This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In this article, I will walk through a comprehensive end-to-end architecture for efficient multimodal data processing while striking a balance in scalability, latency, and accuracy by leveraging GPU-accelerated pipelines, advanced neural networks , and hybrid storage platforms.
This article outlines the key differences in architecture, performance, and use cases to help determine the best fit for your workload. Message brokers handle validation, routing, storage, and delivery, ensuring efficient and reliable communication. What is RabbitMQ?
At this scale, we can gain a significant amount of performance and cost benefits by optimizing the storage layout (records, objects, partitions) as the data lands into our warehouse. We built AutoOptimize to efficiently and transparently optimize the data and metadata storage layout while maximizing their cost and performance benefits.
In this article, we are going to compare three of the most popular cloud providers, AWS vs. Azure vs. DigitalOcean for their database hosting costs for MongoDB® database to help you decide which cloud is best for your business. Does it affect latency? Yes, you can see an increase in latency. EC2 instances. VM instances.
These include challenges with tail latency and idempotency, managing “wide” partitions with many rows, handling single large “fat” columns, and slow response pagination. It also serves as central configuration of access patterns such as consistency or latency targets. Useful for keeping “n-newest” or prefix path deletion.
We often dwell on the technical aspects of database selection, focusing on performance metrics , storage capacity, and querying capabilities. In a detailed article, we've discussed how to align a NoSQL database with specific business needs. Factors like read and write speed, latency, and data distribution methods are essential.
In order to gain insight into these problems, we gather a range of metrics and logs to monitor the utilization of system resources such as CPU, memory, and application-specific latencies. This article explores the concept of low overhead high-frequency profilers, which offer a solution to these challenges.
They support PostgreSQL, MySQL and Redis, but for the sake of this article, we are going to focus on their PostgreSQL product. Compare Latency. lower latency compared to DigitalOcean for PostgreSQL. On average, ScaleGrid provides over 30% more storage vs. DigitalOcean for PostgreSQL at the same affordable price.
AI requires more compute and storage. Training AI data is resource-intensive and costly, again, because of increased computational and storage requirements. As a result, AI observability supports cloud FinOps efforts by identifying how AI adoption spikes costs because of increased usage of storage and compute resources.
The data warehouse is not designed to serve point requests from microservices with low latency. Therefore, we must efficiently move data from the data warehouse to a global, low-latency and highly-reliable key-value store. As most key-value storage engines support efficiently deleting a namespace (e.g.
They've posted about Anna's new superpowers in Going Fast and Cheap: How We Made Anna Autoscale : Using Anna v0 as an in-memory storage engine, we set out to address the cloud storage problems described above. Each storage server collects statistics about the requests it serves, the data it stores, etc. Related Articles.
Since that presentation, Pushy has grown in both size and scope, and this article will be discussing the investments we’ve made to evolve Pushy for the next generation of features. KeyValue is an abstraction over the storage engine itself, which allows us to choose the best storage engine that meets our SLO needs.
But we cannot search or present low latency retrievals from files Etc. We refer the reader to our previous blog article for details. Using memcache allows us to keep latencies for our search low (most of our queries are less than 100ms). This is obviously very expensive. Write algo runs into files.
In addition, compute and storage are increasingly being separated causing larger latencies for queries. Alluxio is leveraged as compute-side virtual storage to improve performance. The Apache Spark + Alluxio stack is getting quite popular particularly for the unification of data access across S3 and HDFS.
How To Design For High-Traffic Events And Prevent Your Website From Crashing How To Design For High-Traffic Events And Prevent Your Website From Crashing Saad Khan 2025-01-07T14:00:00+00:00 2025-01-07T22:04:48+00:00 This article is sponsored by Cloudways Product launches and sales typically attract large volumes of traffic.
You may also know that this has led to an increase in the demand for efficient and secure data storage solutions that won’t break the bank. This article will explore what edge data platforms and real-time services are, why they are important, and how they can be used.
