This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
To this end, we developed a Rapid Event Notification System (RENO) to support use cases that require server initiated communication with devices in a scalable and extensible manner. In this blog post, we will give an overview of the Rapid Event Notification System at Netflix and share some of the learnings we gained along the way.
This integration simplifies the process of embedding Dynatrace full-stack observability directly into custom Amazon Machine Images (AMIs). VMware migration support for seamless transitions For enterprises transitioning VMware-based workloads to the cloud, the process can be complex and resource-intensive.
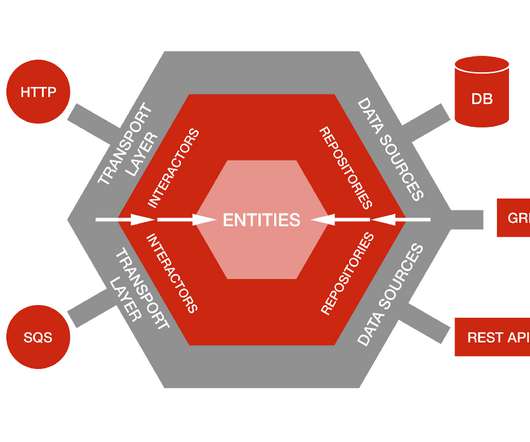
by Damir Svrtan and Sergii Makagon As the production of Netflix Originals grows each year, so does our need to build apps that enable efficiency throughout the entire creative process. We decided to build our app based on principles behind Hexagonal Architecture and Uncle Bob’s Clean Architecture.
By: Rajiv Shringi , Oleksii Tkachuk , Kartik Sathyanarayanan Introduction In our previous blog post, we introduced Netflix’s TimeSeries Abstraction , a distributed service designed to store and query large volumes of temporal event data with low millisecond latencies. This process can also be used to track the provenance of increments.
RabbitMQ is designed for flexible routing and message reliability, while Kafka handles high-throughput event streaming and real-time data processing. This article outlines the key differences in architecture, performance, and use cases to help determine the best fit for your workload. What is RabbitMQ? What is Apache Kafka?
Business events powered by our new Grail™ data lakehouse and by other Dynatrace platform technologies ensures the real-time precision that business and IT teams need to make data-driven decisions and improve business outcomes. Business events deliver the industry’s broadest, deepest, and easiest access to your critical business data.
It requires a state-of-the-art system that can track and process these impressions while maintaining a detailed history of each profiles exposure. In this multi-part blog series, we take you behind the scenes of our system that processes billions of impressions daily.
A Data Movement and Processing Platform @ Netflix By Bo Lei , Guilherme Pires , James Shao , Kasturi Chatterjee , Sujay Jain , Vlad Sydorenko Background Realtime processing technologies (A.K.A stream processing) is one of the key factors that enable Netflix to maintain its leading position in the competition of entertaining our users.
The volume of data and events grows in tandem with the rising complexity of IT infrastructure. While SNMP allows you to query monitored devices for performance information, SNMP traps are used to proactively report certain types of events. These can range from routine state transition events to critical problem reports.
Part 3: System Strategies and Architecture By: VarunKhaitan With special thanks to my stunning colleagues: Mallika Rao , Esmir Mesic , HugoMarques This blog post is a continuation of Part 2 , where we cleared the ambiguity around title launch observability at Netflix. The request schema for the observability endpoint.
This scenario underscored the need for a new recommender system architecture where member preference learning is centralized, enhancing accessibility and utility across different models. To harness this data effectively, we employ a process of interaction tokenization, ensuring meaningful events are identified and redundancies are minimized.
In the labyrinth of data-driven architectures, the challenge of data integration—fusing data from disparate sources into a coherent, usable form — stands as one of the cornerstones. However, it would be a mistake to dismiss batch processing as an antiquated approach. Systems were not equipped to handle multiple tasks simultaneously.
This powerful tool can be leveraged across various environments, including production, to enhance development processes and ensure robust application performance. Many developers attempt to mitigate this challenge with logs, but thats a tedious and error-prone process. Distributed services involve multiple processes and runtimes.
To get a better understanding of AWS serverless, we’ll first explore the basics of serverless architectures, review AWS serverless offerings, and explore common use cases. Serverless architecture: A primer. Serverless architecture shifts application hosting functions away from local servers onto those managed by providers.
