This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Stream processing One approach to such a challenging scenario is stream processing, a computing paradigm and softwarearchitectural style for data-intensive software systems that emerged to cope with requirements for near real-time processing of massive amounts of data. This significantly increases event latency.
Site reliability engineering (SRE) is the practice of applying softwareengineering principles to operations and infrastructure processes to help organizations create highly reliable and scalable software systems. Solving for SR. For more about this ongoing conversation, see A guide to event-driven SRE-inspired DevOps.
Architecture. When a user requests for feed then there will be two parallel threads involved in fetching the user feeds to optimize for latency. This will not only reduce the overall latency in displaying the user-feeds to users but will also prevent re-computation of user-feeds. Sending and receiving messages from other users.
Site reliability engineering (SRE) is the practice of applying softwareengineering principles to operations and infrastructure processes to help organizations create highly reliable and scalable software systems. Solving for SR. For more about this ongoing conversation, see A guide to event-driven SRE-inspired DevOps.
The original assumptions and architectural choices were no longer viable. Overview The figure below depicts a simplified high-level architecture of a single Titus cluster (a.k.a We started seeing increased response latencies and leader servers running at dangerously high utilization.
This shift is leading more organizations to hire site reliability engineers to guarantee the reliability and resiliency of their services. How site reliability engineering affects organizations’ bottom line SRE applies the disciplines of softwareengineering to infrastructure management, both on-premises and in the cloud.
Plus, the architecture of the Edge tier was evolving to a PaaS (platform as a service) model, and we had some tough decisions to make about how, and where, to handle identity token handling. The system architecture now takes the form of: Notice that tokens never traverse past the Edge gateway / EAS boundary. We are serving over 2.5
As software development grows more complex, managing components using an automated onboarding process becomes increasingly important. This is especially crucial in microservice architectures, where the number of components can be overwhelming. Proper notifications or escalations are automated based on ownership information.
Old Gatekeeper Architecture This model had several problems associated with it: This process was completely I/O bound and put a lot of load on upstream systems. New Gatekeeper Architecture With this model, liveness evaluation is conceptually separated from the data retrieval from upstream systems.
Managing and operating asynchronous workflows can be difficult without the proper tools and architecture that puts observability, debugging, and tracing at the forefront. We are expected to process 1,000 watermarks for a single distribution in a minute, with non-linear latency growth as the number of watermarks increases.
It’s been clear for a while that software designed explicitly for the data center environment will increasingly want/need to make different design trade-offs to e.g. general-purpose systems software that you might install on your own machines. The desire for CPU efficiency and lower latencies is easy to understand. Enter Google!
Figure 1: Netflix ML Architecture Fact: A fact is data about our members or videos. Low-latency Queries To avoid downloading all of the fact data from s3 in a spark executor and then dropping it, we analyzed our query patterns and figured out that there is a way to only access the data that we are interested in.
Server-generated assets, since client-side generation would require the retrieval of many individual images, which would increase latency and time-to-render. To reduce latency, assets should be generated in an offline fashion and not in real time. Here’s what the final architecture looked like.
In particular, we’ll define plans and offers, review the legacy architecture and some of its shortcomings, and dig into our new architecture and some of its advantages. Let’s take a deeper look at the architecture, protocols, and systems involved. A plan is essentially a set of features with a price.
As our business scales globally, the demand for data is growing and the needs for scalable low latency incremental processing begin to emerge. It serves thousands of users, including data scientists, data engineers, machine learning engineers, softwareengineers, content producers, and business analysts, in various use cases.
For the inaugural O’Reilly survey on serverless architecture adoption, we were pleasantly surprised at the high level of response: more than 1,500 respondents from a wide range of locations, companies, and industries participated. As noted earlier, the majority of survey respondents are softwareengineers.
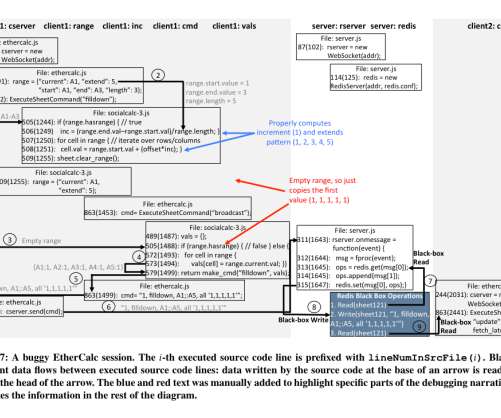
Second, Reverb enables speculative bug fix analysis … Third, Reverb supports wide-area debugging for applications whose server-side components use event-driven architectures. The problem. Reverb’s goal is to aid in debugging the client-side of JavaScript web applications.
As vendors and CSPs are faced with building these virtualized systems, it’s imperative to look at the softwareengineering methodologies that the IT industry has successfully applied to challenges at comparable scale. It’s accepted that new tooling is required, but there’s no consensus yet on standards.
As vendors and CSPs are faced with building these virtualized systems, it’s imperative to look at the softwareengineering methodologies that the IT industry has successfully applied to challenges at comparable scale. It’s accepted that new tooling is required, but there’s no consensus yet on standards.
When it comes to innovation, most of CMS solutions are constrained by their legacy architecture (read strong coupling between content management and content presentation) which makes it difficult to serve content to new types of emerging channels such as apps and devices. Gone the days when you required to have big fat-contract with Akamai.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


























Let's personalize your content