This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
With the evolution of modern applications serving increasing needs for real-time data processing and retrieval, scalability does, too. One such open-source, distributed search and analytics engine is Elasticsearch, which is very efficient at handling data in large sets and high-velocity queries.
Handling multimodal data spanning text, images, videos, and sensor inputs requires resilient architecture to manage the diversity of formats and scale.
When you are preparing your application for release, an efficient initial strategy is to integrate a single payment service. That’s why it is important to have a scalable infrastructure that will allow you to accommodate those needs — especially nowadays, when integrating with payment services has become more accessible than ever.
Without observability, the benefits of ARM are lost Over the last decade and a half, a new wave of computer architecture has overtaken the world. ARM architecture, based on a processor type optimized for cloud and hyperscale computing, has become the most prevalent on the planet, with billions of ARM devices currently in use.
These innovations promise to streamline operations, boost efficiency, and offer deeper insights for enterprises using AWS services. This year’s AWS re:Invent will showcase a suite of new AWS and Dynatrace integrations designed to enhance cloud performance, security, and automation.
In today's data-driven world, organizations need efficient and scalable data pipelines to process and analyze large volumes of data. Medallion Architecture provides a framework for organizing data processing workflows into different zones, enabling optimized batch and stream processing.
Protect data in multi-tenant architectures To bring you the most value by unifying observability and security in one analytics and automation platform powered by AI, Dynatrace SaaS leverages a multitenancy architecture, enabling efficient and scalable data ingestion, querying, and processing on shared infrastructure.
Grafana Loki is a horizontally scalable, highly available log aggregation system. It is designed for simplicity and cost-efficiency. Created by Grafana Labs in 2018, Loki has rapidly emerged as a compelling alternative to traditional logging systems, particularly for cloud-native and Kubernetes environments.
Microservices architecture has revolutionized modern software development, offering unparalleled agility, scalability , and maintainability. However, effectively implementing microservices necessitates a deep understanding of best practices to harness their full potential while avoiding common pitfalls.
In the world of cloud computing and event-driven applications, efficiency and flexibility are absolute necessities. A proper architecture ensures that there are no bottlenecks in the movement of messages. A smooth flow of messages in an event-driven application is the key to its performance and efficiency.
As display manufacturing continues to evolve, the demand for scalable software solutions to support automation has become more critical than ever. Scalable software architectures are the backbone of efficient and flexible production lines, enabling manufacturers to meet the increasing demands for innovative display technologies.
This article outlines the key differences in architecture, performance, and use cases to help determine the best fit for your workload. RabbitMQ follows a message broker model with advanced routing, while Kafkas event streaming architecture uses partitioned logs for distributed processing. What is RabbitMQ?
Serverless architecture is a way of building and running applications without the need to manage infrastructure. This shift brings forth several benefits: Cost-efficiency: With serverless, you only pay for what you use. Scalability: Serverless services automatically scale with the application's needs.
As organizations increasingly migrate their applications to the cloud, efficient and scalable load balancing becomes pivotal for ensuring optimal performance and high availability. Load balancing is a critical component in cloud architectures for various reasons.
A messaging system serves as a backbone, allowing information transmission between different services or modules in a distributed architecture. However, maintaining scalability and fault tolerance in this system is a difficult but necessary task.
To create a CPU core that can execute a large number of instructions in parallel, it is necessary to improve both the architecturewhich includes the overall CPU design and the instruction set architecture (ISA) designand the microarchitecture, which refers to the hardware design that optimizes instruction execution.
This scenario underscored the need for a new recommender system architecture where member preference learning is centralized, enhancing accessibility and utility across different models. At inference time, when multi-step decoding is needed, we can deploy KV caching to efficiently reuse past computations and maintain lowlatency.
What would a totally new search engine architecture look like? The architecture needs to handle efficiently all these situations as the scaling of Read and Write operations varies over time in most use cases. Who better than Julien Lemoine , Co-founder & CTO of Algolia , to describe what the future of search will look like.
They now use modern observability to monitor expanding cloud environments in order to operate more efficiently, innovate faster and more securely, and to deliver consistently better business results. Further, automation has become a core strategy as organizations migrate to and operate in the cloud.
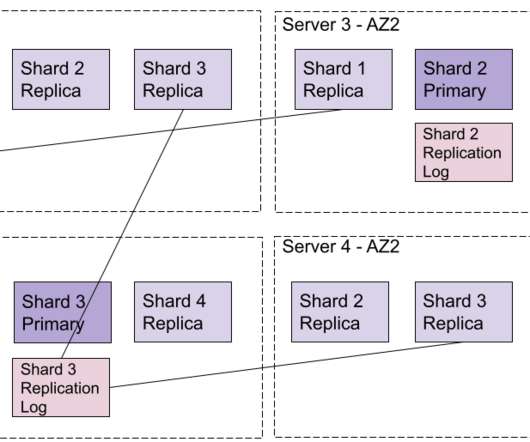
This section will provide insights into the architecture and strategies to ensure efficient query processing in a sharded environment. In this section, we’ll walk through the factors to consider when selecting a shard key, common mistakes to avoid, and how to balance performance with even data distribution.
2020 cemented the reality that modern software development practices require rapid, scalable delivery in response to unpredictable conditions. This method of structuring, developing, and operating complex, multi-function software as a collection of smaller independent services is known as microservice architecture. Dynatrace news.