In this article I’m trying to provide more or less systematic description of techniques related to distributed operations in NoSQL databases. In the rest of this article we study a number of distributed activities like replication of failure detection that could happen in a database. Read/Write latency. Data Placement.
In this article, we’ll explore the benefits of using Docker images for experimenting with serverless PostgreSQL and show you how to get started with them. Basically, you can view this as a PostgreSQL instance but without a storage layer Storage Broker Storage Broker is a coordination component between WAL Service and Pageserver.
This article explains how we designed microservices and workflows on top of the Cosmos platform to bolster such video quality innovations. This enables us to use our scale to increase throughput and reduce latencies. Here, based on the video length, the throughput and latency requirements, available scale etc.,
This article will explore how they handle data storage and scalability, perform in different scenarios, and, most importantly, how these factors influence your choice. It uses a hash table to manage these pairs, divided into fixed-size buckets with linked lists for key-value storage.
My personal opinion is that I don't see a widespread need for more capacity given horizontal scaling and servers that can already exceed 1 Tbyte of DRAM; bandwidth is also helpful, but I'd be concerned about the increased latency for adding a hop to more memory. Or even on a plane. Ford, et al., “TCP
Performance Benchmarking of PostgreSQL on ScaleGrid vs. AWS RDS Using Sysbench This article evaluates PostgreSQL’s performance on ScaleGrid and AWS RDS, focusing on versions 13, 14, and 15. Network Latency : We ran both machines in the same region and conducted the tests from within the same box in that region.
This article analyzes cloud workloads, delving into their forms, functions, and how they influence the cost and efficiency of your cloud infrastructure. Storage is a critical aspect to consider when working with cloud workloads. What is an example of a workload?
This article will explore hybrid cloud benefits and steps to craft a plan that aligns with your unique business challenges. Managing Costs Lower storage expenses in the public cloud and the ability to scale resources as needed enhance the cost-effectiveness of a hybrid cloud environment compared to on-premises infrastructure.
Caching partially stores your data and is not used as permanent storage. Using the cache as permanent storage is an anti-pattern. Server caches help lower the latency between a Frontend and Backend; since key-value databases are faster than traditional relational SQL databases, it will significantly increase an API’s response time.
This article is an effort to explore techniques used by developers of in-stream data processing systems, trace the connections of these techniques to massive batch processing and OLTP/OLAP databases, and discuss how one unified query engine can support in-stream, batch, and OLAP processing at the same time. Interoperability with Hadoop.
This approach often leads to heavyweight high-latency analytical processes and poor applicability to realtime use cases. In this article, I provide an overview of probabilistic data structures that allow one to estimate these and many other metrics and trade precision of the estimations for the memory consumption. Case Study.
The General Purpose tier is designed for applications with typical performance and I/O latency requirements and provides built-in HA. The Business Critical tier is designed for applications that require low I/O latency and higher HA requirements. For this article, I'll only be covering configurations using the Gen5 processors.
In this article, we will explore what RabbitMQ is, its mechanisms to facilitate message queueing, its role within software architectures, and the tangible benefits it delivers in real-world scenarios. This includes acknowledgments confirming both publishing actions and storage on disk.
This article delves into the specifics of how AI optimizes cloud efficiency, ensures scalability, and reinforces security, providing a glimpse at its transformative role without giving away extensive details. Exploring artificial intelligence in cloud computing reveals a game-changing synergy.
The basic tier provides up to 5 DTUs with standard storage. The standard tier supports from 10 up to 3000 DTUs with standard storage and the premium tier supports 125 up to 4000 DTUs with premium storage, which is orders of magnitude faster than standard storage. vCore Pricing Tier. GB per vCore. HyperScale Database.
