This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In the realm of modern software architecture, middleware plays a pivotal role in connecting various components of distributed systems. Efficient database operations in middleware can dramatically improve overall system performance, reduce latency, and enhance user experience.
To this end, we developed a Rapid Event Notification System (RENO) to support use cases that require server initiated communication with devices in a scalable and extensible manner. In this blog post, we will give an overview of the Rapid Event Notification System at Netflix and share some of the learnings we gained along the way.
By: Rajiv Shringi , Oleksii Tkachuk , Kartik Sathyanarayanan Introduction In our previous blog post, we introduced Netflix’s TimeSeries Abstraction , a distributed service designed to store and query large volumes of temporal event data with low millisecond latencies. Today, we’re excited to present the Distributed Counter Abstraction.
This article outlines the key differences in architecture, performance, and use cases to help determine the best fit for your workload. RabbitMQ follows a message broker model with advanced routing, while Kafkas event streaming architecture uses partitioned logs for distributed processing.
Timestone: Netflix’s High-Throughput, Low-Latency Priority Queueing System with Built-in Support for Non-Parallelizable Workloads by Kostas Christidis Introduction Timestone is a high-throughput, low-latency priority queueing system we built in-house to support the needs of Cosmos , our media encoding platform.
Multimodal data processing is the evolving need of the latest data platforms powering applications like recommendation systems, autonomous vehicles, and medical diagnostics. Handling multimodal data spanning text, images, videos, and sensor inputs requires resilient architecture to manage the diversity of formats and scale.
Understanding sustained memory bandwidth in these systems starts with assuming 100% utilization and then reviewing the factors that get in the way (e.g., This requires a completely different approach to modeling the memory system — one based on Little’s Law from queueing theory.
It requires a state-of-the-art system that can track and process these impressions while maintaining a detailed history of each profiles exposure. In this multi-part blog series, we take you behind the scenes of our system that processes billions of impressions daily.
Scaling RabbitMQ ensures your system can handle growing traffic and maintain high performance. Key Takeaways RabbitMQ improves scalability and fault tolerance in distributed systems by decoupling applications, enabling reliable message exchanges.
Behind the scenes, a myriad of systems and services are involved in orchestrating the product experience. These backend systems are consistently being evolved and optimized to meet and exceed customer and product expectations. This blog series will examine the tools, techniques, and strategies we have utilized to achieve this goal.
These include challenges with tail latency and idempotency, managing “wide” partitions with many rows, handling single large “fat” columns, and slow response pagination. Data Model At its core, the KV abstraction is built around a two-level map architecture.
Every organization’s goal is to keep its systems available and resilient to support business demands. Lastly, error budgets, as the difference between a current state and the target, represent the maximum amount of time a system can fail per the contractual agreement without repercussions. Example 1: Architecture boundaries.
As the number of Titus users increased over the years, the load and pressure on the system increased substantially. The original assumptions and architectural choices were no longer viable. Overview The figure below depicts a simplified high-level architecture of a single Titus cluster (a.k.a
The following figure shows the high-level architecture where any load testing solution (e.g. The optimization goal was to improve the application efficiency, that is to improve the ratio between service throughput and cloud costs while not increasing the application latency (e.g. below 500ms) and error rates (e.g. lower than 2%.).
Stream processing One approach to such a challenging scenario is stream processing, a computing paradigm and software architectural style for data-intensive software systems that emerged to cope with requirements for near real-time processing of massive amounts of data. This significantly increases event latency.
As more organizations embrace microservices-based architecture to deliver goods and services digitally, maintaining customer satisfaction has become exponentially more challenging. Latency is the time that it takes a request to be served. Define SLOs for each service. Reliability. This is what Dynatrace captures as response time.
Table 1: Movie and File Size Examples Initial Architecture A simplified view of our initial cloud video processing pipeline is illustrated in the following diagram. Lastly, the packager kicks in, adding a system layer to the asset, making it ready to be consumed by the clients.
Site reliability engineering (SRE) is the practice of applying software engineering principles to operations and infrastructure processes to help organizations create highly reliable and scalable software systems. SRE applies DevOps principles to developing systems and software that help increase site reliability and performance.
As dynamic systemsarchitectures increase in complexity and scale, IT teams face mounting pressure to track and respond to conditions and issues across their multi-cloud environments. Dynatrace news. But what is observability? Why is it important, and what can it actually help organizations achieve? What is observability?
Cloud-based application architectures commonly leverage microservices. High latency or lack of responses. You receive an alert message from Dynatrace (your infrastructure observability hub) letting you know that the average response latency of all deployed APIs has tripled. Soaring number of active connections.
Traditional computing models rely on virtual or physical machines, where each instance includes a complete operating system, CPU cycles, and memory. Within this paradigm, it is possible to run entire architectures without touching a traditional virtual server, either locally or in the cloud. What is serverless computing?
It supports both high throughput services that consume hundreds of thousands of CPUs at a time, and latency-sensitive workloads where humans are waiting for the results of a computation. The first generation of this system went live with the streaming launch in 2007. Delivery?—?A
Trace your application Imagine a microservices architecture with hundreds of dependencies. Without distributed tracing, pinpointing the cause of increased latency could take hours or even days. Interact with data intuitively and easily and benefit from immediate, AI-supported insights.
