This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
With the evolution of modern applications serving increasing needs for real-time data processing and retrieval, scalability does, too. One such open-source, distributed search and analytics engine is Elasticsearch, which is very efficient at handling data in large sets and high-velocity queries.
It’s a nice building with good architecture! However, a more scalable approach would be to begin with a new foundation and begin a new building. However, a more scalable approach would be to begin with a new foundation and begin a new building. The facilities are modern, spacious and scalable. What is SVT-AV1?
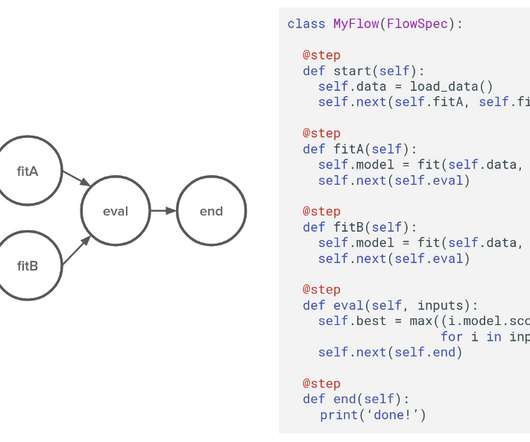
by David Berg , Ravi Kiran Chirravuri , Romain Cledat , Savin Goyal , Ferras Hamad , Ville Tuulos tl;dr Metaflow is now open-source! The infrastructure should allow them to exercise their freedom as data scientists but it should provide enough guardrails and scaffolding, so they don’t have to worry about software architecture too much.
2020 cemented the reality that modern software development practices require rapid, scalable delivery in response to unpredictable conditions. This method of structuring, developing, and operating complex, multi-function software as a collection of smaller independent services is known as microservice architecture. Dynatrace news.
2020 cemented the reality that modern software development practices require rapid, scalable delivery in response to unpredictable conditions. This method of structuring, developing, and operating complex, multi-function software as a collection of smaller independent services is known as microservice architecture. Dynatrace news.
In this blog post, we explain what Greenplum is, and break down the Greenplum architecture, advantages, major use cases, and how to get started. Greenplum Database is an open-source , hardware-agnostic MPP database for analytics, based on PostgreSQL and developed by Pivotal who was later acquired by VMware. Greenplum Advantages.
This article outlines the key differences in architecture, performance, and use cases to help determine the best fit for your workload. RabbitMQ follows a message broker model with advanced routing, while Kafkas event streaming architecture uses partitioned logs for distributed processing. What is RabbitMQ? What is Apache Kafka?
Many organizations are taking a microservices approach to IT architecture. However, in some cases, an organization may be better suited to another architecture approach. Therefore, it’s critical to weigh the advantages of microservices against its potential issues, other architecture approaches, and your unique business needs.
SVT-AV1: open-source AV1 encoder and decoder by Andrey Norkin , Joel Sole , Mariana Afonso , Kyle Swanson, Agata Opalach , Anush Moorthy , Anne Aaron SVT-AV1 is an open-source AV1 codec implementation hosted on GitHub [link] under a BSD + patent license. We welcome more contributors to the project.
Part 3: System Strategies and Architecture By: VarunKhaitan With special thanks to my stunning colleagues: Mallika Rao , Esmir Mesic , HugoMarques This blog post is a continuation of Part 2 , where we cleared the ambiguity around title launch observability at Netflix. The response schema for the observability endpoint.
As dynamic systems architectures increase in complexity and scale, IT teams face mounting pressure to track and respond to conditions and issues across their multi-cloud environments. Organizations usually implement observability using a combination of instrumentation methods including open-source instrumentation tools, such as OpenTelemetry.
The use of opensource databases has increased steadily in recent years. Past trepidation — about perceived vulnerabilities and performance issues — has faded as decision makers realize what an “opensource database” really is and what it offers. What is an opensource database?
by David Berg , Ravi Kiran Chirravuri , Romain Cledat , Savin Goyal , Ferras Hamad , Ville Tuulos tl;dr Metaflow is now open-source! The infrastructure should allow them to exercise their freedom as data scientists but it should provide enough guardrails and scaffolding, so they don’t have to worry about software architecture too much.
