This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Enhancing data separation by partitioning each customer’s data on the storage level and encrypting it with a unique encryption key adds an additional layer of protection against unauthorized data access. A unique encryption key is applied to each tenant’s storage and automatically rotated every 365 days.
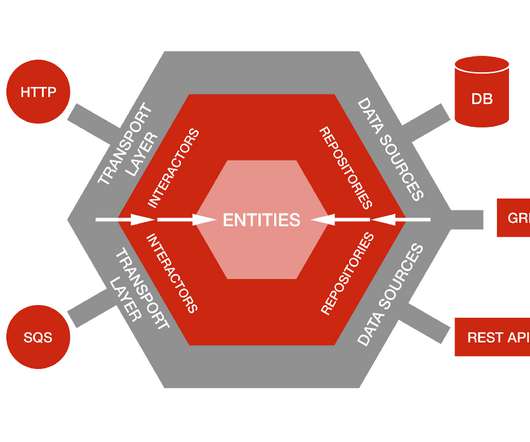
We had an interesting challenge on our hands: we needed to build the core of our app from scratch, but we also needed data that existed in many different systems. Leveraging Hexagonal Architecture We needed to support the ability to swap data sources without impacting business logic , so we knew we needed to keep them decoupled.
This article outlines the key differences in architecture, performance, and use cases to help determine the best fit for your workload. RabbitMQ follows a message broker model with advanced routing, while Kafkas event streaming architecture uses partitioned logs for distributed processing.
But this also caused storage challenges like disk failures and data recovery. To avoid extensive maintenance, we adopted JuiceFS, a distributed file system with high performance. We innovatively use its snapshot feature to implement a primary-replica architecture for ClickHouse.
Part 3: System Strategies and Architecture By: VarunKhaitan With special thanks to my stunning colleagues: Mallika Rao , Esmir Mesic , HugoMarques This blog post is a continuation of Part 2 , where we cleared the ambiguity around title launch observability at Netflix. The request schema for the observability endpoint.
Multimodal data processing is the evolving need of the latest data platforms powering applications like recommendation systems, autonomous vehicles, and medical diagnostics. Handling multimodal data spanning text, images, videos, and sensor inputs requires resilient architecture to manage the diversity of formats and scale.
It requires a state-of-the-art system that can track and process these impressions while maintaining a detailed history of each profiles exposure. In this multi-part blog series, we take you behind the scenes of our system that processes billions of impressions daily.
Without observability, the benefits of ARM are lost Over the last decade and a half, a new wave of computer architecture has overtaken the world. ARM architecture, based on a processor type optimized for cloud and hyperscale computing, has become the most prevalent on the planet, with billions of ARM devices currently in use.
After selecting a mode, users can interact with APIs without needing to worry about the underlying storage mechanisms and counting methods. Failures in a distributed system are a given, and having the ability to safely retry requests enhances the reliability of the service.
At this scale, we can gain a significant amount of performance and cost benefits by optimizing the storage layout (records, objects, partitions) as the data lands into our warehouse. We built AutoOptimize to efficiently and transparently optimize the data and metadata storage layout while maximizing their cost and performance benefits.
A distributed storagesystem is foundational in today’s data-driven landscape, ensuring data spread over multiple servers is reliable, accessible, and manageable. This guide delves into how these systems work, the challenges they solve, and their essential role in businesses and technology.
In this blog post, we explain what Greenplum is, and break down the Greenplum architecture, advantages, major use cases, and how to get started. It’s architecture was specially designed to manage large-scale data warehouses and business intelligence workloads by giving you the ability to spread your data out across a multitude of servers.
Messaging systems can significantly improve the reliability, performance, and scalability of the communication processes between applications and services. In serverless and microservices architectures, messaging systems are often used to build asynchronous service-to-service communication. Dynatrace news. This is great!
To get a better understanding of AWS serverless, we’ll first explore the basics of serverless architectures, review AWS serverless offerings, and explore common use cases. Serverless architecture: A primer. Serverless architecture shifts application hosting functions away from local servers onto those managed by providers.
Scaling RabbitMQ ensures your system can handle growing traffic and maintain high performance. Key Takeaways RabbitMQ improves scalability and fault tolerance in distributed systems by decoupling applications, enabling reliable message exchanges.
Grail architectural basics. The aforementioned principles have, of course, a major impact on the overall architecture. A data lakehouse addresses these limitations and introduces an entirely new architectural design. This decoupling ensures the openness of data and storage formats, while also preserving data in context.
Engineers want their alerting system to be realtime, reliable, and actionable. A few years ago, we were paged by our SRE team due to our Metrics Alerting System falling behind — critical application health alerts reached engineers 45 minutes late! In other words, false positives are bad but false negatives are the absolute worst!
A horizontally scalable exabyte-scale blob storagesystem which operates out of multiple regions, Magic Pocket is used to store all of Dropbox’s data. Adopting SMR technology and erasure codes, the system has extremely high durability guarantees but is cheaper than operating in the cloud. By Facundo Agriel
Table 1: Movie and File Size Examples Initial Architecture A simplified view of our initial cloud video processing pipeline is illustrated in the following diagram. Lastly, the packager kicks in, adding a system layer to the asset, making it ready to be consumed by the clients.
Architecture. The streaming data store makes the system extensible to support other use-cases (e.g. System Components. The system will comprise of several micro-services each performing a separate task. After that, the post gets added to the feed of all the followers in the columnar data storage. High Level Design.
