This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Enhancing data separation by partitioning each customer’s data on the storage level and encrypting it with a unique encryption key adds an additional layer of protection against unauthorized data access. A unique encryption key is applied to each tenant’s storage and automatically rotated every 365 days.
As an executive, I am always seeking simplicity and efficiency to make sure the architecture of the business is as streamlined as possible. Here are five strategies executives can pursue to reduce tool sprawl, lower costs, and increase operational efficiency. No delays and overhead of reindexing and rehydration.
Handling multimodal data spanning text, images, videos, and sensor inputs requires resilient architecture to manage the diversity of formats and scale.
Without observability, the benefits of ARM are lost Over the last decade and a half, a new wave of computer architecture has overtaken the world. ARM architecture, based on a processor type optimized for cloud and hyperscale computing, has become the most prevalent on the planet, with billions of ARM devices currently in use.
In today's data-driven world, organizations need efficient and scalable data pipelines to process and analyze large volumes of data. Medallion Architecture provides a framework for organizing data processing workflows into different zones, enabling optimized batch and stream processing.
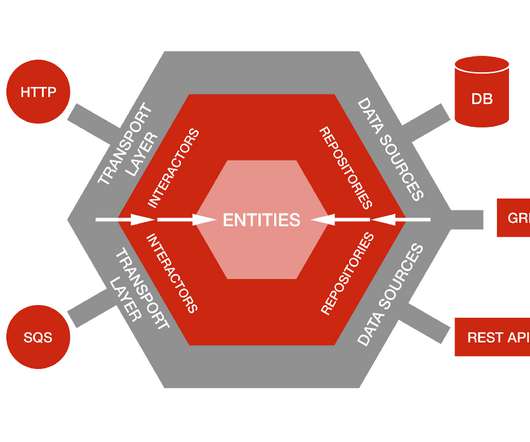
by Damir Svrtan and Sergii Makagon As the production of Netflix Originals grows each year, so does our need to build apps that enable efficiency throughout the entire creative process. We decided to build our app based on principles behind Hexagonal Architecture and Uncle Bob’s Clean Architecture.
More technology, more complexity The benefits of cloud-native architecture for IT systems come with the complexity of maintaining real-time visibility into security compliance and risk posture. million to $5 million annually in increased developer efficiency with our vulnerability and exposure offering alone.
Organizations are now looking into solutions that unify security capabilities to protect their environments efficiently. Incident response: Providing capabilities for incident response, including remediation suggestions and integration with DevOps workflows, to help resolve security incidents quickly and efficiently.
This article outlines the key differences in architecture, performance, and use cases to help determine the best fit for your workload. RabbitMQ follows a message broker model with advanced routing, while Kafkas event streaming architecture uses partitioned logs for distributed processing. What is RabbitMQ? What is Apache Kafka?
They now use modern observability to monitor expanding cloud environments in order to operate more efficiently, innovate faster and more securely, and to deliver consistently better business results. Further, automation has become a core strategy as organizations migrate to and operate in the cloud.
Architecture Overview The first pivotal step in managing impressions begins with the creation of a Source-of-Truth (SOT) dataset. The enriched data is seamlessly accessible for both real-time applications via Kafka and historical analysis through storage in an Apache Iceberg table.
At this scale, we can gain a significant amount of performance and cost benefits by optimizing the storage layout (records, objects, partitions) as the data lands into our warehouse. We built AutoOptimize to efficiently and transparently optimize the data and metadata storage layout while maximizing their cost and performance benefits.
Part 3: System Strategies and Architecture By: VarunKhaitan With special thanks to my stunning colleagues: Mallika Rao , Esmir Mesic , HugoMarques This blog post is a continuation of Part 2 , where we cleared the ambiguity around title launch observability at Netflix. The request schema for the observability endpoint.
This demand for rapid innovation is propelling organizations to adopt agile methodologies and DevOps principles to deliver software more efficiently and securely. And how do DevOps monitoring tools help teams achieve DevOps efficiency? Lost efficiency. 54% reported deploying updates every two hours or less.
In this blog post, we explain what Greenplum is, and break down the Greenplum architecture, advantages, major use cases, and how to get started. It’s architecture was specially designed to manage large-scale data warehouses and business intelligence workloads by giving you the ability to spread your data out across a multitude of servers.
After selecting a mode, users can interact with APIs without needing to worry about the underlying storage mechanisms and counting methods. Let’s examine some of the drawbacks of this approach: Lack of Idempotency : There is no idempotency key baked into the storage data-model preventing users from safely retrying requests.
To get a better understanding of AWS serverless, we’ll first explore the basics of serverless architectures, review AWS serverless offerings, and explore common use cases. Serverless architecture: A primer. Serverless architecture shifts application hosting functions away from local servers onto those managed by providers.
Grail architectural basics. The aforementioned principles have, of course, a major impact on the overall architecture. A data lakehouse addresses these limitations and introduces an entirely new architectural design. This decoupling ensures the openness of data and storage formats, while also preserving data in context.
Thanks to its structured and binary format, Journald is quick and efficient. The Grail architecture ensures scalability, making log data accessible for detailed analysis regardless of volume. Dynatrace Grail lets you focus on extracting insights rather than managing complex schemas or index and storage concepts.
This guide will cover how to distribute workloads across multiple nodes, set up efficient clustering, and implement robust load-balancing techniques. This decoupling is crucial in modern architectures where scalability and fault tolerance are paramount.
In this post, we dive deep into how Netflix’s KV abstraction works, the architectural principles guiding its design, the challenges we faced in scaling diverse use cases, and the technical innovations that have allowed us to achieve the performance and reliability required by Netflix’s global operations.