2020 cemented the reality that modern software development practices require rapid, scalable delivery in response to unpredictable conditions. This method of structuring, developing, and operating complex, multi-function software as a collection of smaller independent services is known as microservice architecture. Dynatrace news.
This guide will cover how to distribute workloads across multiple nodes, set up efficient clustering, and implement robust load-balancing techniques. Key Takeaways RabbitMQ improves scalability and fault tolerance in distributed systems by decoupling applications, enabling reliable message exchanges.
Part 3: System Strategies and Architecture By: VarunKhaitan With special thanks to my stunning colleagues: Mallika Rao , Esmir Mesic , HugoMarques This blog post is a continuation of Part 2 , where we cleared the ambiguity around title launch observability at Netflix. The request schema for the observability endpoint.
This demand for rapid innovation is propelling organizations to adopt agile methodologies and DevOps principles to deliver software more efficiently and securely. And how do DevOps monitoring tools help teams achieve DevOps efficiency? Lost efficiency. 54% reported deploying updates every two hours or less.
Many organizations are taking a microservices approach to IT architecture. However, in some cases, an organization may be better suited to another architecture approach. Therefore, it’s critical to weigh the advantages of microservices against its potential issues, other architecture approaches, and your unique business needs.
Snowflake is a powerful cloud-based data warehousing platform known for its scalability and flexibility. To fully leverage its capabilities and improve efficient data processing, it's crucial to optimize query performance. Snowflake’s architecture consists of three main layers:
You can view the original article—H ow to implement consistent hashing efficiently —on Ably's blog. In this article, we’ll understand what consistent hashing is all about and why it is an essential tool in scalable distributed system architectures. Hashing revisited.
Thanks to its structured and binary format, Journald is quick and efficient. For forensic log analytics use cases, the Security Investigator app benefits from the scalability and analytics power of Dynatrace Grail. The Grail architecture ensures scalability, making log data accessible for detailed analysis regardless of volume.
To get a better understanding of AWS serverless, we’ll first explore the basics of serverless architectures, review AWS serverless offerings, and explore common use cases. Serverless architecture: A primer. Serverless architecture shifts application hosting functions away from local servers onto those managed by providers.
In this blog post, we explain what Greenplum is, and break down the Greenplum architecture, advantages, major use cases, and how to get started. It’s architecture was specially designed to manage large-scale data warehouses and business intelligence workloads by giving you the ability to spread your data out across a multitude of servers.
It’s a nice building with good architecture! However, a more scalable approach would be to begin with a new foundation and begin a new building. However, a more scalable approach would be to begin with a new foundation and begin a new building. The facilities are modern, spacious and scalable. What is SVT-AV1?
To take full advantage of the scalability, flexibility, and resilience of cloud platforms, organizations need to build or rearchitect applications around a cloud-native architecture. So, what is cloud-native architecture, exactly? What is cloud-native architecture? The principles of cloud-native architecture.
We’re delighted to share that IBM and Dynatrace have joined forces to bring the Dynatrace Operator, along with the comprehensive capabilities of the Dynatrace platform, to Red Hat OpenShift on the IBM Power architecture (ppc64le).
Enhanced data security, better data integrity, and efficient access to information. Despite initial investment costs, DBMS presents long-term savings and improved efficiency through automated processes, efficient query optimizations, and scalability, contributing to enhanced decision-making and end-user productivity.
Werner Vogels weblog on building scalable and robust distributed systems. a Fast and Scalable NoSQL Database Service Designed for Internet Scale Applications. The original Dynamo design was based on a core set of strong distributed systems principles resulting in an ultra-scalable and highly reliable database system.
As dynamic systems architectures increase in complexity and scale, IT teams face mounting pressure to track and respond to conditions and issues across their multi-cloud environments. An advanced observability solution can also be used to automate more processes, increasing efficiency and innovation among Ops and Apps teams.
As a micro-service owner, a Netflix engineer is responsible for its innovation as well as its operation, which includes making sure the service is reliable, secure, efficient and performant. In the Efficiency space, our data teams focus on transparency and optimization.
Grail architectural basics. The aforementioned principles have, of course, a major impact on the overall architecture. A data lakehouse addresses these limitations and introduces an entirely new architectural design. From the beginning, Grail was built to be fast and scalable to manage massive volumes of data.
Flow Exporter The Flow Exporter is a sidecar that uses eBPF tracepoints to capture TCP flows at near real time on instances that power the Netflix microservices architecture. After several iterations of the architecture and some tuning, the solution has proven to be able to scale. What is BPF?
The system could work efficiently with a specific number of concurrent users; however, it may get dysfunctional with extra loads during peak traffic. Performances testing helps establish the scalability, stability, and speed of the software application. Confirming scalability, dependability, stability, and speed of the app is crucial.
Without an efficient data retention strategy, this approach may struggle to scale effectively. Rollup Pipeline: Each Counter-Rollup server operates a rollup pipeline to efficiently aggregate counts across millions of counters. In the following sections, we will share key details on how efficient aggregations are achieved.
With more automated approaches to log monitoring and log analysis, however, organizations can gain visibility into their applications and infrastructure efficiently and with greater precision—even as cloud environments grow. Logs are automatically produced and time-stamped documentation of events relevant to cloud architectures.
Evaluating these on three levels—data center, host, and application architecture (plus code)—is helpful. Most approaches focus on improving Power Usage Effectiveness (PUE), a data center energy-efficiency measure. energy-efficient data centers—cloud providers—achieve values closer to 1.2. A PUE of 1.0
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content