This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This scenario underscored the need for a new recommender system architecture where member preference learning is centralized, enhancing accessibility and utility across different models. Yet, many are confined to a brief temporal window due to constraints in serving latency or training costs.
Behind these perfect moments of entertainment is a complex mechanism, with numerous gears and cogs working in harmony. By collecting and analyzing key performance metrics of the service over time, we can assess the impact of the new changes and determine if they meet the availability, latency, and performance requirements.
For example, a latency increase is less critical than error rate increase and some error codes are less critical than others. A healthy Netflix service enables us to entertain the world. Client metrics and QoE changes. Alerts triggered by our alerting platform. Telltale is application monitoring simplified.
entertainment?—?and Server-generated assets, since client-side generation would require the retrieval of many individual images, which would increase latency and time-to-render. To reduce latency, assets should be generated in an offline fashion and not in real time. Here’s what the final architecture looked like.
In particular, we’ll define plans and offers, review the legacy architecture and some of its shortcomings, and dig into our new architecture and some of its advantages. Let’s take a deeper look at the architecture, protocols, and systems involved. How, when, and where people want to be entertained continues to evolve.
You need a lot of software engineers and the willingness to rewrite a lot of software to entertain that idea. Here are the bombshell paragraphs: Our datacenter applications seek ever more CPU-efficient and lower-latency communication, which Pony Express delivers. The desire for CPU efficiency and lower latencies is easy to understand.
Other industries using Amazon EC2 for HPC-style workloads include pharmaceuticals, oil exploration, industrial and automotive design, media and entertainment, and more. When instances are placed in a cluster they have access to low latency, non-blocking 10 Gbps networking when communicating the other instances in the cluster.
Efficient microservices The technique of creating applications using microservices architecture makes it possible to divide an application into smaller, independently deployable services, which simplifies development and maintenance. Just consider the sheer number of people who stream Netflix every night!
Unfortunately, many organizations lack the tools, infrastructure, and architecture needed to unlock the full value of that data. Processing such high data volumes requires robust infrastructure and scalable architecture designed for high performance and high availability. In a world where 2.5
You might imagine that at some point we had a major scaling crises, where it looked like we'd fail due to an architectural bottleneck, and engineers worked long nights and weekends to save Netflix from certain disaster. A latency outlier issue that happened every 15 minutes. That'd make a great story, but it didn't happen.
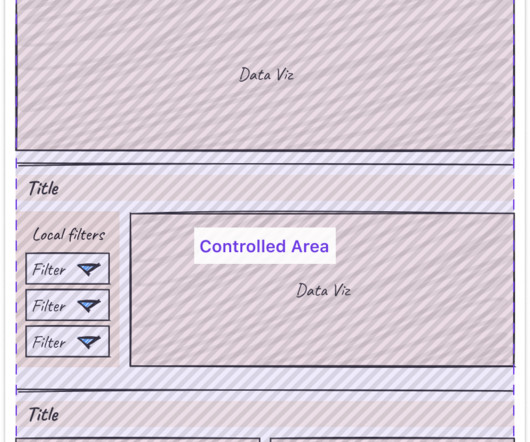
Experiment Workflow Architecture diagram of the Page Simulation System The lifecycle of an experiment starts when a user (Engineer, Researcher, Data Scientist or Product Manager) configures an experiment and submits it for execution (detailed below). During metrics computation we collect each metric at the level of variant and stratum.
Experiment Workflow Architecture diagram of the Page Simulation System The lifecycle of an experiment starts when a user (Engineer, Researcher, Data Scientist or Product Manager) configures an experiment and submits it for execution (detailed below). During metrics computation we collect each metric at the level of variant and stratum.
Experiment Workflow Architecture diagram of the Page Simulation System The lifecycle of an experiment starts when a user (Engineer, Researcher, Data Scientist or Product Manager) configures an experiment and submits it for execution (detailed below). During metrics computation we collect each metric at the level of variant and stratum.
A few questions to ask yourself when considering the information architecture of your appinclude: Do you have different user groups trying to accomplish different things? Align on Performance Expectations A major challenge during development was managing API latency. Split them into different apps or different views.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




















Let's personalize your content