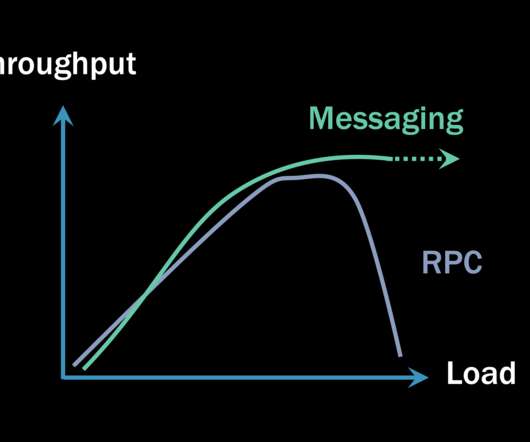
Some will claim that any type of RPC communication ends up being faster (meaning it has lower latency) than any equivalent invocation using asynchronous messaging. There are more steps, so the increased latency is easily explained. However, no matter the specific word used, the meaning is the same: remote method calls over HTTP.
This article dives straight into what triggers a rollback in MongoDB, the risks it carries, and concrete steps you can take to both prevent and recover from one. Data-bearing members face a higher risk of encountering issues caused by rollbacks, compared to others who utilize different storage methods.
For instance, in SmashingMag’s Twitter account , the article’s featured image has a customized and consistent style, giving it a unique personality: Smashing Magazine’s article shared on Twitter ( Large preview ). For this article, I’ll be using its integration with WordPress and its plugin for WordPress v3.0 Let’s start!
In an in-depth article on Streaming Media Dan Rayburn analyzed the impact of Amazon Cloudfront move to GA: Amazons CDN Gets More Competitive, Adds SLA, New Edge Locations, Lower Pricing. Understanding Throughput-Oriented Architectures - background article in CACM on massively parallel and throughput vs latency oriented architectures.
This operation is quite expensive but our database can run it in a few milliseconds or less, thanks to several optimizations that allow the node to execute most of them in memory with no or little access to mass storage. If there is no distinction in the article between a simple database and an RDBMS, run away.
First, some stage-setting for this blog article. Redis can handle a high volume of operations per second, making it useful for running applications that require low latency. Storing large datasets can be a challenge, as Redis’ storage capacity is limited by available RAM. It ranks No.
faster access to external storage and data locality (I/O, bandwidth). Storage provisioning. Storage options have been another big roadblock in porting data workloads on Kubernetes particularly for stateful data workloads like Zookeeper, Cassandra, etc. But Kubernetes storage is evolving quite quickly. Final thoughts.
I laid out some of these challenges in an article explaining the concept of eventual consistency. Achieving strict consistency can come at a cost in update or read latency, and may result in lower throughput. Lowest read latency. Higher read latency. Driving Storage Costs Down for AWS Customers. Consistent read.
My personal opinion is that I don't see a widespread need for more capacity given horizontal scaling and servers that can already exceed 1 Tbyte of DRAM; bandwidth is also helpful, but I'd be concerned about the increased latency for adding a hop to more memory. Or even on a plane. Ford, et al., “TCP
which provides saga and outbox storage for NServiceBus endpoints that is transactionally consistent with the business data you store in Cosmos DB. But where Cosmos DB really shines is for systems that require worldwide low latency with flexible pricing. Cosmos DB is clearly positioned as the successor to Azure Table storage.
Back on December 5, 2017, Microsoft announced that they were using AMD EPYC 7551 processors in their storage-optimized Lv2-Series virtual machines. These AMD EPYC processors have a number of advantages for SQL Server workloads, as I will explain in this article. Since then, Microsoft has changed the naming of this series to Lsv2.
A then-representative $200USD device had 4-8 slow (in-order, low-cache) cores, ~2GiB of RAM, and relatively slow MLC NAND flash storage. Sadly, data on latency is harder to get, even from Google's perch, so progress there is somewhat more difficult to judge. The Moto G4 , for example.
It simulates a link with a 400ms RTT and 400-600Kbps of throughput (plus latency variability and simulated packet loss). Simulated packet loss and variable latency, however, can make benchmarking extremely difficult and slow. Our baseline, then, should probably trade lower throughput/higher-latency for packet loss.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content