This decoupling is crucial in modern architectures where scalability and fault tolerance are paramount. The architecture of RabbitMQ is meticulously designed for complex message routing, enabling dynamic and flexible interactions between producers and consumers. Erlang is the backbone of RabbitMQ clustering.
Greenplum Database is a massively parallel processing (MPP) SQL database that is built and based on PostgreSQL. In this blog post, we explain what Greenplum is, and break down the Greenplum architecture, advantages, major use cases, and how to get started. The Greenplum Architecture. The Greenplum Architecture.
This article focuses on how we … The post Real-Time Exactly-Once Ad EventProcessing with Apache Flink, Kafka, and Pinot appeared first on Uber Engineering Blog. With this new ability came new challenges that needed to be solved at Uber, such as systems for ad auctions, bidding, attribution, reporting, and more.
by Jun He , Yingyi Zhang , and Pawan Dixit Incremental processing is an approach to process new or changed data in workflows. The key advantage is that it only incrementally processes data that are newly added or updated to a dataset, instead of re-processing the complete dataset.
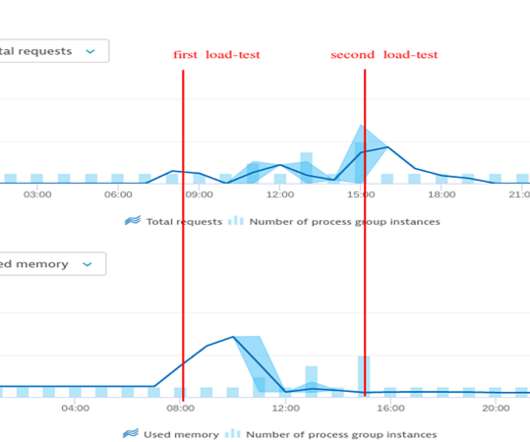
We want to share how Dynatrace helped us identify and fix memory leaks in one of the most central and critical components within Keptn: our event broker. We were in the process of developing a new feature and wanted to make sure it could handle the expected load behavior. It happened in June 2020. Houston, we have a problem!
Grail architectural basics. The aforementioned principles have, of course, a major impact on the overall architecture. A data lakehouse addresses these limitations and introduces an entirely new architectural design. Ingest and process with Grail. It’s based on cloud-native architecture and built for the cloud.
Additionally, predictions based on historical data are reactive, solely relying on past information to anticipate future events, and can’t prevent all new or emerging issues. Automatic root cause detection Modern, complex, and distributed environments generate a substantial number of events.
Transforming an application from monolith to microservices-based architecture can be daunting, and knowing where to start can be difficult. Unsurprisingly, organizations are breaking away from monolithic architectures and moving toward event-driven microservices. Migration is time-consuming and involved.
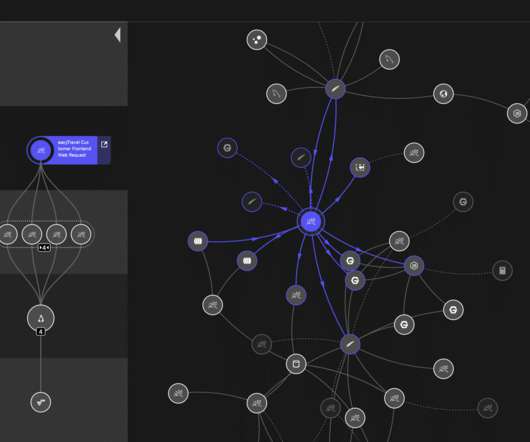
In a federated graph architecture, how can we answer such a query given that each entity is served by its own service? Sample GraphQL query To keep the index up to date, events are used to trigger a reindexing operation for individual entities when they change. however, application events are also supported when necessary.
As dynamic systems architectures increase in complexity and scale, IT teams face mounting pressure to track and respond to conditions and issues across their multi-cloud environments. An advanced observability solution can also be used to automate more processes, increasing efficiency and innovation among Ops and Apps teams.
In the vibrant world of microservices and event-driven architectures, messaging queues have emerged as a critical component, enabling asynchronous communication, decoupling systems, and unlocking scalability. However, with a vibrant landscape of options, choosing the optimal queue can feel like navigating a complex maze.
OpenTelemetry Astronomy Shop demo application architecture diagram. docker compose up --no-build If you use ARM architecture (for example, a MacBook with Apple silicon), remove the --no-build option to build the images locally. If you select one of the GetProduct spans, you can see the detailed span event showing the reason.
