This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
With the evolution of modern applications serving increasing needs for real-time data processing and retrieval, scalability does, too. However, the process for effectively scaling Elasticsearch can be nuanced, since one needs a proper understanding of the architecture behind it and of performance tradeoffs.
Scalable Annotation Service — Marken by Varun Sekhri , Meenakshi Jindal Introduction At Netflix, we have hundreds of micro services each with its own data models or entities. The service should be able to serve real-time, aka UI, applications so CRUD and search operations should be achieved with low latency.
This article outlines the key differences in architecture, performance, and use cases to help determine the best fit for your workload. RabbitMQ follows a message broker model with advanced routing, while Kafkas event streaming architecture uses partitioned logs for distributed processing. What is RabbitMQ?
Handling multimodal data spanning text, images, videos, and sensor inputs requires resilient architecture to manage the diversity of formats and scale.
This scenario underscored the need for a new recommender system architecture where member preference learning is centralized, enhancing accessibility and utility across different models. Yet, many are confined to a brief temporal window due to constraints in serving latency or training costs.
By: Rajiv Shringi , Oleksii Tkachuk , Kartik Sathyanarayanan Introduction In our previous blog post, we introduced Netflix’s TimeSeries Abstraction , a distributed service designed to store and query large volumes of temporal event data with low millisecond latencies. Today, we’re excited to present the Distributed Counter Abstraction.
With the rise of microservices architecture , there has been a rapid acceleration in the modernization of legacy platforms, leveraging cloud infrastructure to deliver highly scalable, low-latency, and more responsive services. Why Use Spring WebFlux?
Key Takeaways RabbitMQ improves scalability and fault tolerance in distributed systems by decoupling applications, enabling reliable message exchanges. This decoupling is crucial in modern architectures where scalability and fault tolerance are paramount.
Werner Vogels weblog on building scalable and robust distributed systems. a Fast and Scalable NoSQL Database Service Designed for Internet Scale Applications. The original Dynamo design was based on a core set of strong distributed systems principles resulting in an ultra-scalable and highly reliable database system.
The new Amazon capability enables customers to improve the startup latency of their functions from several seconds to as low as sub-second (up to 10 times faster) at P99 (the 99th latency percentile). This can cause latency outliers and may lead to a poor end-user experience for latency-sensitive applications.
When undertaking system migrations, one of the main challenges is establishing confidence and seamlessly transitioning the traffic to the upgraded architecture without adversely impacting the customer experience. It provides a good read on the availability and latency ranges under different production conditions.
Many organizations today rely on cloud-native applications for their scalability and agility, among other benefits. Serverless benefits include the following: Dynamic scalability. Reduced latency. Serverless architecture makes it possible to host code anywhere, rather than relying on an origin server. Cost-effectiveness.
Architecture. When a user requests for feed then there will be two parallel threads involved in fetching the user feeds to optimize for latency. This will not only reduce the overall latency in displaying the user-feeds to users but will also prevent re-computation of user-feeds. Sending and receiving messages from other users.
Customers can use AWS Lambda Response Streaming to improve performance for latency-sensitive applications and return larger payload sizes. Streaming raises the default 6 MB hard limit to a 20 MB soft limit, adding greater scalability and flexibility to their applications. What is a Lambda serverless function?
To this end, we developed a Rapid Event Notification System (RENO) to support use cases that require server initiated communication with devices in a scalable and extensible manner. Architecture As shown in the diagram above, the RENO service can be broken down into the following components.
Central to this infrastructure is our use of multiple online distributed databases such as Apache Cassandra , a NoSQL database known for its high availability and scalability. Data Model At its core, the KV abstraction is built around a two-level map architecture.
As dynamic systems architectures increase in complexity and scale, IT teams face mounting pressure to track and respond to conditions and issues across their multi-cloud environments. Dynatrace news. As teams begin collecting and working with observability data, they are also realizing its benefits to the business, not just IT.