Open-source software drives a vibrant Kubernetes ecosystem. Through effortless provisioning, a larger number of small hosts provide a cost-effective and scalable platform. Opensource software drives a vibrant Kubernetes ecosystem. Dynatrace’s investment in opensource technologies keeps growing.
Then, we will discuss the system's architecture, the problems it solves, and the model employed to manage containerized deployments and scaling. Kubernetes (sometimes called K8s) is an open-source container-orchestration system that simplifies the deployment, scaling, and management of containerized applications.
Martin Sústrik : Philosophers, by and large, tend to be architecture astronauts. Programmers' insight is that architecture astronauts fail. And the sense that you have to be here or you can’t play is going to start diminishing. There more.
Transforming an application from monolith to microservices-based architecture can be daunting, and knowing where to start can be difficult. Unsurprisingly, organizations are breaking away from monolithic architectures and moving toward event-driven microservices. Migration is time-consuming and involved. create a microservice; 2.
Today’s digital businesses run on heterogeneous and highly dynamic architectures with interconnected applications and microservices deployed via Kubernetes and other cloud-native platforms. Common questions include: Where do bottlenecks occur in our architecture? How can we optimize for performance and scalability?
… The post OpenSourcing Peloton, Uber’s Unified Resource Scheduler appeared first on Uber Engineering Blog. First introduced by Uber in November 2018, Peloton , a unified resource scheduler, manages resources across distinct workloads, combining separate compute clusters.
As cloud-native, distributed architectures proliferate, the need for DevOps technologies and DevOps platform engineers has increased as well. They are similar to site reliability engineers (SREs) who focus on creating scalable, highly reliable software systems. Opensource automated browser and testing tool. Kubernetes.
As part of our robust and scalable metrics infrastructure, we built … The post M3: Uber’s OpenSource, Large-scale Metrics Platform for Prometheus appeared first on Uber Engineering Blog.
Their “ State of OpenSource Security Report, 2020 ” found that the most common vulnerabilities are cross-site scripting vulnerabilities (18%), followed by malicious packages (13%). Snyk also reports that open-source software is a common entry point for vulnerabilities. Whether the process is exposed to the Internet.
Dynatrace introduced the Dynatrace Operator, built on the opensource project Operator Framework, in late 2018. Scalability and cloud-native support: Dynatrace is designed to scale effortlessly in dynamic Kubernetes environments.
For software engineering teams, this demand means not only delivering new features faster but ensuring quality, performance, and scalability too. This involves new software delivery models, adapting to complex software architectures, and embracing automation for analysis and testing. Performance-as-a-self-service .
Opensource has also become a fundamental building block of the entire cloud-native stack. While leveraging cloud-native platforms, open-source and third-party libraries accelerate time to value significantly, it also creates new challenges for application security.
Keptn is the opensource control plane for continuous deployment and automated operations for cloud native applications on Kubernetes. The opensource community and the team at Dynatrace that drives this project is already working on support for OpenShift and other Kubernetes services such as AKS, PKS & EKS.
Today’s cloud-native applications are predominately built from open-source components, or packages, strung together with a small amount of custom code. Gartner cites research that indicates more than 70% of applications contain flaws resulting from embedded open-source software.
To do so we have successfully established AI-based White box load and resiliency testing with JMeter and Dynatrace, helping identify and resolve major performance and scalability problems in recent projects before deploying to production. Our customers usually involve us 2-4 weeks before the production release. a Jenkinsfile.
Grail architectural basics. The aforementioned principles have, of course, a major impact on the overall architecture. A data lakehouse addresses these limitations and introduces an entirely new architectural design. From the beginning, Grail was built to be fast and scalable to manage massive volumes of data.
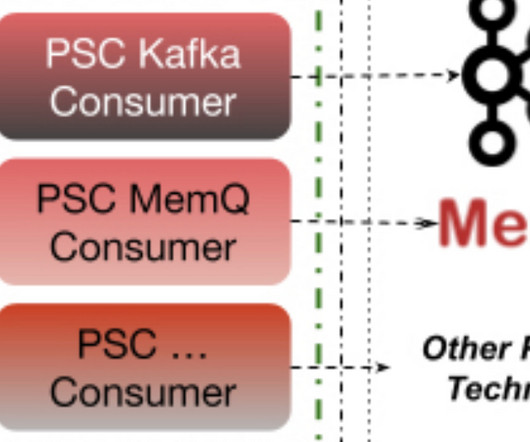
Pinterest open-sourced its generic PubSub client library, PSC, which has been heavily used in production for a year and a half. The library helped the engineering teams by increasing developer velocity, and the scalability and stability of services using it. By Rafal Gancarz
In December Dynatrace announced Keptn , an open-source pluggable control plane enabling autonomous software delivery and operations for cloud-native applications. But – what if the new version has performance, scalability or architectural flaws and therefore should never reach production?
