This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
After years of working in the intricate world of software engineering, I learned that the most beautiful solutions are often those unseen: backends that hum along, scaling with grace and requiring very little attention. Developers could understand and manage the entire systems intricacies.
What would a totally new search enginearchitecture look like? Search engines, and more generally, information retrieval systems, play a central role in almost all of today’s technical stacks. After more than 30 years of evolution since TREC, search engines continue to grow and evolve, leading to new challenges.
System resilience stands as the key requirement for e-commerce platforms during scaling operations to keep services operational and deliver performance excellence to users. We have developed a microservices architecture platform that encounters sporadic system failures when faced with heavy traffic events.
To this end, we developed a Rapid Event Notification System (RENO) to support use cases that require server initiated communication with devices in a scalable and extensible manner. In this blog post, we will give an overview of the Rapid Event Notification System at Netflix and share some of the learnings we gained along the way.
DevOps and security teams managing today’s multicloud architectures and cloud-native applications are facing an avalanche of data. Such fragmented approaches fall short of giving teams the insights they need to run IT and site reliability engineering operations effectively.
Our wider Studio Engineering Organization has built more than 30 apps that help content progress from pitch (aka screenplay) to playback: ranging from script content acquisition, deal negotiations and vendor management to scheduling, streamlining production workflows, and so on. We treat it as an input for our system.
Part 3: System Strategies and Architecture By: VarunKhaitan With special thanks to my stunning colleagues: Mallika Rao , Esmir Mesic , HugoMarques This blog post is a continuation of Part 2 , where we cleared the ambiguity around title launch observability at Netflix. The request schema for the observability endpoint.
Cloud-native architectures have brought immense complexity along with increased business agility. But with this complexity comes fragility and lack of transparency into system performance and reliability.
A performance engineer is actually a professional performance testing and engineering expert with in-depth knowledge of many load-testing tools like LoadRunner, JMeter, Neoload, Gatling, K6, etc., and must have extensive experience in specialized skills.
In this case, the main stakeholders are: - Title Launch Operators Role: Responsible for setting up the title and its metadata into our systems. In this context, were focused on developing systems that ensure successful title launches, build trust between content creators and our brand, and reduce engineering operational overhead.
Enterprise adoption with self-service: To facilitate enterprise adoption while minimizing tool sprawl and data silos, Dynatrace allows observability teams and platform engineers to implement a self-service model for developers. They can even combine this with data from external sources or add custom code to address bespoke requirements.
What is site reliability engineering? Site reliability engineering (SRE) is the practice of applying software engineering principles to operations and infrastructure processes to help organizations create highly reliable and scalable software systems. Dynatrace news. SRE bridges the gap between Dev and Ops teams.
This article delves into the paradigm shift from traditional to real-time data integration, examines its architectural nuances, and contemplates its profound impact on decision-making and business processes. The new norm is real-time data integration, and it’s transforming the way companies make decisions and conduct their operations.
As cloud-native, distributed architectures proliferate, the need for DevOps technologies and DevOps platform engineers has increased as well. DevOps engineer tools can help ease the pressure as environment complexity grows. ” What does a DevOps platform engineer do? .” Atlassian Jira.
This method of structuring, developing, and operating complex, multi-function software as a collection of smaller independent services is known as microservice architecture. ” it helps to understand the monolithic architectures that preceded them. Understanding monolithic architectures.
This method of structuring, developing, and operating complex, multi-function software as a collection of smaller independent services is known as microservice architecture. ” it helps to understand the monolithic architectures that preceded them. Understanding monolithic architectures.
This article is intended for data scientists, AI researchers, machine learning engineers, and advanced practitioners in the field of artificial intelligence who have a solid grounding in machine learning concepts, natural language processing , and deep learning architectures.
Many organizations are taking a microservices approach to IT architecture. However, in some cases, an organization may be better suited to another architecture approach. Therefore, it’s critical to weigh the advantages of microservices against its potential issues, other architecture approaches, and your unique business needs.