Stream processing One approach to such a challenging scenario is stream processing, a computing paradigm and software architectural style for data-intensive software systems that emerged to cope with requirements for near real-time processing of massive amounts of data. This significantly increases event latency.
Because of its scalability and distributed architecture, thousands of companies trust it to run their cloud and hybrid-based workloads at high availability without compromising performance. Below is an example Dynatrace problem card, which shows how a spike in Cassandra write latency impacts your application.
The original assumptions and architectural choices were no longer viable. Overview The figure below depicts a simplified high-level architecture of a single Titus cluster (a.k.a We started seeing increased response latencies and leader servers running at dangerously high utilization.
While we were able to put out the immediate fire by disabling the newly created alerts, this incident raised some critical concerns around the scalability of our alerting system. It became clear to us that we needed to solve the scalability problem with a fundamentally different approach. OK, Results?
Rajiv Shringi Vinay Chella Kaidan Fullerton Oleksii Tkachuk Joey Lynch Introduction As Netflix continues to expand and diversify into various sectors like Video on Demand and Gaming , the ability to ingest and store vast amounts of temporal data — often reaching petabytes — with millisecond access latency has become increasingly vital.
Site reliability engineering (SRE) is the practice of applying software engineering principles to operations and infrastructure processes to help organizations create highly reliable and scalable software systems. ” According to Google, “SRE is what you get when you treat operations as a software problem.” Solving for SR.
This architecture shift greatly reduced the processing latency and increased system resiliency. We expanded pipeline support to serve our studio/content-development use cases, which had different latency and resiliency requirements as compared to the traditional streaming use case.
It supports both high throughput services that consume hundreds of thousands of CPUs at a time, and latency-sensitive workloads where humans are waiting for the results of a computation. The third generation, called Reloaded , has been online for about seven years and has proven to be stable and massively scalable.
Site reliability engineering (SRE) is the practice of applying software engineering principles to operations and infrastructure processes to help organizations create highly reliable and scalable software systems. ” According to Google, “SRE is what you get when you treat operations as a software problem.” Solving for SR.
Organizations are depending more and more on distributed architectures to provide application services. For example, when monitoring a database, you’ll want to know about any latency when writing data to a disk or average query response time. DevOps practitioners struggle to maintain highly available and scalable applications.
Allegro experimented with different performance optimization options to improve Apache Kafka producer tail latency and eventually switched all its clusters to the XFS filesystem. The company used Kafka protocol sniffing, JVM profiling, and eBPF, which proved instrumental in identifying and eliminating performance bottlenecks.
In particular, we’ll define plans and offers, review the legacy architecture and some of its shortcomings, and dig into our new architecture and some of its advantages. Let’s take a deeper look at the architecture, protocols, and systems involved. A plan is essentially a set of features with a price.
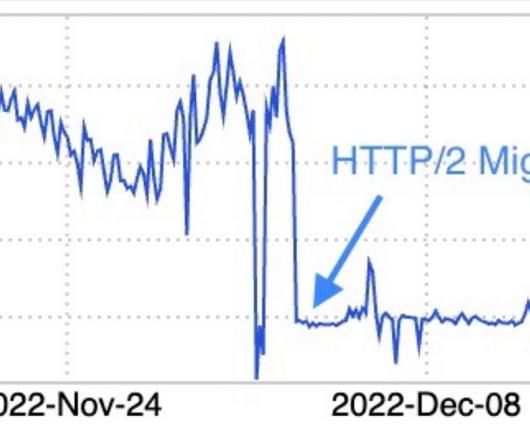
LinkedIn was able to dramatically improve the scalability and performance of its Espresso database by migrating it from HTTP1.1 to HTTP2, resulting in a reduction in the number of connections, latency, and garbage collection times. By Rafal Gancarz
Lambda’s highly efficient, on-demand computing environment aligns with today’s microservices-centric architectures, and readily integrates with other popular AWS offerings that an organization may already be using. AWS continues to improve how it handles latency issues. It helps SRE teams automate responses.
