This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
After years of working in the intricate world of softwareengineering, I learned that the most beautiful solutions are often those unseen: backends that hum along, scaling with grace and requiring very little attention. Developers could understand and manage the entire systems intricacies.
Stream processing One approach to such a challenging scenario is stream processing, a computing paradigm and softwarearchitectural style for data-intensive software systems that emerged to cope with requirements for near real-time processing of massive amounts of data. Recovery time of the latency p90.
Much like how an electrical circuit breaker prevents an overload by stopping the flow of electricity when excessive current is detected, the Circuit Breaker pattern in softwareengineering stops the flow of requests to a service when the number of failures exceeds a predefined threshold.
What is site reliability engineering? Site reliability engineering (SRE) is the practice of applying softwareengineering principles to operations and infrastructure processes to help organizations create highly reliable and scalable software systems. Dynatrace news. SRE focuses on automation.
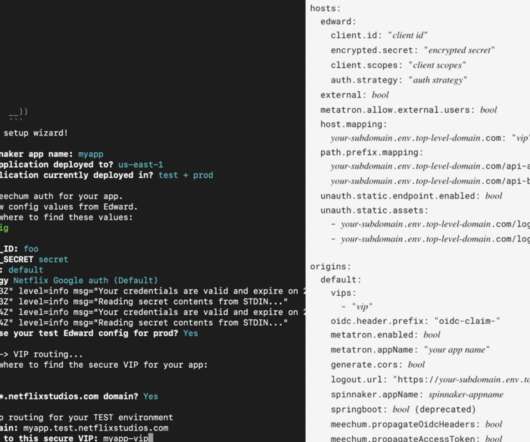
Part 3: System Strategies and Architecture By: VarunKhaitan With special thanks to my stunning colleagues: Mallika Rao , Esmir Mesic , HugoMarques This blog post is a continuation of Part 2 , where we cleared the ambiguity around title launch observability at Netflix. The request schema for the observability endpoint.
As organizations look to expand DevOps maturity, improve operational efficiency, and increase developer velocity, they are embracing platform engineering as a key driver. Platform engineering: Build for self-service Self-service deployment is a key attribute of platform engineering. “It makes them more productive.
Site reliability engineering (SRE) is the practice of applying softwareengineering principles to operations and infrastructure processes to help organizations create highly reliable and scalable software systems. ” According to Google, “SRE is what you get when you treat operations as a software problem.”
A summary of sessions at the first Data Engineering Open Forum at Netflix on April 18th, 2024 The Data Engineering Open Forum at Netflix on April 18th, 2024. At Netflix, we aspire to entertain the world, and our data engineering teams play a crucial role in this mission by enabling data-driven decision-making at scale.
In recent years, observability has re-emerged as a critical aspect of DevOps and softwareengineering in general, driven by the growing complexity and scale of modern, cloud-native applications.
Following are some of the coolest things weve seen engineers do with Live Debugger. Performance benchmarking Performance benchmarking is one of the unresolved mysteries of softwareengineering. White box testing The nicest thing about deploying UI changes to production is that you can immediately see the changes in action.
Site reliability engineering (SRE) has become increasingly important to organizations looking to keep up with the rapid pace of digital transformation. Effective site reliability engineering requires enterprise-wide transformation Without a unified understanding of SRE practices, organizational silos can quickly form between departments.
When it comes to platform engineering, not only does observability play a vital role in the success of organizations’ transformation journeys—it’s key to successful platform engineering initiatives. The various presenters in this session aligned platform engineering use cases with the software development lifecycle.
For softwareengineering teams, this demand means not only delivering new features faster but ensuring quality, performance, and scalability too. One way to apply improvements is transforming the way application performance engineering and testing is done. Here is the definition of this model: ?. Try it today using Keptn .
There are a few qualities that differentiate average from high performing softwareengineering organisations. I believe that attitude towards the design of code and architecture is one of them. In Accelerate , Nicole Forsgren shows a link between well-designed, loosely-coupled architecture and more frequent software delivery.
The fact is, Reliability and Resiliency must be rooted in the architecture of a distributed system. The email walked through how our Dynatrace self-monitoring notified users of the outage but automatically remediated the problem thanks to our platform’s architecture. Let me start with the end-user impact.
Growth Engineering at Netflix?—?Automated In the Growth Engineering team, we refer to this as the top of the signup funnel. For more background on the signup funnel and Growth Engineering’s role in the signup funnel, please read our initial post on the topic: Growth Engineering at Netflix? Growth Engineering at Netflix?—?Automated
Site reliability engineering (SRE) continues to gain popularity as organizations embrace hybrid cloud strategies and IT automation at scale. By applying softwareengineering principles to operations and infrastructure practices, SRE enables organizations to streamline and automate IT processes. Dynatrace news.
The Growth Engineering team is responsible for executing growth initiatives that help us anticipate and adapt to this change. For more background on Growth Engineering and the signup funnel, please have a look at our previous blog post that covers the basics. We need to be constantly adapting and innovating as a result of this change.
Causal AI—which brings AI-enabled actionable insights to IT operations—and a data lakehouse, such as Dynatrace Grail , can help break down silos among ITOps, DevSecOps, site reliability engineering, and business analytics teams. Logs are automatically produced and time-stamped documentation of events relevant to cloud architectures.
Monitoring and logging tools that once worked well with earlier IT architectures no longer provide sufficient context and integration to understand the state of complex systems or diagnose and correct security issues. Manually managing and securing multi-cloud environments is no longer practical. Automation versus orchestration.