Site reliability engineering (SRE) is the practice of applying software engineering principles to operations and infrastructure processes to help organizations create highly reliable and scalable software systems. Dynatrace news. SRE bridges the gap between Dev and Ops teams. SRE focuses on automation.
In the world of distributed systems, the likelihood of components failing or becoming unresponsive is higher compared to monolithic systems. Therefore, resilience — the ability of a system to handle and recover from failures — becomes critically important in distributed environments.
Stream processing One approach to such a challenging scenario is stream processing, a computing paradigm and software architectural style for data-intensive software systems that emerged to cope with requirements for near real-time processing of massive amounts of data. We designed experimental scenarios inspired by chaos engineering.
As organizations continue to modernize their technology stacks, many turn to Kubernetes , an open source container orchestration system for automating software deployment, scaling, and management. Five of the most common include cluster instability, resource and cost management, security, observability, and stress on engineering teams.
By Alex Hutter , Falguni Jhaveri and Senthil Sayeebaba Over the past few years Content Engineering at Netflix has been transitioning many of its services to use a federated GraphQL platform. In a federated graph architecture, how can we answer such a query given that each entity is served by its own service?
Messaging systems can significantly improve the reliability, performance, and scalability of the communication processes between applications and services. In serverless and microservices architectures, messaging systems are often used to build asynchronous service-to-service communication. Dynatrace news. This is great!
Site reliability engineering (SRE) has become increasingly important to organizations looking to keep up with the rapid pace of digital transformation. Effective site reliability engineering requires enterprise-wide transformation Without a unified understanding of SRE practices, organizational silos can quickly form between departments.
This means a system that is not merely available but is also engineered with extensive redundant measures to continue to work as its users expect. Fault tolerance The ability of a system to continue to be dependable (both available and reliable) in the presence of certain component or subsystem failures.
The nirvana state of system uptime at peak loads is known as “five-nines availability.” In its pursuit, IT teams hover over system performance dashboards hoping their preparations will deliver five nines—or even four nines—availability. How can IT teams deliver system availability under peak loads that will satisfy customers?
By Abhinaya Shetty , Bharath Mummadisetty At Netflix, our Membership and Finance Data Engineering team harnesses diverse data related to plans, pricing, membership life cycle, and revenue to fuel analytics, power various dashboards, and make data-informed decisions. Our audits would detect this and alert the on-call data engineer (DE).
Every image you hover over isnt just a visual placeholder; its a critical data point that fuels our sophisticated personalization engine. It requires a state-of-the-art system that can track and process these impressions while maintaining a detailed history of each profiles exposure.
Following are some of the coolest things weve seen engineers do with Live Debugger. You can verify any system settings that might impact your tests and see them in action. Performance benchmarking Performance benchmarking is one of the unresolved mysteries of software engineering.
A summary of sessions at the first Data Engineering Open Forum at Netflix on April 18th, 2024 The Data Engineering Open Forum at Netflix on April 18th, 2024. At Netflix, we aspire to entertain the world, and our data engineering teams play a crucial role in this mission by enabling data-driven decision-making at scale.
As a PSM system administrator, you’ve relied on AppMon as a preconfigured APM tool for detecting, diagnosing, and repairing problems that impact the operational health of your Windchill application suite. The post It’s time to upgrade the PTC System Monitor (PSM)! Dynatrace news. And even Digital business analytics.
By Ko-Jen Hsiao , Yesu Feng and Sudarshan Lamkhede Motivation Netflixs personalized recommender system is a complex system, boasting a variety of specialized machine learned models each catering to distinct needs including Continue Watching and Todays Top Picks for You. Refer to our recent overview for more details).
In this blog post, we explain what Greenplum is, and break down the Greenplum architecture, advantages, major use cases, and how to get started. It’s architecture was specially designed to manage large-scale data warehouses and business intelligence workloads by giving you the ability to spread your data out across a multitude of servers.
