This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
After selecting a mode, users can interact with APIs without needing to worry about the underlying storage mechanisms and counting methods. Let’s examine some of the drawbacks of this approach: Lack of Idempotency : There is no idempotency key baked into the storage data-model preventing users from safely retrying requests.
It can scale towards a multi-petabyte level data workload without a single issue, and it allows access to a cluster of powerful servers that will work together within a single SQL interface where you can view all of the data. The Greenplum Architecture. The Greenplum Architecture. Greenplum Architectural Design.
This article outlines the key differences in architecture, performance, and use cases to help determine the best fit for your workload. RabbitMQ follows a message broker model with advanced routing, while Kafkas event streaming architecture uses partitioned logs for distributed processing. What is RabbitMQ? What is Apache Kafka?
To get a better understanding of AWS serverless, we’ll first explore the basics of serverless architectures, review AWS serverless offerings, and explore common use cases. Serverless architecture: A primer. Serverless architecture shifts application hosting functions away from local servers onto those managed by providers.
Architecture Overview The first pivotal step in managing impressions begins with the creation of a Source-of-Truth (SOT) dataset. These events are promptly relayed from the client side to our servers, entering a centralized event processing queue. This queue ensures we are consistently capturing raw events from our global userbase.
The Grail architecture ensures scalability, making log data accessible for detailed analysis regardless of volume. Dynatrace Grail lets you focus on extracting insights rather than managing complex schemas or index and storage concepts. With real-time analysis, you gain faster data-driven decisions and simplified data ingestion.
It is the second of a series of articles that is built on top of that project, representing experiments with various statistical and machine learning models, data pipelines implemented using existing DAG tools, and storage services, both cloud-based and alternative on-premises solutions.
In this post, we dive deep into how Netflix’s KV abstraction works, the architectural principles guiding its design, the challenges we faced in scaling diverse use cases, and the technical innovations that have allowed us to achieve the performance and reliability required by Netflix’s global operations.
Therefore, they need an environment that offers scalable computing, storage, and networking. Hyperconverged infrastructure (HCI) is an IT architecture that combines servers, storage, and networking functions into a unified, software-centric platform to streamline resource management. What is hyperconverged infrastructure?
A distributed storage system is foundational in today’s data-driven landscape, ensuring data spread over multiple servers is reliable, accessible, and manageable. Understanding distributed storage is imperative as data volumes and the need for robust storage solutions rise.
Cloud providers then manage physical hardware, virtual machines, and web server software management. This code is then executed on remote servers in response to an event, such as users interacting with functional web elements. FaaS vs. monolithic architectures. But how does FaaS fit in? Increased availability.
Architecture. When the server receives a request for an action (post, like etc.) Firstly, the synchronous process which is responsible for uploading image content on file storage, persisting the media metadata in graph data-storage, returning the confirmation message to the user and triggering the process to update the user activity.
Continuous cloud monitoring with automation provides clear visibility into the performance and availability of websites, files, applications, servers, and network resources. Cloud-server monitoring. Cloud storage monitoring. While hybrid and multicloud environments are often lumped together, they are not the same.
When undertaking system migrations, one of the main challenges is establishing confidence and seamlessly transitioning the traffic to the upgraded architecture without adversely impacting the customer experience. These include options where replay traffic generation is orchestrated on the device, on the server, and via a dedicated service.
IT infrastructure is the heart of your digital business and connects every area – physical and virtual servers, storage, databases, networks, cloud services. This shift requires infrastructure monitoring to ensure all your components work together across applications, operating systems, storage, servers, virtualization, and more.
In previous blog posts, we introduced the Key-Value Data Abstraction Layer and the Data Gateway Platform , both of which are integral to Netflix’s data architecture. Storage Layer The storage layer for TimeSeries comprises a primary data store and an optional index data store.
RISELabs , those wonderfully innovative folks over at Berkeley, have uplifted their Anna datatabase —a shared-nothing, thread-per-core architecture to achieve lightning-fast speeds by avoiding all coordination mechanisms—to become cloud-aware. While database neogenesis has slowed down considerably, it has not gone necrotic.
Cloud-native technologies and microservice architectures have shifted technical complexity from the source code of services to the interconnections between services. Heterogeneous cloud-native microservice architectures can lead to visibility gaps in distributed traces. Dynatrace news.
Today’s digital businesses run on heterogeneous and highly dynamic architectures with interconnected applications and microservices deployed via Kubernetes and other cloud-native platforms. Common questions include: Where do bottlenecks occur in our architecture? Dynatrace news. How can we optimize for performance and scalability?
One key requirement of a microservices architecture is the ability to make information of all kinds available wherever and whenever it’s needed, without putting undue traffic on corporate and public networks. Apply Davis AI to your TIBCO EMS servers. Synchronous storage size. Async storage size. Storage read size rate.
Traditionally, though, to gain true business insight, organizations had to make tradeoffs between accessing quality, real-time data and factors such as data storage costs. Additionally, it provides index-free storage and direct analytics access to source data without requiring data rehydration. Don’t reinvent the wheel.
Metrics are measures of critical system values, such as CPU utilization or average write latency to persistent storage. They are particularly important in distributed systems, such as microservices architectures. Observability platforms are becoming essential as the complexity of cloud-native architectures increases.
On-premises data centers invest in higher capacity servers since they provide more flexibility in the long run, while the procurement price of hardware is only one of many cost factors. Redis is an in-memory key-value store and cache that simplifies processing, storage, and interaction with data in Kubernetes environments.
Problems include provisioning and deployment; load balancing; securing interactions between containers; configuration and allocation of resources such as networking and storage; and deprovisioning containers that are no longer needed. How does container orchestration work? The post What is container orchestration?
