This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This article outlines the key differences in architecture, performance, and use cases to help determine the best fit for your workload. RabbitMQ follows a message broker model with advanced routing, while Kafkas event streaming architecture uses partitioned logs for distributed processing. What is RabbitMQ? What is Apache Kafka?
This scenario underscored the need for a new recommender system architecture where member preference learning is centralized, enhancing accessibility and utility across different models. Yet, many are confined to a brief temporal window due to constraints in serving latency or training costs.
Architecture Overview The first pivotal step in managing impressions begins with the creation of a Source-of-Truth (SOT) dataset. Impression Source-of-Truth architecture Ensuring High Quality Impressions Maintaining the highest quality of impressions is a top priority.
By: Rajiv Shringi , Oleksii Tkachuk , Kartik Sathyanarayanan Introduction In our previous blog post, we introduced Netflix’s TimeSeries Abstraction , a distributed service designed to store and query large volumes of temporal event data with low millisecond latencies. Today, we’re excited to present the Distributed Counter Abstraction.
Migrating Critical Traffic At Scale with No Downtime — Part 1 Shyam Gala , Javier Fernandez-Ivern , Anup Rokkam Pratap , Devang Shah Hundreds of millions of customers tune into Netflix every day, expecting an uninterrupted and immersive streaming experience. Logging is selective to cases where the old and new responses do not match.
Stream processing One approach to such a challenging scenario is stream processing, a computing paradigm and software architectural style for data-intensive software systems that emerged to cope with requirements for near real-time processing of massive amounts of data. This significantly increases event latency.
Tuning thousands of parameters has become an impossible task to achieve via a manual and time-consuming approach. The following figure shows the high-level architecture where any load testing solution (e.g. SREcon21 – Automating Performance Tuning with Machine Learning. The Akamas approach. lower than 2%.).
These include challenges with tail latency and idempotency, managing “wide” partitions with many rows, handling single large “fat” columns, and slow response pagination. Data Model At its core, the KV abstraction is built around a two-level map architecture. Useful for keeping “n-newest” or prefix path deletion.
This decoupling is crucial in modern architectures where scalability and fault tolerance are paramount. The architecture of RabbitMQ is meticulously designed for complex message routing, enabling dynamic and flexible interactions between producers and consumers. Keeping queues short maintains a responsive and efficient RabbitMQ setup.
Compare Latency. lower latency compared to DigitalOcean for PostgreSQL. Now, let’s take a look at the throughput and latency performance of our comparison. Next, we are going to test and compare the latency performance between ScaleGrid and DigitalOcean for PostgreSQL. PostgreSQL DigitalOcean Latency Averages (ms).
Rajiv Shringi Vinay Chella Kaidan Fullerton Oleksii Tkachuk Joey Lynch Introduction As Netflix continues to expand and diversify into various sectors like Video on Demand and Gaming , the ability to ingest and store vast amounts of temporal data — often reaching petabytes — with millisecond access latency has become increasingly vital.
Reduced tail latencies In both our GRPC and DGS Framework services, GC pauses are a significant source of tail latencies. In fact, we’ve found for our services and architecture that there is no such trade off. No explicit tuning has been required to achieve these results. There is no best garbage collector.
Motivation With the rapid growth in Netflix member base and the increasing complexity of our systems, our architecture has evolved into an asynchronous one that enables both online and offline computation. Architecture As shown in the diagram above, the RENO service can be broken down into the following components.
Moving to a multithreaded architecture will require extensive rewrites. But that causes a problem with PostgreSQL’s architecture – forking a process becomes expensive when transactions are very short, as the common wisdom dictates they should be. The PostgreSQL Architecture | Source. The Connection Pool Architecture.
Within this paradigm, it is possible to run entire architectures without touching a traditional virtual server, either locally or in the cloud. In a serverless architecture, applications are distributed to meet demand and scale requirements efficiently. When an application is triggered, it can cause latency as the application starts.
Table 1: Movie and File Size Examples Initial Architecture A simplified view of our initial cloud video processing pipeline is illustrated in the following diagram. Figure 1: A Simplified Video Processing Pipeline With this architecture, chunk encoding is very efficient and processed in distributed cloud computing instances.
