This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
As an executive, I am always seeking simplicity and efficiency to make sure the architecture of the business is as streamlined as possible. Worsened by separate tools to track metrics, logs, traces, and user behaviorcrucial, interconnected details are separated into different storage.
DevOps and security teams managing today’s multicloud architectures and cloud-native applications are facing an avalanche of data. On average, organizations use 10 different tools to monitor applications, infrastructure, and user experiences across these environments.
As dynamic systems architectures increase in complexity and scale, IT teams face mounting pressure to track and respond to conditions and issues across their multi-cloud environments. What is the difference between monitoring and observability? Is observability really monitoring by another name? Dynatrace news. In short, no.
In this short video, Rudy de Busscher shows how to connect MicroProfile Metrics with Prometheus and Grafana to produce useful graphics and to help investigate your microservice architecture. The goal of MicroProfile Metrics is to expose monitoring data from the implementation in a unified way.
Organizations are depending more and more on distributed architectures to provide application services. This trend is prompting advances in both observability and monitoring. But exactly what are the differences between observability vs. monitoring? Monitoring and observability provide a two-pronged approach.
Without observability, the benefits of ARM are lost Over the last decade and a half, a new wave of computer architecture has overtaken the world. ARM architecture, based on a processor type optimized for cloud and hyperscale computing, has become the most prevalent on the planet, with billions of ARM devices currently in use.
Many organizations are taking a microservices approach to IT architecture. However, in some cases, an organization may be better suited to another architecture approach. Therefore, it’s critical to weigh the advantages of microservices against its potential issues, other architecture approaches, and your unique business needs.
In fact, according to a Dynatrace global survey of 1,300 CIOs , 99% of enterprises utilize a multicloud environment and seven cloud monitoring solutions on average. What is cloud monitoring? Cloud monitoring is a set of solutions and practices used to observe, measure, analyze, and manage the health of cloud-based IT infrastructure.
Cloud-native technologies are driving the need for organizations to adopt a more sophisticated IT monitoring approach to satisfy the competitive demands of modern business. Often, these metrics are unable to even identify trends from past to present, never mind helping teams to predict future trends.
I realized that our platforms unique ability to contextualize security events, metrics, logs, traces, and user behavior could revolutionize the security domain by converging observability and security. Collect observability and security data user behavior, metrics, events, logs, traces (UMELT) once, store it together and analyze in context.
Observability is the new standard of visibility and monitoring for cloud-native architectures. It’s powered by vast amounts of collected telemetry data such as metrics, logs, events, and distributed traces to measure the health of application performance and behavior. Observability brings multicloud environments to heel.
Infrastructure monitoring is the process of collecting critical data about your IT environment, including information about availability, performance and resource efficiency. Many organizations respond by adding a proliferation of infrastructure monitoring tools, which in many cases, just adds to the noise. Dynatrace news.
Log monitoring, log analysis, and log analytics are more important than ever as organizations adopt more cloud-native technologies, containers, and microservices-based architectures. What is log monitoring? Log monitoring vs log analytics. Dynatrace news. billion in 2020 to $4.1 What are logs?
This is why we’re proud to announce fully automated and AI-powered full-stack monitoring for OpenShift 4.0 Traditional monitoring systems cannot keep up with the speed of change in those highly dynamic large-scale container environments. Automated distributed tracing, deep monitoring and AI-powered answers for OpenShift 4.0
This method of structuring, developing, and operating complex, multi-function software as a collection of smaller independent services is known as microservice architecture. ” it helps to understand the monolithic architectures that preceded them. Understanding monolithic architectures. Microservices benefits.
This method of structuring, developing, and operating complex, multi-function software as a collection of smaller independent services is known as microservice architecture. ” it helps to understand the monolithic architectures that preceded them. Understanding monolithic architectures. Microservices benefits.
Dynatrace has recently enhanced its Metrics APIs, allowing everyone to send any type of metric with any set of data dimension to Davis, Dynatrace’s AI engine. In our conversation, I mentioned the new Dynatrace Metrics ingestion and off we went. ?? There are many use cases for using this API.