Besides the traditional system hardware, storage, routers, and software, ITOps also includes virtual components of the network and cloud infrastructure. Computer operations manages the physical location of the servers — cooling, electricity, and backups — and monitors and responds to alerts.
I see a tremendous interest in examples how to build such applications, and articles such as " The Serverless Start-Up - Down With Servers! If you are looking for more examples there are the Lambda Serverless Reference Architectures that can serve as the blueprint for building your own serverless applications. about teletext.io
Typically, these are streamed to a central syslog server. One option is to install OneAgent on that syslog server, which automatically discovers, instruments and sends the log data to the Dynatrace platform. In the “Storage and Logging” section, select “ awsfirelens ” as the log driver.
I see a tremendous interest in examples how to build such applications, and articles such as " The Serverless Start-Up - Down With Servers! If you are looking for more examples there are the Lambda Serverless Reference Architectures that can serve as the blueprint for building your own serverless applications. about teletext.io
Whether you need a relational database for complex transactions or a NoSQL database for flexible data storage, weve got you covered. MongoDB is a NoSQL database designed for unstructured data, offering flexibility and scalability with a schemaless architecture, making it suitable for applications needing rapid data handling.
Architecture To understand more about deployment procedures, we need to look a little more at Neon architecture. Basically, you can view this as a PostgreSQL instance but without a storage layer Storage Broker Storage Broker is a coordination component between WAL Service and Pageserver. 50051 2.
Log monitoring, log analysis, and log analytics are more important than ever as organizations adopt more cloud-native technologies, containers, and microservices-based architectures. A log is a detailed, timestamped record of an event generated by an operating system, computing environment, application, server, or network device.
With Dynatrace, there is no need to think about schema and indexes, re-hydration, or hot/cold storage concepts. This architecture also means you’re not required to determine your log data use cases beforehand or while analyzing logs within the new Logs app.
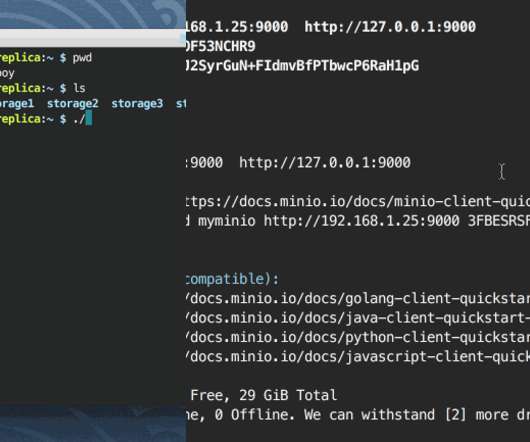
So I was researching object storage and I came across the open source distributed object storage software, Minio. After all they are both object storage solutions. Being that Minio was written with Golang, it is cross platform for different computing architectures, ARM included.
Infrastructure monitoring Infrastructure monitoring reviews servers, storage, network connections, virtual machines, and other data center elements that support applications. Because every DevOps environment is unique, exactly how organizations implement these monitoring types will differ depending on architecture and tools.
Key Takeaways Redis offers complex data structures and additional features for versatile data handling, while Memcached excels in simplicity with a fast, multi-threaded architecture for basic caching needs. Introduction Caching serves a dual purpose in web development – speeding up client requests and reducing server load.
Behind the scenes, Amazon DynamoDB automatically spreads the data and traffic for a table over a sufficient number of servers to meet the request capacity specified by the customer. These architectural discussions culminated in Amazon DynamoDB, a new NoSQL service that we are excited to release today. The growth of Amazonâ??s
While this abundance of dashboards and information is by no means unique to Netflix, it certainly holds true within our microservices architecture. A span: Represents a unit of work, such as a network call from one service to another (a client/server relationship) or a purely internal action (e.g., starting and finishing a method).
In this article, we will explore what RabbitMQ is, its mechanisms to facilitate message queueing, its role within software architectures, and the tangible benefits it delivers in real-world scenarios. It plays a critical role by assigning tasks, which trims down the delivery times for web application servers and enhances overall productivity.
Previously I’ve talked about why logging is required and the architecture and circular nature of the log, so now it’s time to look at the real heart of the logging system—the log records themselves. There are between 70 and 100 log record types, depending on the version of SQL Server (there’s no documented list). What Are Log Records?
The resource loading waterfall is a cascade of files downloaded from the network server to the client to load your website from start to finish. Client Side Rendering, Server Side Rendering And Jamstack. To run it, you have to make another API call to the server and retrieve any data you want to load. Jump to online workshops ?.
This article delivers a practical roadmap for using backups and binary logs to achieve accurate MySQL recovery, detailed steps for setting up your server, and tips for managing recovery and backups effectively without overwhelming you with complexity. Insert the ‘log-bin’ directive into your server’s configuration file (my.cnf or my.ini).
Load balancing : Requests are evenly distributed across multiple database servers, ensuring the system remains operational even if one server fails. Automated failover : To keep the database operational and minimize downtime, it automatically switches to a backup server if the primary server fails.
Shazam needed to handle an enormous increase in traffic for the duration of the Super Bowl and used DynamoDB as part of their architecture. This rapid adoption has allowed us to benefit from the scale economies inherent in our architecture. Indexed Storage costs : We are lowering the price of indexed storage by 75%.
You can choose to save them locally on the same server, stream them to different servers, or store them in object storage. STDOUT Datasink This diagram displays the process of streaming a backup to object storage utilizing the current STDOUT datasink: XtraBackup spawns multiple copy threads.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content