In this post, we dive deep into how Netflix’s KV abstraction works, the architectural principles guiding its design, the challenges we faced in scaling diverse use cases, and the technical innovations that have allowed us to achieve the performance and reliability required by Netflix’s global operations.
Behind the scenes, a myriad of systems and services are involved in orchestrating the product experience. These backend systems are consistently being evolved and optimized to meet and exceed customer and product expectations. This blog series will examine the tools, techniques, and strategies we have utilized to achieve this goal.
Modern IT environments — whether multicloud, on-premises, or hybrid-cloud architectures — generate exponentially increasing data volumes. Teams have introduced workarounds to reduce storage costs. Stop worrying about log data ingest and storage — start creating value instead. Limited data availability constrains value creation.
FaaS vs. monolithic architectures. Monolithic architectures were commonplace with legacy, on-premises software solutions. Infrastructure as a service (IaaS) handles compute, storage, and network resources. Because a third party manages part of the infrastructure, IT teams give up a measure of control over systemarchitecture.
Application and system logs are often collected in data silos using different tools, with no relationships between them, and then correlated in manual and often meaningless ways. Further, these resources support countless Kubernetes clusters and Java-based architectures. Clearly, this works against the goal of digital transformation.
Specifically, we will dive into the architecture that powers search capabilities for studio applications at Netflix. We implemented a batch processing system for users to submit their requests and wait for the system to generate the output. Maintaining disparate systems posed a challenge.
Therefore, they need an environment that offers scalable computing, storage, and networking. Hyperconverged infrastructure (HCI) is an IT architecture that combines servers, storage, and networking functions into a unified, software-centric platform to streamline resource management. What is hyperconverged infrastructure?
Traditional analytics and AI systems rely on statistical models to correlate events with possible causes. It removes much of the guesswork of untangling complex system issues and establishes with certainty why a problem occurred. Fragmented and siloed data storage can create inconsistencies and redundancies. Timeliness.
Complex information systems fail in unexpected ways. Observability gives developers and system operators real-time awareness of a highly distributed system’s current state based on the data it generates. With observability, teams can understand what part of a system is performing poorly and how to correct the problem.
The new architecture enables more granularity in permission management and provides the dynamics necessary to serve modern access management use cases. We’ve replaced the role-based permission system with security policies that provide fine-grained control over service access and introduce new dynamic controls for user authorization.
Simpler UI Testing with CasperJS ( Architects Zone – Architectural Design Patterns & Best Practices). Using MongoDB as a cache store ( Architects Zone – Architectural Design Patterns & Best Practices). Linux System Mining with Python ( Javalobby – The heart of the Java developer community). Hacker News).
That’s because of the heterogeneity of the data their environments generate and the limitations of the systems they rely on to analyze this information. Research has found that 99% of organizations have embraced a multicloud architecture. What is DevOps maturity?
Trace your application Imagine a microservices architecture with hundreds of dependencies. There is no need to think about schema and indexes, re-hydration, or hot/cold storage. This architecture also means you’re not required to determine your log data use cases beforehand or while analyzing logs within the new logs app.
Having a distributed and scalable graph database system is highly sought after in many enterprise scenarios. Do Not Be Misled Designing and implementing a scalable graph database system has never been a trivial task.
The rise of cloud-native microservice architectures further exacerbates this change. Moreover, the system lacks flexibility, imposing strict schemas that administrators and developers must adhere to avoid additional costs. All data is readily accessible without storage tiers, such as costly solid-state drives (SSDs).
Before we dive into the technical implementation, let me explain the visual concept of this “Global Status Page”: Another requirement for this status page was that it has to be lightweight, with no data storage at all. Lightweight architecture. This is where the consolidated API, which I presented in my last post , comes into play.
Building an elastic query engine on disaggregated storage , Vuppalapati, NSDI’20. have altered the many assumptions that guided the design and optimization of the Snowflake system. The caching use case may be the most familiar, but in fact it’s not the primary purpose of the ephemeral storage service.
Teams can then act before attackers have the chance to compromise key data or bring down critical systems. This data helps teams see where attacks began, which systems were targeted, and what techniques attackers used. Proactive protection, however, focuses on finding evidence of attacks before they compromise key systems.
In previous blog posts, we introduced the Key-Value Data Abstraction Layer and the Data Gateway Platform , both of which are integral to Netflix’s data architecture. Note: Contrary to what the name may suggest, this system is not built as a general-purpose time series database.
As Kubernetes adoption increases and it continues to advance technologically, Kubernetes has emerged as the “operating system” of the cloud. Kubernetes is emerging as the “operating system” of the cloud. Kubernetes is emerging as the “operating system” of the cloud. Kubernetes moved to the cloud in 2022.
Organizations need to unify all this observability, business, and security data based on context and generate real-time insights to inform actions taken by automation systems, as well as business, development, operations, and security teams. Systems automatically generate logs, which record events that took place. Event severity.
RISELabs , those wonderfully innovative folks over at Berkeley, have uplifted their Anna datatabase —a shared-nothing, thread-per-core architecture to achieve lightning-fast speeds by avoiding all coordination mechanisms—to become cloud-aware. While database neogenesis has slowed down considerably, it has not gone necrotic.
In contrast to modern software architecture, which uses distributed microservices, organizations historically structured their applications in a pattern known as “monolithic.” When an application runs on a single large computing element, a single operating system can monitor every aspect of the system.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content