This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
However, the process for effectively scaling Elasticsearch can be nuanced, since one needs a proper understanding of the architecture behind it and of performance tradeoffs. This extra network overhead will easily result in increased latency compared to a single-node architecture where data access is straightforward.
Handling multimodal data spanning text, images, videos, and sensor inputs requires resilient architecture to manage the diversity of formats and scale.
Recently, we added another powerful tool to our arsenal: neural networks for video downscaling. In this tech blog, we describe how we improved Netflix video quality with neural networks, the challenges we faced and what lies ahead. How can neural networks fit into Netflix video encoding?
This article outlines the key differences in architecture, performance, and use cases to help determine the best fit for your workload. RabbitMQ follows a message broker model with advanced routing, while Kafkas event streaming architecture uses partitioned logs for distributed processing. What is RabbitMQ? What is Apache Kafka?
This decoupling is crucial in modern architectures where scalability and fault tolerance are paramount. Imagine a bustling city with a network of well-coordinated traffic signals; RabbitMQ ensures that messages (traffic) flow smoothly from producers to consumers, navigating through various routes without congestion.
Example 1: Architecture boundaries. First, they took a big step back and looked at their end-to-end architecture (Figure 2). SLO dashboard defined by architectural boundary. In their new dashboard, they added dimensions for load, latency, and open problems for each component. Not all attempts succeed on the first try.
The new Amazon capability enables customers to improve the startup latency of their functions from several seconds to as low as sub-second (up to 10 times faster) at P99 (the 99th latency percentile). This can cause latency outliers and may lead to a poor end-user experience for latency-sensitive applications.
Architecture. When a user requests for feed then there will be two parallel threads involved in fetching the user feeds to optimize for latency. This will not only reduce the overall latency in displaying the user-feeds to users but will also prevent re-computation of user-feeds. Sending and receiving messages from other users.
These include challenges with tail latency and idempotency, managing “wide” partitions with many rows, handling single large “fat” columns, and slow response pagination. Data Model At its core, the KV abstraction is built around a two-level map architecture. Useful for keeping “n-newest” or prefix path deletion.
Cloud-based application architectures commonly leverage microservices. High latency or lack of responses. You receive an alert message from Dynatrace (your infrastructure observability hub) letting you know that the average response latency of all deployed APIs has tripled. Soaring number of active connections.
The original assumptions and architectural choices were no longer viable. Overview The figure below depicts a simplified high-level architecture of a single Titus cluster (a.k.a We started seeing increased response latencies and leader servers running at dangerously high utilization.
Reduced latency. Serverless architecture makes it possible to host code anywhere, rather than relying on an origin server. By using cloud providers with multiple server sites, organizations can reduce function latency for end users. Architectural complexity. Optimizes resources. Difficult to test. Difficult to monitor.
Table 1: Movie and File Size Examples Initial Architecture A simplified view of our initial cloud video processing pipeline is illustrated in the following diagram. Figure 1: A Simplified Video Processing Pipeline With this architecture, chunk encoding is very efficient and processed in distributed cloud computing instances.
Motivation With the rapid growth in Netflix member base and the increasing complexity of our systems, our architecture has evolved into an asynchronous one that enables both online and offline computation. This network connection heterogeneity made choosing a single delivery model difficult.
Microservices-based architectures and software containers enable organizations to deploy and modify applications with unprecedented speed. The growing amount of data processed at the network edge, where failures are more difficult to prevent, magnifies complexity. However, cloud complexity has made software delivery challenging.
We tried a few iterations of what this new service should look like, and eventually settled on a modern architecture that aimed to give more control of the API experience to the client teams. For us, it means that we now need to have ~15 MDN tabs open when writing routes :) Let’s briefly discuss the architecture of this microservice.
Customers can use AWS Lambda Response Streaming to improve performance for latency-sensitive applications and return larger payload sizes. Customers can use response streaming to achieve the following: Improve Time to First Byte (TTFB) performance for latency-sensitive applications. Return larger payload sizes. How does Dynatrace help?