Timestone: Netflix’s High-Throughput, Low-Latency Priority Queueing System with Built-in Support for Non-Parallelizable Workloads by Kostas Christidis Introduction Timestone is a high-throughput, low-latency priority queueing system we built in-house to support the needs of Cosmos , our media encoding platform. Over the past 2.5
The reality of the startup is that engineering teams are often at a crossroads when it comes to choosing the foundational architecture for their software applications. The allure of a microservice architecture is understandable in today's tech state of affairs, where scalability, flexibility, and independence are highly valued.
False positives are instances where the system incorrectly identifies a regular event as an anomaly, leading to unnecessary investigative efforts and operational delays. This article delves into a specialized approach for anomaly detection that makes extensive use of a rule-based engine.
Specifically, we will dive into the architecture that powers search capabilities for studio applications at Netflix. We implemented a batch processing system for users to submit their requests and wait for the system to generate the output. Dawn Chenette , Design Lead This approach had several benefits for product engineering.
Editor's Note: The following is an article written for and published in DZone's 2024 Trend Report, The Modern DevOps Lifecycle: Shifting CI/CD and Application Architectures. By integrating observability tools in CI/CD pipelines, organizations can increase deployment frequency, minimize risks, and build highly available systems.
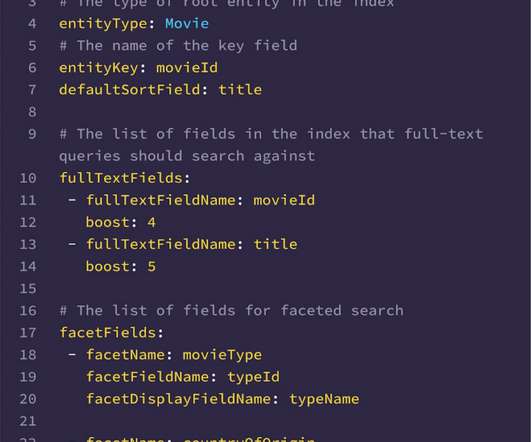
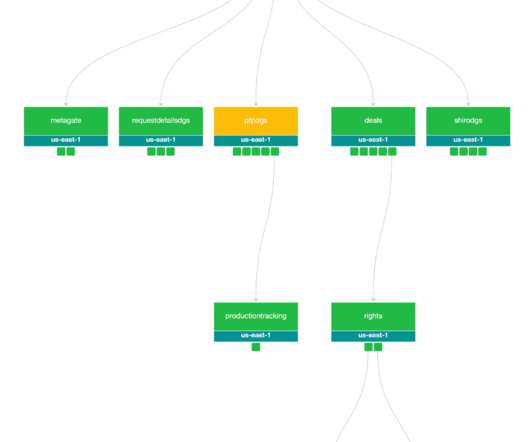
By Alex Hutter , Falguni Jhaveri , and Senthil Sayeebaba In a previous post , we described the indexing architecture of Studio Search and how we scaled the architecture by building a config-driven self-service platform that allowed teams in Content Engineering to spin up search indices easily. Below are a couple of examples.
Scaling RabbitMQ ensures your system can handle growing traffic and maintain high performance. Key Takeaways RabbitMQ improves scalability and fault tolerance in distributed systems by decoupling applications, enabling reliable message exchanges.
Cloud-native application development in AWS often requires complex, layered architecture with synchronous and asynchronous interactions between multiple components, e.g., API Gateway, Microservices, Serverless Functions, and system of record integration.
Our Journey so Far Over the past year, we’ve implemented the core infrastructure pieces necessary for a federated GraphQL architecture as described in our previous post: Studio Edge Architecture The first Domain Graph Service (DGS) on the platform was the former GraphQL monolith that we discussed in our first post (Studio API).
For software engineering teams, this demand means not only delivering new features faster but ensuring quality, performance, and scalability too. One way to apply improvements is transforming the way application performance engineering and testing is done. Here is the definition of this model: ?. Try it today using Keptn .
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content