This article outlines the key differences in architecture, performance, and use cases to help determine the best fit for your workload. RabbitMQ follows a message broker model with advanced routing, while Kafkas event streaming architecture uses partitioned logs for distributed processing. What is RabbitMQ? What is Apache Kafka?
As more organizations transition to distributed services, IT teams are experiencing the limitations of traditional monitoring tools, which were designed for yesterday’s monolithic architectures. Where traditional monitoring falls flat. The architects and developers who create the software must design it to be observed.
This has led to the recent release of our new Lambda monitoring extension supporting Node.js, Java, and Python. This extension was built from scratch to take into account all we’ve learned and the special requirements for monitoring ephemeral, auto-scaling, micro VMs like AWS Lambda. A look under the hood of AWS Lambda.
Wouldn’t it be great if I had an industry-leading software intelligence platform to monitor these apps, pinpoint root causes of slow performance or errors, and gain insights about my users’ experience? At Dynatrace we live and breathe the concept of “Drink Your Own Champagne” (DYOC), so of course, I want to use Dynatrace to monitor my apps.
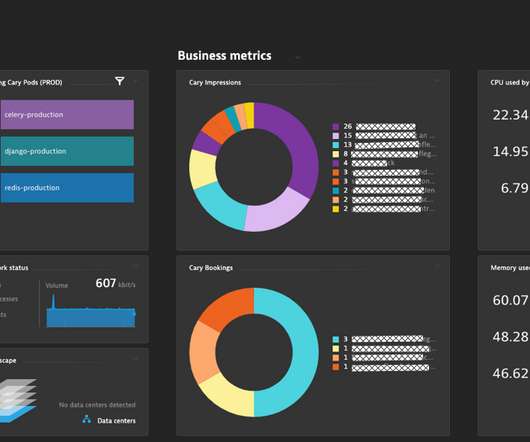
Monitoring and observability are important topics for any developer, architect, or Site Reliability Engineer (SRE), and this holds true independent of the language or runtime of choice. Relevant infrastructure, operations and business metrics on a single Dynatrace dashboard for CARY. Dynatrace news. Guidance for Django.
Loosely defined, observability is the ability to understand what’s happening inside a system from the knowledge of the external data it produces, which are usually logs, metrics, and traces. OpenTelemetry reference architecture. Monitoring begins here. Logs, metrics, and traces make up the bulk of all telemetry data.
With the world’s increased reliance on digital services and the organizational pressure on IT teams to innovate faster, the need for DevOps monitoring tools has grown exponentially. But when and how does DevOps monitoring fit into the process? And how do DevOps monitoring tools help teams achieve DevOps efficiency?
A metric crossed a threshold. Over the years we’ve learned from on-call engineers about the pain points of application monitoring: too many alerts, too many dashboards to scroll through, and too much configuration and maintenance. Metrics are a key part of understanding application health. Client metrics and QoE changes.
Optimizing RabbitMQ performance through strategies such as keeping queues short, enabling lazy queues, and monitoring health checks is essential for maintaining system efficiency and effectively managing high traffic loads. This decoupling is crucial in modern architectures where scalability and fault tolerance are paramount.
As companies strive to innovate and deliver faster, modern software architecture is evolving at near the speed of light. It allows for the breaking up of heavy monolithic architectures into multiple serverless “functions.” Understand and optimize your architecture. Monitor your serverless applications with just two clicks.
Detailed performance analysis for better software architecture and resource allocation. All metrics, traces, and real user data are also surfaced in the context of specific events. With Dynatrace, you can create custom metrics based on user-defined log events. So, let’s compare the two approaches for ingesting logs.
We’re proud to introduce a significant improvement to Dynatrace Log Monitoring that will empower all your teams. With Dynatrace Log monitoring, you’re only one click away from investigating the log events that were captured during the problem time frame and beginning any required remediation efforts. Dynatrace news.
As Dynatrace is a leader in Cloud monitoring, we have architected our Software Intelligence Platform specifically to complement Kubernetes by providing extensive functionality to tame the complexities and prevent performance issues that can occur across the development and deployment cycles. Don’t underestimate complexity. Datacenters.