Besides the traditional system hardware, storage, routers, and software, ITOps also includes virtual components of the network and cloud infrastructure. A network administrator sets up a network, manages virtual private networks (VPNs), creates and authorizes user profiles, allows secure access, and identifies and solves network issues.
Snap: a microkernel approach to host networking Marty et al., This paper describes the networking stack, Snap , that has been running in production at Google for the last three years+. The desire for CPU efficiency and lower latencies is easy to understand. SOSP’19. Emphasis mine). It reminds me of ZeroMQ.
This architecture shift greatly reduced the processing latency and increased system resiliency. We expanded pipeline support to serve our studio/content-development use cases, which had different latency and resiliency requirements as compared to the traditional streaming use case. divide the input video into small chunks 2.
Because microprocessors are so fast, computer architecture design has evolved towards adding various levels of caching between compute units and the main memory, in order to hide the latency of bringing the bits to the brains. This avoids thrashing caches too much for B and evens out the pressure on the L3 caches of the machine.
Rajiv Shringi Vinay Chella Kaidan Fullerton Oleksii Tkachuk Joey Lynch Introduction As Netflix continues to expand and diversify into various sectors like Video on Demand and Gaming , the ability to ingest and store vast amounts of temporal data — often reaching petabytes — with millisecond access latency has become increasingly vital.
Because Google offers its own Google Cloud Architecture Framework and Microsoft its Azure Well-Architected Framework , organizations that use a combination of these platforms triple the challenge of integrating their performance frameworks into a cohesive strategy. SRG validates the status of the resiliency SLOs for the experiment period.
Today we are excited to announce latency heatmaps and improved container support for our on-host monitoring solution?—?Vector?—?to Remotely view real-time process scheduler latency and tcp throughput with Vector and eBPF What is Vector? to the broader community. Vector is open source and in use by multiple companies.
A few years ago, we decided to address this complexity by spinning up a new initiative, and eventually a new team, to move the complex handling of user and device authentication, and various security protocols and tokens, to the edge of the network, managed by a set of centralized services, and a single team. We are serving over 2.5
You will likely need to write code to integrate systems and handle complex tasks or incoming network requests. Lambda’s highly efficient, on-demand computing environment aligns with today’s microservices-centric architectures, and readily integrates with other popular AWS offerings that an organization may already be using.
Today, I want to explore the Amazon ECS architecture and what this architecture enables. The pool of resources, at this time, is the CPU, memory, and networking resources of Amazon EC2 instances as partitioned by containers. networks ports, memory, CPU, etc). Let’s talk about what Amazon ECS is actually doing.
We are standing on the eve of the 5G era… 5G, as a monumental shift in cellular communication technology, holds tremendous potential for spurring innovations across many vertical industries, with its promised multi-Gbps speed, sub-10 ms low latency, and massive connectivity. The first 5G networks are now deployed and operational.
System Setup Architecture The following diagram summarizes the architecture description: Figure 1: Event-sourcing architecture of the Device Management Platform. When a new hardware device is connected, the Local Registry detects and collects a set of information about it, such as networking information and ESN.
By bringing computation closer to the data source, edge-based deployments reduce latency, enhance real-time capabilities, and optimize network bandwidth. Increased latency during peak loads. Inconsistent network performance affecting data synchronization. Managing data residency while leveraging global edge networks.
While this abundance of dashboards and information is by no means unique to Netflix, it certainly holds true within our microservices architecture. A span: Represents a unit of work, such as a network call from one service to another (a client/server relationship) or a purely internal action (e.g., starting and finishing a method).
Azure Virtual Network Gateways. Our customers have frequently requested support for this first new batch of services, which cover databases, big data, networks, and computing. Azure DB for PostgreSQL. Azure SQL Managed Instance. Azure HDInsight. Azure Front Door. Azure Traffic Manager.
In the back to basics readings this week I am re-reading a paper from 1995 about the work that I did together with Thorsten on solving the problem of end-to-end low-latency communication on high-speed networks. The lack of low-latency made that distributed systems (e.g.
In summary, the Dynatrace platform enables banks to do the following: Capture any data type: logs, metrics, traces, topology, behavior, code, metadata, network, security, web, and real-user monitoring data, and business events. Maximize performance for high-frequency and low-latency trading strategies. Break down data silos.