Autonomous Cloud Enablement (ACE) and Keptn – the Event-Driven Autonomous Cloud Control Plane – are helping our Dynatrace customers to automate their delivery and operations processes. This is now where Keptn, our Event-Driven Control Plane for Autonomous Cloud Control Plane, comes into the picture! Dynatrace news.
We’re delighted to share that IBM and Dynatrace have joined forces to bring the Dynatrace Operator, along with the comprehensive capabilities of the Dynatrace platform, to Red Hat OpenShift on the IBM Power architecture (ppc64le). It also detects new containers and injects OneAgent code modules into application pods.
Traditional analytics and AI systems rely on statistical models to correlate events with possible causes. Causal AI is a different approach that goes beyond event correlations to understand the underlying reasons for trends and patterns. It uses fault-tree analysis to identify the component events that cause outcomes at a higher level.
Trace your application Imagine a microservices architecture with hundreds of dependencies. This architecture also means you’re not required to determine your log data use cases beforehand or while analyzing logs within the new logs app. Interact with data intuitively and easily and benefit from immediate, AI-supported insights.
The app scans all incoming logs for various patterns and uses DQL (Dynatrace Query Language) to collect context like hosts, other processes, and traces for each potential problem. These events require triage, analysis, and remediation by the owners of the affected resources.
In this three-part blog post series, we introduce you to Psyberg , our incremental data processing framework designed to tackle such challenges! We’ll discuss batch data processing, the limitations we faced, and how Psyberg emerged as a solution. Let’s dive in! What is late-arriving data? How does late-arriving data impact us?
Also, these modern, cloud-native architectures produce an immense volume, velocity, and variety of data. Logs and events play an essential role in this mix; they include critical information which can’t be found anywhere else, like details on transactions, processes, users and environment changes.
Log monitoring, log analysis, and log analytics are more important than ever as organizations adopt more cloud-native technologies, containers, and microservices-based architectures. A log is a detailed, timestamped record of an event generated by an operating system, computing environment, application, server, or network device.
Intertwined processes slow down automation at scale. Developing applications based on modern architectures comes with a challenge for release automation: integrating delivery of many services with similar processes but often with different technologies and tools along the delivery pipelines. Dynatrace news.
This blog post guides you through configuring Dynatrace to automate CI/CD processes to achieve these objectives. Dynatrace observability architecture can be classified into three layers: Orchestration (Dynatrace) CI/CD toolset (Jenkins / Chef / Puppet / Bamboo, etc.)
Logs highlight observability challenges Ingesting, storing, and processing the unprecedented explosion of data from sources such as software as a service, multicloud environments, containers, and serverless architectures can be overwhelming for today’s organizations. Ingesting, processing, retaining, and querying logs.
DevSecOps teams can address this unsettling tradeoff by automating processes throughout the SDLC, centralizing application configuration with a shared set of tools, and using observability platforms to gain visibility into code-quality lapses, security gaps, and other software development issues.
Flow Exporter The Flow Exporter is a sidecar that uses eBPF tracepoints to capture TCP flows at near real time on instances that power the Netflix microservices architecture. Flow Collector consumes two data streams, the IP address change events from Sonar via Kafka and eBPF flow log data from the Flow Exporter sidecars. What is BPF?
With this enhancement, Dynatrace can respond to any event and execute synthetic monitors within your workflows to assess the impact of events on user experience. Depending on the outcome, workflows can notify your teams by creating a Jira ticket, sending a Slack message, or initiating a remediation process.
Our Journey so Far Over the past year, we’ve implemented the core infrastructure pieces necessary for a federated GraphQL architecture as described in our previous post: Studio Edge Architecture The first Domain Graph Service (DGS) on the platform was the former GraphQL monolith that we discussed in our first post (Studio API).
This architecture also means you are not required to determine your log data use cases beforehand or while analyzing logs within the new logs app. How logs are ingested Dynatrace offers OpenPipeline to ingest, process, and persist any data from any source at any scale.
Further, these resources support countless Kubernetes clusters and Java-based architectures. Each process could generate multiple log entries, adding up to terabytes of data every day. Lining up traces, logs, and metrics based on user events and timestamps provides the most complete picture of full-stack dependencies.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content