This architecture shift greatly reduced the processing latency and increased system resiliency. By integrating with studio content systems, we enabled the pipeline to leverage rich metadata from the creative side and create more engaging member experiences like interactive storytelling.
Site reliability engineering (SRE) is the practice of applying software engineering principles to operations and infrastructure processes to help organizations create highly reliable and scalable software systems. SRE applies DevOps principles to developing systems and software that help increase site reliability and performance.
On modern Linux systems, the difference in overhead between forking a process and creating a thread is much lesser than it used to be. Moving to a multithreaded architecture will require extensive rewrites. The PostgreSQL Architecture | Source. The Connection Pool Architecture.
Rajiv Shringi Vinay Chella Kaidan Fullerton Oleksii Tkachuk Joey Lynch Introduction As Netflix continues to expand and diversify into various sectors like Video on Demand and Gaming , the ability to ingest and store vast amounts of temporal data — often reaching petabytes — with millisecond access latency has become increasingly vital.
Architecture. The streaming data store makes the system extensible to support other use-cases (e.g. System Components. The system will comprise of several micro-services each performing a separate task. Sending and receiving messages from other users. High Level Design. Fetching User Feed. Optimization.
Because microprocessors are so fast, computer architecture design has evolved towards adding various levels of caching between compute units and the main memory, in order to hide the latency of bringing the bits to the brains. This avoids thrashing caches too much for B and evens out the pressure on the L3 caches of the machine.
Engineers want their alerting system to be realtime, reliable, and actionable. A few years ago, we were paged by our SRE team due to our Metrics Alerting System falling behind — critical application health alerts reached engineers 45 minutes late! In other words, false positives are bad but false negatives are the absolute worst!
Organizations are depending more and more on distributed architectures to provide application services. Logging provides additional data but is typically viewed in isolation of a broader system context. Monitoring is capturing and displaying data, whereas observability can discern system health by analyzing its inputs and outputs.
GenAI is prone to erratic behavior due to unforeseen data scenarios or underlying system issues. Figure 1: Sample RAG architecture While this approach significantly improves the response quality of GenAI applications, it also introduces new challenges.
Complex information systems fail in unexpected ways. Observability gives developers and system operators real-time awareness of a highly distributed system’s current state based on the data it generates. With observability, teams can understand what part of a system is performing poorly and how to correct the problem.
Edgar helps Netflix teams troubleshoot distributed systems efficiently with the help of a summarized presentation of request tracing, logs, analysis, and metadata. The more complex a system, the more places to look for clues. In an earlier blog post, we discussed Telltale , our health monitoring system. What is Edgar?
This is where large-scale system migrations come into play. By collecting and analyzing key performance metrics of the service over time, we can assess the impact of the new changes and determine if they meet the availability, latency, and performance requirements. But what happens when this machinery needs a transformation?
AWS Lambda enables organizations to access many types of functions from AWS’ cloud-based services, such as: Data processing, to execute code based on triggers, system states, or user actions. You will likely need to write code to integrate systems and handle complex tasks or incoming network requests.
The whole system was quite complex, and starting to become brittle. Plus, the architecture of the Edge tier was evolving to a PaaS (platform as a service) model, and we had some tough decisions to make about how, and where, to handle identity token handling. The API server orchestrates backend systems to authenticate the user.
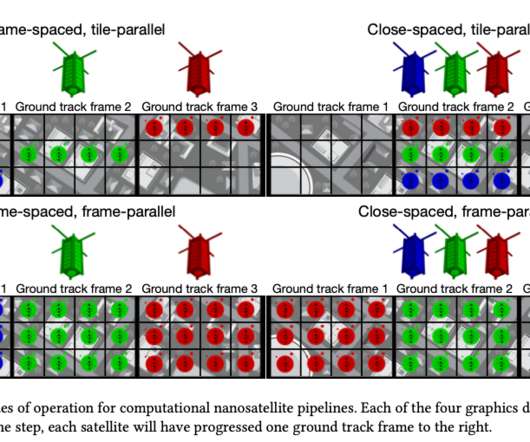
Orbital edge computing: nanosatellite constellations as a new class of computer system , Denby & Lucia, ASPLOS’20. Only space system architects don’t call it request-response, they call it a ‘ bent-pipe architecture.’. Nanosatellite systems have a GSD of around 3.0m/px. Satellites are changing! Physical constraints.
Organizations are rapidly adopting multicloud architectures to achieve the agility needed to drive customer success through new digital service channels. Park ‘N Fly’s business relies on successfully integrating its booking system with its custom-built kiosks located at its off-airport parking lots. “As
But we cannot search or present low latency retrievals from files Etc. Marken Architecture Marken’s architecture diagram is as follows. Marken Architecture Marken’s architecture diagram is as follows. We do that by excluding the following from all queries in our system.
A distributed storage system is foundational in today’s data-driven landscape, ensuring data spread over multiple servers is reliable, accessible, and manageable. This guide delves into how these systems work, the challenges they solve, and their essential role in businesses and technology.
Uptime Institute’s 2022 Outage Analysis report found that over 60% of system outages resulted in at least $100,000 in total losses, up from 39% in 2019. Microservices-based architectures and software containers enable organizations to deploy and modify applications with unprecedented speed. Make SLOs realistic.
This means a system that is not merely available but is also engineered with extensive redundant measures to continue to work as its users expect. Fault tolerance The ability of a system to continue to be dependable (both available and reliable) in the presence of certain component or subsystem failures.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content