This architecture shift greatly reduced the processing latency and increased system resiliency. We expanded pipeline support to serve our studio/content-development use cases, which had different latency and resiliency requirements as compared to the traditional streaming use case. divide the input video into small chunks 2.
It supports both high throughput services that consume hundreds of thousands of CPUs at a time, and latency-sensitive workloads where humans are waiting for the results of a computation. The subsystems all communicate with each other asynchronously via Timestone, a high-scale, low-latency priority queuing system.
At Netflix, we also heavily embrace a microservice architecture that emphasizes separation of concerns. The data warehouse is not designed to serve point requests from microservices with low latency. Therefore, we must efficiently move data from the data warehouse to a global, low-latency and highly-reliable key-value store.
Allegro experimented with different performance optimization options to improve Apache Kafka producer tail latency and eventually switched all its clusters to the XFS filesystem. The company used Kafka protocol sniffing, JVM profiling, and eBPF, which proved instrumental in identifying and eliminating performance bottlenecks.
You can ask for the best configuration to reduce latency or improve the user experience.” And with automatic application tuning, teams spend less time on manually testing and reviewing configurations, resulting in up to five times the productivity of performance engineers, DevOps, and SREs when it comes to application optimization.
You’re half awake and wondering, “Is there really a problem or is this just an alert that needs tuning? Telltale learns what constitutes typical health for an application, no alert tuning required. For example, a latency increase is less critical than error rate increase and some error codes are less critical than others.
This is especially crucial in microservice architectures, where the number of components can be overwhelming. Stay tuned for more examples and easy-to-adopt automations provided in our public Github project. Furthermore, increasing the frequency of releases requires additional product lifecycle automation and setup.
High level playback architecture with priority throttling and chaos testing Building a request taxonomy We decided to focus on three dimensions in order to categorize request traffic: throughput, functionality, and criticality. Those two metrics are approximate indicators of failures and latency.
In this architecture, service to service communication no longer goes through the single point of failure of a load balancer. The above architecture has served us well over the last decade, though changing business needs and evolving industry standards have added more complexity to our IPC ecosystem in a number of ways.
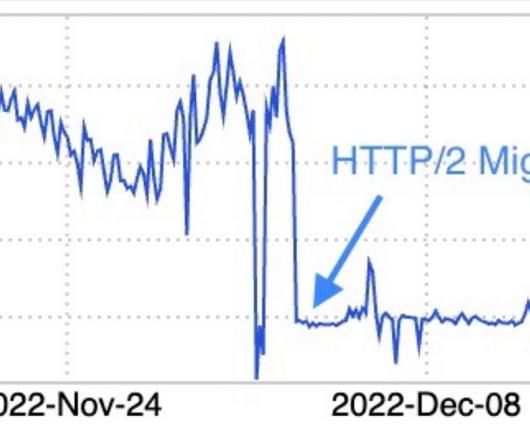
to HTTP2, resulting in a reduction in the number of connections, latency, and garbage collection times. LinkedIn was able to dramatically improve the scalability and performance of its Espresso database by migrating it from HTTP1.1 To achieve these gains, the team had to optimize the Netty’s default HTTP2 stack to make it fit their needs.
By collecting and analyzing key performance metrics of the service over time, we can assess the impact of the new changes and determine if they meet the availability, latency, and performance requirements. They enable us to further fine-tune and configure the system, ensuring the new changes are integrated smoothly and seamlessly.
As organizations adopt microservices-based architecture , service-level objectives (SLOs) have become a vital way for teams to set specific, measurable targets that ensure users are receiving agreed-upon service levels. You can set SLOs based on individual indicators, such as batch throughput, request latency, and failures-per-second.
Managing and operating asynchronous workflows can be difficult without the proper tools and architecture that puts observability, debugging, and tracing at the forefront. We are expected to process 1,000 watermarks for a single distribution in a minute, with non-linear latency growth as the number of watermarks increases.
This article will list some of the use cases of AutoOptimize, discuss the design principles that help enhance efficiency, and present the high-level architecture. These principles reduce resource usage by being more efficient and effective while lowering the end-to-end latency in data processing. More processing resources.
