This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
After years of working in the intricate world of software engineering, I learned that the most beautiful solutions are often those unseen: backends that hum along, scaling with grace and requiring very little attention. Developers could understand and manage the entire systems intricacies.
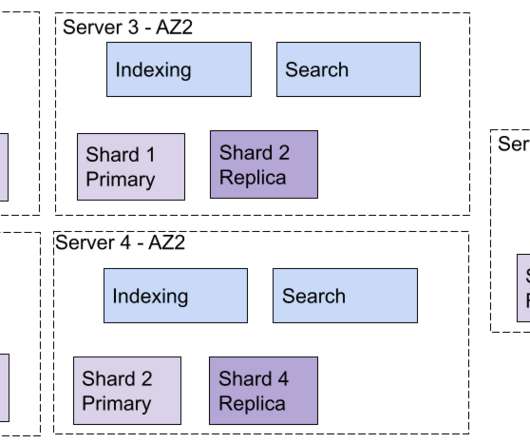
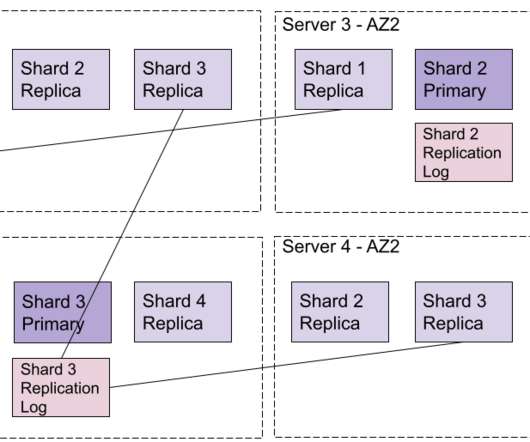
What would a totally new search enginearchitecture look like? Search engines, and more generally, information retrieval systems, play a central role in almost all of today’s technical stacks. After more than 30 years of evolution since TREC, search engines continue to grow and evolve, leading to new challenges.
With the evolution of modern applications serving increasing needs for real-time data processing and retrieval, scalability does, too. One such open-source, distributed search and analytics engine is Elasticsearch, which is very efficient at handling data in large sets and high-velocity queries.
The scalability, agility, and continuous delivery offered by microservices architecture make it a popular option for businesses today. Nevertheless, microservices architectures are not invulnerable to disruptions.
Scalable Annotation Service — Marken by Varun Sekhri , Meenakshi Jindal Introduction At Netflix, we have hundreds of micro services each with its own data models or entities. Marken architecture Above picture represents the block diagram of the architecture for our service. zookeeper service, internationalization service etc.
Part 3: System Strategies and Architecture By: VarunKhaitan With special thanks to my stunning colleagues: Mallika Rao , Esmir Mesic , HugoMarques This blog post is a continuation of Part 2 , where we cleared the ambiguity around title launch observability at Netflix. The request schema for the observability endpoint.
What would a totally new search enginearchitecture look like? Search engines need to support fast scaling for both Read and Write operations. The architecture needs to handle efficiently all these situations as the scaling of Read and Write operations varies over time in most use cases. Here's Part 1.
This thoughtful approach doesnt just address immediate hurdles; it builds the resilience and scalability needed for the future. Challenge: Dont understand the cascading effects of their setup on these perceived black box personalization systems - Personalization System Engineers Role: Develop and operate the personalization systems.
2020 cemented the reality that modern software development practices require rapid, scalable delivery in response to unpredictable conditions. This method of structuring, developing, and operating complex, multi-function software as a collection of smaller independent services is known as microservice architecture. Dynatrace news.
2020 cemented the reality that modern software development practices require rapid, scalable delivery in response to unpredictable conditions. This method of structuring, developing, and operating complex, multi-function software as a collection of smaller independent services is known as microservice architecture. Dynatrace news.
As cloud-native, distributed architectures proliferate, the need for DevOps technologies and DevOps platform engineers has increased as well. DevOps engineer tools can help ease the pressure as environment complexity grows. ” What does a DevOps platform engineer do? .”