Data Engineers of Netflix?—?Interview Interview with Samuel Setegne Samuel Setegne This post is part of our “Data Engineers of Netflix” interview series, where our very own data engineers talk about their journeys to Data Engineering @ Netflix. What drew you to Netflix?
Machine Learning Engineer at Amazon and has led several machine-learning initiatives across the Amazon ecosystem. Architecture. FUN FACT : In this talk , Rodrigo Schmidt, director of engineering at Instagram talks about the different challenges they have faced in scaling the data infrastructure at Instagram. High Level Design.
In our quest for greater scalability, resilience, and flexibility within the digital infrastructure of our organization, there has been a strategic pivot away from traditional monolithic application architectures towards embracing modern softwareengineering practices such as microservices architecture coupled with cloud-native applications.
Fei Xu (SoftwareEngineer at PingCAP). Authors: Ruoxi Sun (Tech Lead of Analytical Computing Team at PingCAP). TiDB is a Hybrid Transaction/Analytical Processing (HTAP) database that can efficiently process analytical queries.
Now, imagine yourself in the role of a softwareengineer responsible for a micro-service which publishes data consumed by few critical customer facing services (e.g. You are about to make structural changes to the data and want to know who and what downstream to your service will be impacted.
Supporting developers through those checklists for edge cases, and then validating that each team’s choices resulted in an architecture with all the desired security properties, was similarly not scalable for our security engineers. Netflix engineers talk a lot about the concept of a “ Paved Road ”.
As a SoftwareEngineer, the mind is trained to seek optimizations in every aspect of development and ooze out every bit of available CPU Resource to deliver a performing application. This begins not only in designing the algorithm or coming out with efficient and robust architecture but right onto the choice of programming language.
Incident management with clearly defined responsibilities Site Reliability Engineers (SRE) are challenged not only to detect problems and identify the root cause quickly but also to remediate problems immediately. Any softwareengineer can search for monitored entities that relate to specific deployments and their respective teams.
Site reliability engineering (SRE) has recently become a critical discipline in recent years as the world has shifted in favor of web-based interactions. This shift is leading more organizations to hire site reliability engineers to guarantee the reliability and resiliency of their services. Mobile retail e-commerce spending in the U.
Application security is a softwareengineering term that refers to several different types of security practices designed to ensure applications do not contain vulnerabilities that could allow illicit access to sensitive data, unauthorized code modification, or resource hijacking. Dynatrace news.
When it comes to site reliability engineering (SRE) initiatives adopting DevOps practices, developers and operations teams frequently find themselves at odds with one another. Dynatrace news. Developers want to write high-quality code and deploy it quickly. Operations teams want to make sure the system doesn’t break.
Serverless architectures help developers innovate more efficiently and effectively by removing the burden of managing underlying infrastructure. Dynatrace is happy to announce its enhanced AWS Lambda extension, expanding its support for Amazon Web Services (AWS) Lambda and serverless architectures. The Dynatrace AI engine, Davis,?automatically
As software development grows more complex, managing components using an automated onboarding process becomes increasingly important. This is especially crucial in microservice architectures, where the number of components can be overwhelming.
In this article, San Francisco-based softwareengineer Yijun Liu reflects on his experiences working with … The post Re-Architecting Cash and Digital Wallet Payments for India with Uber Engineering appeared first on Uber Engineering Blog.
2018 marks the fourth year of O’Reilly’s SoftwareArchitecture Conference , a softwareengineering event focused on providing hands-on training experiences for technologists at all levels of an organization—from experienced developers up through CTOs. Building evolutionary softwarearchitecture.
Composite’ AI, platform engineering, AI data analysis through custom apps This focus on data reliability and data quality also highlights the need for organizations to bring a “ composite AI ” approach to IT operations, security, and DevOps. To learn more about platform engineering, explore the following resources.
Meson was based on a single leader architecture with high availability. Data scientists, engineers, non-engineers, and even content producers all run their data pipelines to get the necessary insights. Figure 1 shows the high-level architecture. With the high growth of workflows in the past few years?
Plus, the architecture of the Edge tier was evolving to a PaaS (platform as a service) model, and we had some tough decisions to make about how, and where, to handle identity token handling. The system architecture now takes the form of: Notice that tokens never traverse past the Edge gateway / EAS boundary. We are serving over 2.5
This is both frustrating for companies that would prefer making ML an ordinary, fuss-free value-generating function like softwareengineering, as well as exciting for vendors who see the opportunity to create buzz around a new category of enterprise software. SoftwareArchitecture. This approach is not novel.
Architecture modernization initiatives are strategic efforts involving many teams, usually for many months or years. An AMET is an architecture Enabling Team that helps to coordinate and upskill all teams and stakeholders involved in a modernization initiative. They need a more loosely coupled architecture and empowered teams.
mainly because of mundane reasons related to softwareengineering. They know that feature engineering is critical for many models, so they want to stay in control of model inputs and feature engineering logic. Instead, we heard stories about projects where getting the first version to production took surprisingly long?—?mainly
Our very first mobile app is called Prodicle and was built for Android & iOS using the same reactive architecture in both platforms, which allowed us to build 2 apps from scratch in 3 months with 4 softwareengineers. Composable UIs contribute to fast engineering velocity and produce less side effect bugs.
By Drew Koszewnik This is the story about how the Content Setup Engineering team used Hollow, a Netflix OSS technology, to re-architect and simplify an essential component in our content pipeline?—?delivering A reduction in the time the Content Setup Engineering team spends on performance-related issues.
It warns softwareengineers of bugs in newly-implemented code and regressions in existing code, before it is merged. This ensures increased software reliability. It also … The post Handling Flaky Unit Tests in Java appeared first on Uber Engineering Blog.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content