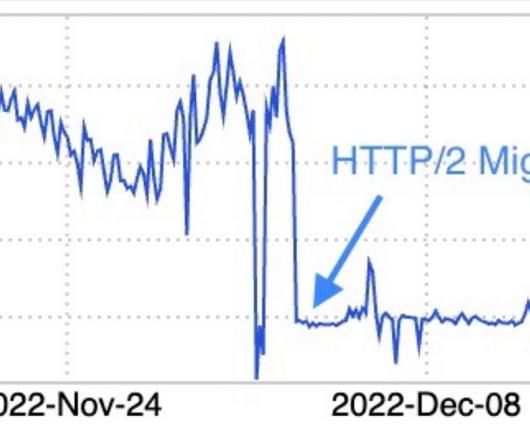
to HTTP2, resulting in a reduction in the number of connections, latency, and garbage collection times. LinkedIn was able to dramatically improve the scalability and performance of its Espresso database by migrating it from HTTP1.1 To achieve these gains, the team had to optimize the Netty’s default HTTP2 stack to make it fit their needs.
RISELabs , those wonderfully innovative folks over at Berkeley, have uplifted their Anna datatabase —a shared-nothing, thread-per-core architecture to achieve lightning-fast speeds by avoiding all coordination mechanisms—to become cloud-aware. This increases the cores and network bandwidth available to serve common requests.
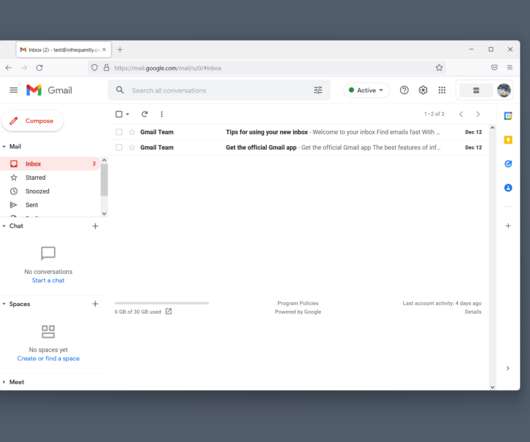
Here are two renderings of the same Gmail inbox in different architectural styles: one based on Ajax, and the other on "basic" HTML : The Ajax version of Gmail loads 4.8MiB of resources, including 3.8MiB of JavaScript to load an inbox containing two messages. Today's web architecture debates (e.g.
Failure can occur due to a myriad of reasons: misbehaving clients that trigger a retry storm, an under-scaled service in the backend, a bad deployment, a network blip, or issues with the cloud provider. Those two metrics are approximate indicators of failures and latency. Let’s dig into how we accomplished this.
This first post looks at the general architecture of proxy browsers with a performance focus. Typical Browser Architecture. That’s a very simplified list and some of them can happen in parallel, but it’s a good enough representation for the purpose of highlighting how proxy browser architecture differs. All of that came later.
In this fast-paced ecosystem, two vital elements determine the efficiency of this traffic: latency and throughput. LATENCY: THE WAITING GAME Latency is like the time you spend waiting in line at your local coffee shop. All these moments combined represent latency – the time it takes for your order to reach your hands.
Building general purpose architectures has always been hard; there are often so many conflicting requirements that you cannot derive an architecture that will serve all, so we have often ended up focusing on one side of the requirements that allow you to serve that area really well.
It keeps application processing closer to the data to maintain higher bandwidth and lower latencies, adheres to compliance regulations that don’t yet approve cloud managed services, and allows data center capital investments to be fully amortized before moving to the cloud.
Key Takeaways Redis offers complex data structures and additional features for versatile data handling, while Memcached excels in simplicity with a fast, multi-threaded architecture for basic caching needs. However, Redis, with its single-threaded architecture, may encounter bottlenecks with large numbers of concurrent connections.
This article will list some of the use cases of AutoOptimize, discuss the design principles that help enhance efficiency, and present the high-level architecture. These principles reduce resource usage by being more efficient and effective while lowering the end-to-end latency in data processing. More processing resources.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content