What is site reliability engineering? Site reliability engineering (SRE) is the practice of applying software engineering principles to operations and infrastructure processes to help organizations create highly reliable and scalable software systems. Dynatrace news. SRE focuses on automation.
Many organizations are taking a microservices approach to IT architecture. However, in some cases, an organization may be better suited to another architecture approach. Therefore, it’s critical to weigh the advantages of microservices against its potential issues, other architecture approaches, and your unique business needs.
Site reliability engineering (SRE) is the practice of applying software engineering principles to operations and infrastructure processes to help organizations create highly reliable and scalable software systems. Organizations can then integrate these skilled engineers at key points in the DevOps life cycle.
Stream processing One approach to such a challenging scenario is stream processing, a computing paradigm and software architectural style for data-intensive software systems that emerged to cope with requirements for near real-time processing of massive amounts of data. We designed experimental scenarios inspired by chaos engineering.
A summary of sessions at the first Data Engineering Open Forum at Netflix on April 18th, 2024 The Data Engineering Open Forum at Netflix on April 18th, 2024. At Netflix, we aspire to entertain the world, and our data engineering teams play a crucial role in this mission by enabling data-driven decision-making at scale.
The Growth Engineering team is responsible for executing growth initiatives that help us anticipate and adapt to this change. For more background on Growth Engineering and the signup funnel, please have a look at our previous blog post that covers the basics. We need to be constantly adapting and innovating as a result of this change.
The reality of the startup is that engineering teams are often at a crossroads when it comes to choosing the foundational architecture for their software applications. The allure of a microservice architecture is understandable in today's tech state of affairs, where scalability, flexibility, and independence are highly valued.
To get a better understanding of AWS serverless, we’ll first explore the basics of serverless architectures, review AWS serverless offerings, and explore common use cases. Serverless architecture: A primer. Serverless architecture shifts application hosting functions away from local servers onto those managed by providers.
In this blog post, we explain what Greenplum is, and break down the Greenplum architecture, advantages, major use cases, and how to get started. It’s architecture was specially designed to manage large-scale data warehouses and business intelligence workloads by giving you the ability to spread your data out across a multitude of servers.
Key Takeaways RabbitMQ improves scalability and fault tolerance in distributed systems by decoupling applications, enabling reliable message exchanges. This decoupling is crucial in modern architectures where scalability and fault tolerance are paramount.
Editor's Note: The following is an article written for and published in DZone's 2024 Trend Report, The Modern DevOps Lifecycle: Shifting CI/CD and Application Architectures. Complementing these practices is site reliability engineering (SRE), a discipline ensuring system reliability, performance, and scalability.
This scenario underscored the need for a new recommender system architecture where member preference learning is centralized, enhancing accessibility and utility across different models. Furthermore, it was difficult to transfer innovations from one model to another, given that most are independently trained despite using common data sources.
Gergely Orosz, an Engineering Manager on the Payments Experience Platform at Uber, in a tweet signaled a change in architectural direction: Think what you want about Uber the company, but from a software perspective Uber has been a good citizen.
It's HighScalability time: 10 years of AWS architecture increasing simplicity or increasing complexity? Don't miss all that the Internet has to say on Scalability, click below and become eventually consistent with all scalability knowledge (which means this post has many more items to read so please keep on reading).
For software engineering teams, this demand means not only delivering new features faster but ensuring quality, performance, and scalability too. One way to apply improvements is transforming the way application performance engineering and testing is done. Here is the definition of this model: ?. Try it today using Keptn .
To this end, we developed a Rapid Event Notification System (RENO) to support use cases that require server initiated communication with devices in a scalable and extensible manner. Personalized Experience Refresh Netflix Recommendation engine continuously refreshes recommendations for every member.
Netflix’s engineering culture is predicated on Freedom & Responsibility, the idea that everyone (and every team) at Netflix is entrusted with a core responsibility and they are free to operate with freedom to satisfy their mission. All these micro-services are currently operated in AWS cloud infrastructure.
