This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The Evolution of Back-End Complexity Until recently, back-end architectures were relatively straightforward: monolithic applications ruled the landscape, with everything neatly contained within a single codebase. Developers could understand and manage the entire systems intricacies.
In the landscape of computer architecture, two prominent paradigms shape the realm of parallel processing: SIMD (Single Instruction, Multiple Data) and MIMD (Multiple Instruction, Multiple Data) architectures.
Multimodal data processing is the evolving need of the latest data platforms powering applications like recommendation systems, autonomous vehicles, and medical diagnostics. Handling multimodal data spanning text, images, videos, and sensor inputs requires resilient architecture to manage the diversity of formats and scale.
When running a process in Salesforce, the first question you should ask is whether to execute it synchronously or asynchronously. If the task can be delayed and doesn't require an immediate result, it's always beneficial to leverage Salesforce's asynchronous processes, as they offer significant advantages to your technical architecture.
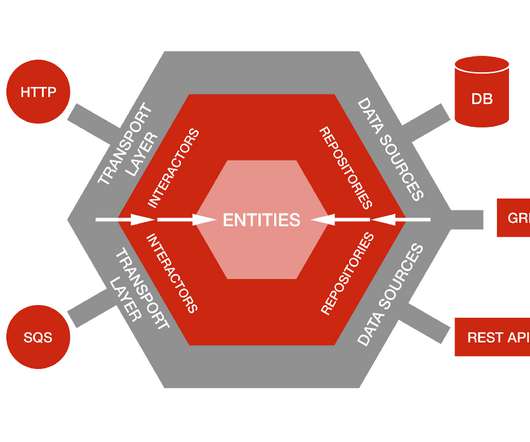
by Damir Svrtan and Sergii Makagon As the production of Netflix Originals grows each year, so does our need to build apps that enable efficiency throughout the entire creative process. We decided to build our app based on principles behind Hexagonal Architecture and Uncle Bob’s Clean Architecture.
In today's data-driven world, organizations need efficient and scalable data pipelines to process and analyze large volumes of data. Medallion Architecture provides a framework for organizing data processing workflows into different zones, enabling optimized batch and stream processing.
Logs can also be transformed appropriately for presentation, for example, or further pipeline processing. We can then parse structured log data to be formatted for our customized analysis needs.
The decision between batch and real-time processing is a critical one, shaping the design, architecture, and success of our data pipelines. Understanding the key distinctions between these two processing paradigms is crucial for organizations to make informed decisions and harness the full potential of their data.
It’s an underlying web application architecture that makes this process possible. In this blog, you’ll discover what a web app architecture is, how a web application architecture diagram looks, and how you can design the right architecture for web apps.
My experiences include tackling challenges like handling service failures in distributed architectures and mitigating the cascading effects of outages in high-demand systems. The Evolution of API Architecture Over the years, API architecture has evolved to address the gaps in its previous designs and keep up with the ever-pressing demands.
Mainframe architecture refers to the design and structure of a mainframe computer system, which is a powerful and reliable computing platform used for large-scale data processing, transaction processing, and enterprise applications.
Over the last few years, microservice architecture emerged to be on top of conventional SOA (Service Oriented Architecture). This much more precise and smaller architecture brought in many benefits. have backed their performance based on this architecture. have backed their performance based on this architecture.
In the realm of modern software architecture, middleware plays a pivotal role in connecting various components of distributed systems. This is crucial because middleware often serves as the bridge between client applications and backend databases, handling a high volume of requests and data processing tasks.
For this, the only solution is to build a multi-tenant architecture SaaS application. If this is you, you might have assumed they have a repeatable process to run thousands of apps across all their customers. The real solution is a multi-tenant architecture on AWS for a SaaS application.
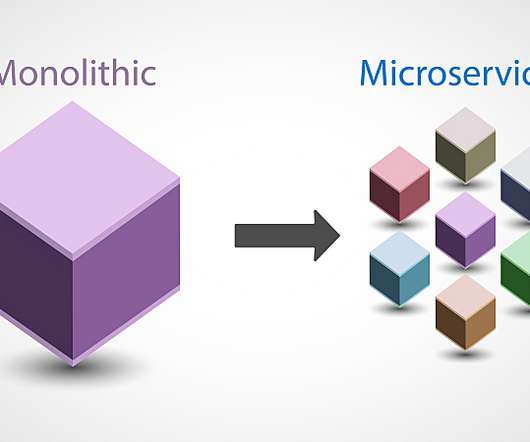
As a result, organizations are weighing microservices vs. monolithic architecture to improve software delivery speed and quality. Traditional monolithic architectures are built around the concept of large applications that are self-contained, independent, and incorporate myriad capabilities. What is monolithic architecture?
Many organizations are taking a microservices approach to IT architecture. However, in some cases, an organization may be better suited to another architecture approach. Therefore, it’s critical to weigh the advantages of microservices against its potential issues, other architecture approaches, and your unique business needs.
Without observability, the benefits of ARM are lost Over the last decade and a half, a new wave of computer architecture has overtaken the world. ARM architecture, based on a processor type optimized for cloud and hyperscale computing, has become the most prevalent on the planet, with billions of ARM devices currently in use.
Protect data in multi-tenant architectures To bring you the most value by unifying observability and security in one analytics and automation platform powered by AI, Dynatrace SaaS leverages a multitenancy architecture, enabling efficient and scalable data ingestion, querying, and processing on shared infrastructure.
This integration simplifies the process of embedding Dynatrace full-stack observability directly into custom Amazon Machine Images (AMIs). VMware migration support for seamless transitions For enterprises transitioning VMware-based workloads to the cloud, the process can be complex and resource-intensive.