While data lakes and data warehousing architectures are commonly used modes for storing and analyzing data, a data lakehouse is an efficient third way to store and analyze data that unifies the two architectures while preserving the benefits of both. What is a data lakehouse? How does a data lakehouse work? Data management.
A distributed storage system is foundational in today’s data-driven landscape, ensuring data spread over multiple servers is reliable, accessible, and manageable. Understanding distributed storage is imperative as data volumes and the need for robust storage solutions rise.
Several pain points have made it difficult for organizations to manage their data efficiently and create actual value. Modern IT environments — whether multicloud, on-premises, or hybrid-cloud architectures — generate exponentially increasing data volumes. This approach is cumbersome and challenging to operate efficiently at scale.
Table 1: Movie and File Size Examples Initial Architecture A simplified view of our initial cloud video processing pipeline is illustrated in the following diagram. Figure 1: A Simplified Video Processing Pipeline With this architecture, chunk encoding is very efficient and processed in distributed cloud computing instances.
In short, over the last several months, we’ve completely rebuilt the architecture of the OneAgent installer for Windows. Smaller network and Dynatrace cluster storage footprint. The post Rebuilt OneAgent installer for Windows provides more efficient installation appeared first on Dynatrace blog.
Further, these resources support countless Kubernetes clusters and Java-based architectures. In most data storage models, indexing engines enable faster access to query logs. But indexing requires schema management and additional storage to be effective, which adds cost and overhead. Cost-effective architecture.
Enhanced data security, better data integrity, and efficient access to information. Despite initial investment costs, DBMS presents long-term savings and improved efficiency through automated processes, efficient query optimizations, and scalability, contributing to enhanced decision-making and end-user productivity.
Organizations continue to turn to multicloud architecture to deliver better, more secure software faster. But IT teams need to embrace IT automation and new data storage models to benefit from modern clouds. Moreover, IT pros say that cloud architecture and data repositories thwart achieving better data insight.
With more automated approaches to log monitoring and log analysis, however, organizations can gain visibility into their applications and infrastructure efficiently and with greater precision—even as cloud environments grow. Logs are automatically produced and time-stamped documentation of events relevant to cloud architectures.
Kubernetes adds to the complexity of technology stacks Alongside the challenges of managing multicloud environments, IT and security teams struggle to maintain visibility into cloud-native architectures as Kubernetes continues to become the platform of choice for modern applications.
In previous blog posts, we introduced the Key-Value Data Abstraction Layer and the Data Gateway Platform , both of which are integral to Netflix’s data architecture. Instead, we focus on addressing the challenge of storing and accessing extremely high-throughput, immutable temporal event data in a low-latency and cost-efficient manner.
Before we dive into the technical implementation, let me explain the visual concept of this “Global Status Page”: Another requirement for this status page was that it has to be lightweight, with no data storage at all. Getting the problem status of all environments has to be efficient. Lightweight architecture. js framework.
IT infrastructure is the heart of your digital business and connects every area – physical and virtual servers, storage, databases, networks, cloud services. If you don’t have insight into the software and services that operate your business, you can’t efficiently run your business. Minimizes downtime and increases efficiency.
The rise of cloud-native microservice architectures further exacerbates this change. Dynatrace has developed the purpose-built data lakehouse, Grail , eliminating the need for separate management of indexes and storage. All data is readily accessible without storage tiers, such as costly solid-state drives (SSDs).
As a result, organizations are implementing security analytics to manage risk and improve DevSecOps efficiency. Security analytics must also contend with the multicomponent architecture of modern IT infrastructure. Dehydrated data has been compressed or otherwise altered for storage in a data warehouse. Read now!
RISELabs , those wonderfully innovative folks over at Berkeley, have uplifted their Anna datatabase —a shared-nothing, thread-per-core architecture to achieve lightning-fast speeds by avoiding all coordination mechanisms—to become cloud-aware. What's changed ?
Cloud storage monitoring. Teams can keep track of storage resources and processes that are provisioned to virtual machines, services, databases, and applications. Multicloud architectures, on the other hand, blend services from two or more private or public clouds — or from a combination of public, private, and edge clouds.
It starts with implementing data governance practices, which set standards and policies for data use and management in areas such as quality, security, compliance, storage, stewardship, and integration. Modern, cloud-native architectures have many moving parts, and identifying them all is a daunting task with human effort alone.
Building an elastic query engine on disaggregated storage , Vuppalapati, NSDI’20. For such workloads, shared-nothing architectures beget high cost, inflexibility, poor performance, and inefficiency, which hurts production applications and cluster deployments. joins) during query processing. Disaggregation (or not).
All this is easier said than done because: Kubernetes-based dynamic architecture is becoming the norm. This allows you to create flexible and powerful log storage configurations on any level by utilizing the unique autodiscovery capabilities of Dynatrace OneAgent or a custom setup. Try it out yourself.
As a result, organizations need software to work perfectly to create customer experiences, deliver innovation, and generate operational efficiency. Traditionally, though, to gain true business insight, organizations had to make tradeoffs between accessing quality, real-time data and factors such as data storage costs.
This is a set of best practices and guidelines that help you design and operate reliable, secure, efficient, cost-effective, and sustainable systems in the cloud. The framework comprises six pillars: Operational Excellence, Security, Reliability, Performance Efficiency, Cost Optimization, and Sustainability.
At Netflix, we also heavily embrace a microservice architecture that emphasizes separation of concerns. Therefore, we must efficiently move data from the data warehouse to a global, low-latency and highly-reliable key-value store. Figure 1 shows how we use Bulldozer to move data at Netflix. Moving data with Bulldozer at Netflix.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content