System Setup Architecture The following diagram summarizes the architecture description: Figure 1: Event-sourcing architecture of the Device Management Platform. By the following morning, alerts were received regarding high memory consumption and GC latencies, to the point where the service was unresponsive to HTTP requests.
The Reloaded system is a well-matured and scalable system, but its monolithic architecture can slow down rapid innovation. This enables us to use our scale to increase throughput and reduce latencies. Here, based on the video length, the throughput and latency requirements, available scale etc., via bug fixes).
Operational automation–including but not limited to, auto diagnosis, auto remediation, auto configuration, auto tuning, auto scaling, auto debugging, and auto testing–is key to the success of modern data platforms. We have also noted a great potential for further improvement by model tuning (see the section of Rollout in Production).
Netflix is known for its loosely coupled microservice architecture and with a global studio footprint, surfacing and connecting the data from microservices into a studio data catalog in real time has become more important than ever. Most of the business views created on top of the Iceberg tables can tolerate a few minutes of latency.
If we were to select the most important MySQL setting, if we were given a freshly installed MySQL or Percona Server for MySQL and could only tune a single MySQL variable, which one would it be? To be fair, that is also true with PostgreSQL; it hasn’t been tuned either, and it, too, can also perform much better.
In particular, we’ll define plans and offers, review the legacy architecture and some of its shortcomings, and dig into our new architecture and some of its advantages. Let’s take a deeper look at the architecture, protocols, and systems involved. A plan is essentially a set of features with a price.
Rather than listing the concepts, function calls, etc, available in Citus, which frankly is a bit boring, I’m going to explore scaling out a database system starting with a single host. And now, execute the benchmark: -- execute the following on the coordinator node pgbench -c 20 -j 3 -T 60 -P 3 pgbench The results are not pretty.
Here are the bombshell paragraphs: Our datacenter applications seek ever more CPU-efficient and lower-latency communication, which Pony Express delivers. Rather than reimplement TCP/IP or refactor an existing transport, we started Pony Express from scratch to innovate on more efficient interfaces, architecture, and protocol.
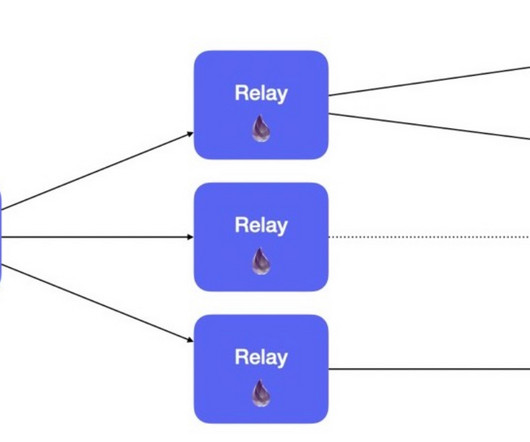
Wondering where RabbitMQ fits into your architecture? The software also extends capabilities allowing fine-tuning consumption parameters through QoS (Quality of Service) prefetch limits catered toward balancing load among numerous consumers, thus preventing overwhelming any single consumer entity.
As our business scales globally, the demand for data is growing and the needs for scalable low latency incremental processing begin to emerge. We are taking Big Data Orchestration to the next level and constantly solving new problems and challenges, please stay tuned. There are three common issues that the dataset owners usually face.
DBLog High Level Architecture. High Availability DBLog uses an active-passive architecture. Passive instances across regions are also possible, though it is recommended to operate in the same region as the database host in order to keep the change capture latencies low. Figure 3?—?DBLog Figure 4— Delta Connector.
DBLog High Level Architecture. High Availability DBLog uses active-passive architecture. Passive instances across regions are also possible, though it is recommended to operate in the same region as the database host in order to keep the change capture latencies low. Figure 3?—?DBLog Figure 4— Delta Connector.
The company evolved the guild component, which is responsible for fanning out billions of message notifications, in a series of performance and scalability improvements supported by system observability and performance tuning. By Rafal Gancarz
To understand what is happening here, we need to understand the way memory bandwidth interacts with memory latency and the concurrency (parallelism) of memory accesses. Stay tuned! I don’t expect all of that, but the core can clearly make use of more than 20 GB/s. Why is the single-core bandwidth increasing so slowly?
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content