaps to more complex data structures, all while ensuring high availability, tunable consistency, and low latency. Developers just provide their data problem rather than a database solution!
AI requires more compute and storage. Training AI data is resource-intensive and costly, again, because of increased computational and storage requirements. As a result, AI observability supports cloud FinOps efforts by identifying how AI adoption spikes costs because of increased usage of storage and compute resources.
They've posted about Anna's new superpowers in Going Fast and Cheap: How We Made Anna Autoscale : Using Anna v0 as an in-memory storage engine, we set out to address the cloud storage problems described above. Each storage server collects statistics about the requests it serves, the data it stores, etc. Related Articles.
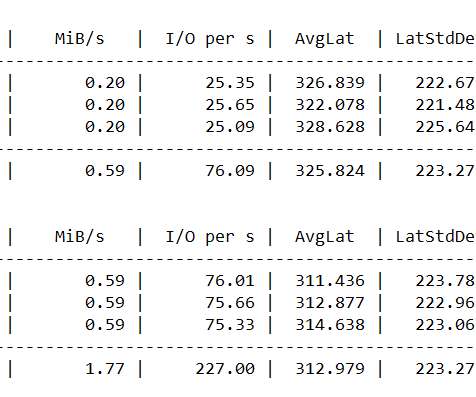
In this article, we will learn how to test our storage subsystems performance using Diskspd. The storage subsystem is one of the key performance factors for SQL Server because SQL Server storage engine stores database objects, tables, and indexes on the physical files.
If you’re responsible for maintaining your organization’s OneAgent install process or you have particular interest in the OneAgent file footprint on your monitored hosts, this article is for you. You can read about these prior enhancements in the dedicated article. You can read about how this works in Dynatrace Help.
To share more thoughts and experiments on how Alluxio enhances Spark workloads, this article focuses on how Alluxio helps to optimize the memory utilization of Spark applications. Improve your Spark memory. In the previous tutorial , we demonstrated how to get started with Spark and Alluxio.
BindPlane OP is a powerful open-source tool that makes it easy to build and manage telemetry pipelines to ship data from IT environments of any kind and size to any analysis tool or storage destination.
This article explains what a software supply chain attack is, and how Dynatrace protects its customers against such attacks by applying: Risk management and business continuity planning. Every storage location involving data at rest is encrypted as well. Dynatrace news. Security controls in the software development life cycle (SDL).
While it encompasses many functionalities, the article will focus on Managed Identities. For instance, for a storage account named "Foo", its connection string might be "Bar". Azure Entra Id , formerly Azure Active Directory is a comprehensive Identity and Access Management offering from Microsoft. Why Managed Identities?
One of the top trending open-source data storage that responds to most of the use cases is Elasticsearch. Elasticsearch is a distributed data storage and search engine with fault-tolerance and high availability capabilities. This article will focus on the search intensive initial and dynamic configurations of the Elasticsearch.
The KV DAL allows applications to use a well-defined and storage engine agnostic HTTP/gRPC key-value data interface that in turn decouples applications from hard to maintain and backwards-incompatible datastore APIs. As most key-value storage engines support efficiently deleting a namespace (e.g.
Details pertaining to HDR-VMAF exceed the scope of this article and will be covered in a future blog post; for now, suffice it to say that the first version of HDR-VMAF landed internally in 2021 and we have been improving the metric ever since. Summary Thanks to the arrival of HDR-VMAF, we were able to optimize our HDR encodes.
In this article, we take a closer look at Prometheus metrics and how we can ingest this data into Dynatrace. But often, we use additional services and solutions within our environment for backups, storage, networking, and more. As for the Collector, this will be the choice of tool for our implementation and this article.
They support PostgreSQL, MySQL and Redis, but for the sake of this article, we are going to focus on their PostgreSQL product. On average, ScaleGrid provides over 30% more storage vs. DigitalOcean for PostgreSQL at the same affordable price. So, which database service is right for your application? Compare Pricing. Instance Type/RAM.
An open-source distributed SQL query engine, Trino is widely used for data analytics on distributed data storage. In this article, we will show you how to tune Trino by helping you identify performance bottlenecks and provide tuning tips that you can practice. But how do we do that?
In this article I provide a short comparison of NoSQL system families from the data modeling point of view and digest several common modeling techniques. I would like to thank Daniel Kirkdorffer who reviewed the article and cleaned up the grammar. The rest of this article describes concrete data modeling techniques and patterns.
Data engineering projects often require the setup and management of complex infrastructures that support data processing, storage, and analysis. In this article, we will explore the benefits of leveraging IaC for data engineering projects and provide detailed implementation steps to get started.
Nevertheless, there are related components and processes, for example, virtualization infrastructure and storage systems (see image below), that can lead to problems in your Kubernetes infrastructure. Configuring storage in Kubernetes is more complex than using a file system on your host.
Inputs These are the following instances that we will start with: AWS RDS for MySQL in us-east-1 10 x db.r5.4xlarge 200 GB storage each The cost of RDS consists mostly of two things – compute and storage. We will not consider data transfer or backup costs in this article. EBS gp2 storage is $0.10 hour or $46.08/day
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content