Performances testing helps establish the scalability, stability, and speed of the software application. Performance testing is mainly a subset of Performance engineering and is also referred to as ' Perf Tests.' Confirming scalability, dependability, stability, and speed of the app is crucial.
Machine Learning Engineer at Amazon and has led several machine-learning initiatives across the Amazon ecosystem. Architecture. FUN FACT : In this talk , Rodrigo Schmidt, director of engineering at Instagram talks about the different challenges they have faced in scaling the data infrastructure at Instagram. High Level Design.
We’re delighted to share that IBM and Dynatrace have joined forces to bring the Dynatrace Operator, along with the comprehensive capabilities of the Dynatrace platform, to Red Hat OpenShift on the IBM Power architecture (ppc64le).
This means a system that is not merely available but is also engineered with extensive redundant measures to continue to work as its users expect. reliability situations, where continuity of service is essential, with redundant elements continuously in-service, such as with airplane engines. This ensures reliability.
Grail architectural basics. The aforementioned principles have, of course, a major impact on the overall architecture. A data lakehouse addresses these limitations and introduces an entirely new architectural design. From the beginning, Grail was built to be fast and scalable to manage massive volumes of data.
Flow Exporter The Flow Exporter is a sidecar that uses eBPF tracepoints to capture TCP flows at near real time on instances that power the Netflix microservices architecture. After several iterations of the architecture and some tuning, the solution has proven to be able to scale. What is BPF?
Engineers want their alerting system to be realtime, reliable, and actionable. A few years ago, we were paged by our SRE team due to our Metrics Alerting System falling behind — critical application health alerts reached engineers 45 minutes late! It opens doors to support more exciting use-cases. OK, Results?
The goal was to develop a custom solution that enables DevOps and engineering teams to analyze and improve pipeline performance issues and alert on health metrics across CI/CD platforms. Faced with these requirements, Omnilogy carefully evaluated the following two options for implementing a solution to the pipeline observability challenge.
Our Journey so Far Over the past year, we’ve implemented the core infrastructure pieces necessary for a federated GraphQL architecture as described in our previous post: Studio Edge Architecture The first Domain Graph Service (DGS) on the platform was the former GraphQL monolith that we discussed in our first post (Studio API).
Causal AI—which brings AI-enabled actionable insights to IT operations—and a data lakehouse, such as Dynatrace Grail , can help break down silos among ITOps, DevSecOps, site reliability engineering, and business analytics teams. Logs are automatically produced and time-stamped documentation of events relevant to cloud architectures.
Now, imagine yourself in the role of a software engineer responsible for a micro-service which publishes data consumed by few critical customer facing services (e.g. You are about to make structural changes to the data and want to know who and what downstream to your service will be impacted.
Most of the time is taken by quality or release engineers looking at test results, comparing them with previous builds or walking through a checklist of items that accumulated over the years in order to harden their release acceptance process. Beyond basic metrics: Detecting Architectural Regressions.
Many organizations today rely on cloud-native applications for their scalability and agility, among other benefits. Serverless benefits include the following: Dynamic scalability. Serverless architecture makes it possible to host code anywhere, rather than relying on an origin server. Architectural complexity.
This guest blog is authored by Raphael Pionke , DevOps Engineer at T-Systems MMS. To do so we have successfully established AI-based White box load and resiliency testing with JMeter and Dynatrace, helping identify and resolve major performance and scalability problems in recent projects before deploying to production. Dynatrace news.
The Dynatrace Software Intelligence Platform accelerates cloud operations, helping users achieve service-level objectives (SLOs) with automated intelligence and unmatched scalability. Understand and optimize your architecture. Built for enterprise scalability. Optimize timing hotspots. Simplify error analytics.
Specifically, we will dive into the architecture that powers search capabilities for studio applications at Netflix. Dawn Chenette , Design Lead This approach had several benefits for product engineering. At the same time we experienced growing engineering pains that limited our ability to scale. Incredible!”
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content