As one of the most popular open-source Kubernetes monitoring solutions, Prometheus leverages a multidimensional data model of time-stamped metric data and labels. The platform uses a pull-based architecture to collect metrics from various targets.
When organizations move toward the cloud, their systems also lean toward distributed architectures. You need to find the right tools to monitor, track and trace these systems by analyzing outputs through metrics, logs, and traces. One of the most common examples is the adoption of microservices.
This shift requires infrastructure monitoring to ensure all your components work together across applications, operating systems, storage, servers, virtualization, and more. What is infrastructure monitoring? . What to look for when selecting an infrastructure monitoring solution? It’s not hype, it’s the way forward.
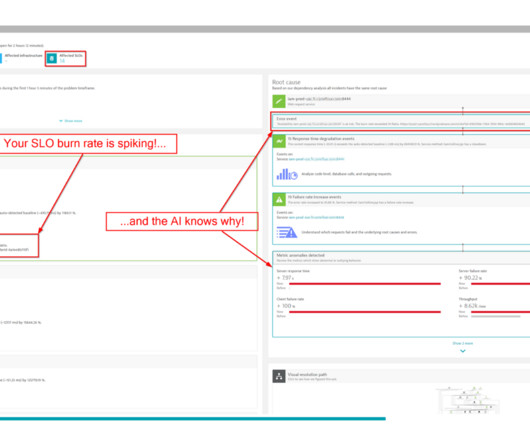
SLO monitoring and alerting on SLOs using error-budget burn rates are critical capabilities that can help organizations achieve that goal. SLOs are specifically processed metrics that help businesses balance breakthroughs with reliability. What is SLO monitoring? And what is an error budget burn rate?
Title Health encompasses various metrics and indicators that reflect how well a title is performing, in terms of discoverability and member engagement. Defining Title Health provided a framework to monitor and optimize each titles lifecycle. What is the architecture of the systems involved? How do we ensure standardization?
As companies strive to innovate and deliver faster, modern software architecture is evolving at near the speed of light. It allows for the breaking up of heavy monolithic architectures into multiple serverless “functions.” Understand and optimize your architecture. Monitor your serverless applications with just two clicks.
Highlighting NewReleases For new content, impression history helps us monitor initial user interactions and adjust our merchandising efforts accordingly. Architecture Overview The first pivotal step in managing impressions begins with the creation of a Source-of-Truth (SOT) dataset.
We’re delighted to share that IBM and Dynatrace have joined forces to bring the Dynatrace Operator, along with the comprehensive capabilities of the Dynatrace platform, to Red Hat OpenShift on the IBM Power architecture (ppc64le). Captures metrics, traces, logs, and other telemetry data in context.
As we did with IBM Power , we’re delighted to share that IBM and Dynatrace have joined forces to bring the Dynatrace Operator, along with the comprehensive capabilities of the Dynatrace platform, to Red Hat OpenShift on the IBM Z and LinuxONE architecture (s390x). This is significant when coupled with the OpenShift platform.
A few years ago, we were paged by our SRE team due to our Metrics Alerting System falling behind — critical application health alerts reached engineers 45 minutes late! Hence, we started down the path of alert evaluation via real-time streaming metrics. OK, Results?
Dynatrace is proud to provide deep monitoring support for Azure Linux as a container host operating system (OS) platform for Azure Kubernetes Services (AKS) to enable customers to operate efficiently and innovate faster. Why monitor Azure Linux container host for AKS? How Can Dynatrace Monitor Azure Linux container host for AKS?
Transforming an application from monolith to microservices-based architecture can be daunting, and knowing where to start can be difficult. Unsurprisingly, organizations are breaking away from monolithic architectures and moving toward event-driven microservices. Migration is time-consuming and involved. create a microservice; 2.
As legacy monolithic applications give way to more nimble and portable services, the tools once used to monitor their performance are unable to serve the complex cloud-native architectures that now host them. The goal of monitoring is to enable data-driven decision-making. Where traditional methods struggle.
Also, these modern, cloud-native architectures produce an immense volume, velocity, and variety of data. Every service and component exposes observability data (metrics, logs, and traces) that contains crucial information to drive digital businesses. They are required to understand the full story of what happened in a system.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content