Opensource code, for example, has generated new threat vectors for attackers to exploit. A case in point is Log4Shell, which emerged in late 2021 and exposed opensource libraries to exploitation. Dynatrace introduces automatic vulnerability management for PHP opensource scripting language – blog.
Opensource databases provide great foundations for high availability — without the pitfalls of vendor lock-in that can come with proprietary software. However, opensource software doesn’t typically include built-in HA solutions. They’re proven and ready-to-go.
Automatically collect and evaluate business, service, and architectural indicator metrics to promote or roll back deployments. Providing standardized self-service pipeline templates, best practices, and scalable automation for monitoring, testing, and SLO validation. SLO validation – ?Automatically Topics in this blog series.
This is not to say, however, that any mid-level developer will have much difficulty finding and handling one of many available open-source servers. You may also like: Application Scalability — How To Do Efficient Scaling.
Option 1: Build a custom solution using several (opensource) frameworks Do-it-yourself (DIY) was the only option before composable enterprise software platforms became popular. Faced with these requirements, Omnilogy carefully evaluated the following two options for implementing a solution to the pipeline observability challenge.
While engaging the automatic instrumentation of the Dynatrace OneAgent makes log ingestion automatic and scalable , our customers have set up multiple other log ingestion methods. But there are cases where you might be limited in setting up a dedicated syslog server with OneAgent because of environment architecture or resources.
Challenges & Opportunities in the Infra Data Space Security Events Platform for Anomaly Detection How can we develop a complex event processing system to ingest semi-structured data predicated on schema contracts from hundreds of sources and transform it into event streams of structured data for downstream analysis?
Identify data use cases and develop a scalable delivery model with documentation. This opensource framework stores and processes large sets of structured and unstructured data. Organizations use this opensource, distributed analytics engine for big data workloads. Automate analytics tools and processes.
Our Journey so Far Over the past year, we’ve implemented the core infrastructure pieces necessary for a federated GraphQL architecture as described in our previous post: Studio Edge Architecture The first Domain Graph Service (DGS) on the platform was the former GraphQL monolith that we discussed in our first post (Studio API).
Apache Cassandra is an open-source, distributed, NoSQL database. Because of its scalability and distributed architecture, thousands of companies trust it to run their cloud and hybrid-based workloads at high availability without compromising performance.
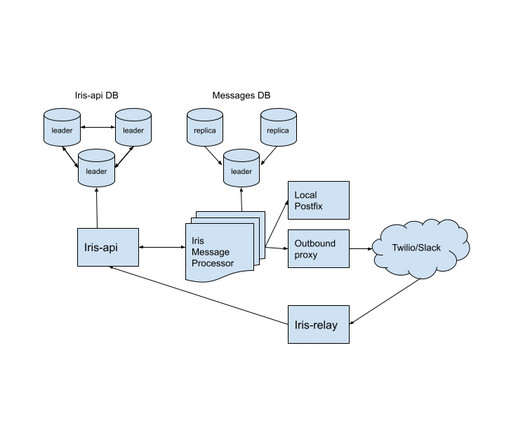
LinkedIn developed a new open-source service called "iris-message-processor" to enhance the performance and reliability of its existing Iris escalation management system. iris-message-processor" significantly improves processing speeds, being ~4.6x faster under average loads and ~86.6x faster under high loads than its predecessor.
Security analytics must also contend with the multicomponent architecture of modern IT infrastructure. This includes everything from multicloud deployments to microservices to Kubernetes instances and the use of opensource software. How do companies reliably find, review, and analyze this data?
Stream processing One approach to such a challenging scenario is stream processing, a computing paradigm and software architectural style for data-intensive software systems that emerged to cope with requirements for near real-time processing of massive amounts of data. We designed experimental scenarios inspired by chaos engineering.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











































Let's personalize your content