Our company uses artificial intelligence (AI) and machine learning to streamline the comparison and purchasing process for car insurance and car loans. We innovatively use its snapshot feature to implement a primary-replica architecture for ClickHouse. As our data grew, we had problems with AWS Redshift which was slow and expensive.
This article is intended for data scientists, AI researchers, machine learning engineers, and advanced practitioners in the field of artificial intelligence who have a solid grounding in machine learning concepts, natural language processing , and deep learning architectures.
Early this year, the book Software Architecture Metrics: Case Studies to Improve the Quality of Your Architecture was published. He wrote a chapter that is particularly useful in contexts where the architecture and environment still have many opportunities for improvement. Intro and Problem Statement.
Future blogs will provide deeper dives into each service, sharing insights and lessons learned from this process. The Netflix video processing pipeline went live with the launch of our streaming service in 2007. The Netflix video processing pipeline went live with the launch of our streaming service in 2007.
A Data Movement and Processing Platform @ Netflix By Bo Lei , Guilherme Pires , James Shao , Kasturi Chatterjee , Sujay Jain , Vlad Sydorenko Background Realtime processing technologies (A.K.A stream processing) is one of the key factors that enable Netflix to maintain its leading position in the competition of entertaining our users.
One of those beautiful complications was the introduction of Agile methodologies, which have become a standard in software development by shifting how we develop software into a more responsive and collaborative process. Fortunately, the concept of Architectural Observability steps in to help.
With the evolution of modern applications serving increasing needs for real-time data processing and retrieval, scalability does, too. However, the process for effectively scaling Elasticsearch can be nuanced, since one needs a proper understanding of the architecture behind it and of performance tradeoffs.
As every developer knows, logs are crucial for uncovering insights and detecting fundamental flaws, such as process crashes or exceptions. Additionally, Dynatrace integrates relevant trace data, providing full visibility into complex, microservices-based architectures.
Key takeaways from this article on modern observability for serverless architecture: As digital transformation accelerates, organizations need to innovate faster and continually deliver value to customers. Companies often turn to serverless architecture to accelerate modernization efforts while simplifying IT management.
In the labyrinth of data-driven architectures, the challenge of data integration—fusing data from disparate sources into a coherent, usable form — stands as one of the cornerstones. However, it would be a mistake to dismiss batch processing as an antiquated approach. Systems were not equipped to handle multiple tasks simultaneously.
RabbitMQ is designed for flexible routing and message reliability, while Kafka handles high-throughput event streaming and real-time data processing. This article outlines the key differences in architecture, performance, and use cases to help determine the best fit for your workload. What is RabbitMQ? What is Apache Kafka?
It requires a state-of-the-art system that can track and process these impressions while maintaining a detailed history of each profiles exposure. In this multi-part blog series, we take you behind the scenes of our system that processes billions of impressions daily.
Part 3: System Strategies and Architecture By: VarunKhaitan With special thanks to my stunning colleagues: Mallika Rao , Esmir Mesic , HugoMarques This blog post is a continuation of Part 2 , where we cleared the ambiguity around title launch observability at Netflix. The request schema for the observability endpoint.
It uses Python as its programming language and offers a flexible architecture suited for both small-scale and large-scale data processing. One of the key features of Apache Airflow is its ability to schedule and trigger batch jobs, making it a popular choice for processing large volumes of data.
by Jun He , Yingyi Zhang , and Pawan Dixit Incremental processing is an approach to process new or changed data in workflows. The key advantage is that it only incrementally processes data that are newly added or updated to a dataset, instead of re-processing the complete dataset.
This blog post dissects the vulnerability, explains how Struts processes file uploads, details the exploit mechanics, and outlines mitigation strategies. Introduction Apache Struts 2 is a widely used Java framework for web applications, valued for its flexibility and Model-View-Controller (MVC) architecture.
Greenplum Database is a massively parallel processing (MPP) SQL database that is built and based on PostgreSQL. In this blog post, we explain what Greenplum is, and break down the Greenplum architecture, advantages, major use cases, and how to get started. The Greenplum Architecture. The Greenplum Architecture.
The Texas Risk and Authorization Management Program (TX-RAMP) provides a standardized approach for security assessment, certification, and continuous monitoring of cloud computing services that process the data of Texas state agencies. Complex IT environments that house these services are often built on hybrid and multicloud architectures.
This decoupling is crucial in modern architectures where scalability and fault tolerance are paramount. The architecture of RabbitMQ is meticulously designed for complex message routing, enabling dynamic and flexible interactions between producers and consumers. Erlang is the backbone of RabbitMQ clustering.
The amount of data we capture in any field is increasing exponentially, which requires a technology that can process large amounts of data in a short duration. One such technology would be Apache Spark.
To get a better understanding of AWS serverless, we’ll first explore the basics of serverless architectures, review AWS serverless offerings, and explore common use cases. Serverless architecture: A primer. Serverless architecture shifts application hosting functions away from local servers onto those managed by providers.
By efficiently capturing, processing, and transmitting logs, metrics, and traces, observability agents provide a comprehensive view of system health and behavior. This data is then sent to centralized observability platforms where it can be analyzed to gain valuable insights into system performance, identify issues, and optimize operations.
To fully leverage its capabilities and improve efficient data processing, it's crucial to optimize query performance. Understanding Snowflake Architecture Let’s briefly cover Snowflake architecture before we deal with data modeling and optimization techniques. Snowflake’s architecture consists of three main layers:
In today's fast-paced software development landscape, microservices have emerged as a popular architectural pattern. This architectural style enables teams to develop and deploy services independently, offering flexibility and scalability to the software development process. But what exactly are microservices?
Motivation With the rapid growth in Netflix member base and the increasing complexity of our systems, our architecture has evolved into an asynchronous one that enables both online and offline computation. To avoid processing old events, a staleness filter is applied as a gating check.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content