Metrics are measures of critical system values, such as CPU utilization or average write latency to persistent storage. They are particularly important in distributed systems, such as microservices architectures. Observability platforms are becoming essential as the complexity of cloud-native architectures increases.
Today, I want to explore the Amazon ECS architecture and what this architecture enables. To be robust and scalable, this key/value store needs to be distributed for durability and availability, to protect against network partitions or hardware failures. Let’s talk about what Amazon ECS is actually doing.
By bringing computation closer to the data source, edge-based deployments reduce latency, enhance real-time capabilities, and optimize network bandwidth. Increased latency during peak loads. Introduce scalable microservices architectures to distribute computational loads efficiently.
At Netflix, we also heavily embrace a microservice architecture that emphasizes separation of concerns. The data warehouse is not designed to serve point requests from microservices with low latency. Therefore, we must efficiently move data from the data warehouse to a global, low-latency and highly-reliable key-value store.
The breadth of fully-featured services, the pay-as-you-go scalability, and the agility of cloud platforms enable organizations to expand their modern approaches to building and managing digital services in a way they can’t with on-premises apps and infrastructure. Increased scalability. Reduced cost. Inconsistent performance.
This is especially crucial in microservice architectures, where the number of components can be overwhelming. Dedicated configuration files are used to create teams and maintain relevant information, such as responsibilities and contact details, in a scalable and automated way.
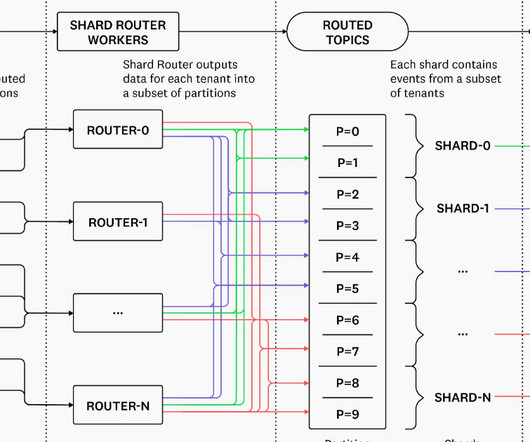
The challenge, then, is to be able to ingest and process these events in a scalable manner, i.e., scaling with the number of devices, which will be the focus of this blog post. System Setup Architecture The following diagram summarizes the architecture description: Figure 1: Event-sourcing architecture of the Device Management Platform.
Datadog created a dedicated data ingestion architecture offering exactly-once semantics for their third-generation event store, Husky. The event-driven architecture (EDA) can accommodate bursts in traffic in the multi-tenant platform with reasonable ingestion latency and acceptable operational costs. By Rafal Gancarz
As VMAF evolves and is integrated with more encoding and streaming workflows within Netflix, we need scalable ways of fostering video quality innovations. The Reloaded system is a well-matured and scalable system, but its monolithic architecture can slow down rapid innovation. via bug fixes). We call this system Cosmos.
Managing and operating asynchronous workflows can be difficult without the proper tools and architecture that puts observability, debugging, and tracing at the forefront. We are expected to process 1,000 watermarks for a single distribution in a minute, with non-linear latency growth as the number of watermarks increases.
Additionally, instead of implementing business logic by composing multiple individual Processors together, users could express their logic in a single SQL query, avoiding the additional resource and latency overhead that came from multiple Flink jobs and Kafka topics. This makes the query service lightweight, scalable, and execution agnostic.
In this blog post, I will explain how these three new capabilities empower you to build applications with distributed systems architecture and create responsive, reliable, and high-performance applications using DynamoDB that work at any scale. Amazon Redshift) and Elasticsearch machines. DynamoDB Cross-region Replication.
Werner Vogels weblog on building scalable and robust distributed systems. For example, the most fundamental abstraction trade-off has always been latency versus throughput. These trade-offs have even impacted the way the lowest level building blocks in our computer architectures have been designed. All Things Distributed.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content