This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In this blog post, we explain what Greenplum is, and break down the Greenplum architecture, advantages, major use cases, and how to get started. It’s architecture was specially designed to manage large-scale data warehouses and business intelligence workloads by giving you the ability to spread your data out across a multitude of servers.
Serverless architecture enables organizations to deliver applications more efficiently without the overhead of on-premises infrastructure, which has revolutionized software development. These tools simply can’t provide the observability needed to keep pace with the growing complexity and dynamism of hybrid and multicloud architecture.
Site reliability engineering (SRE) is the practice of applying software engineering principles to operations and infrastructure processes to help organizations create highly reliable and scalable software systems. Dynatrace news. What is site reliability engineering? Solving for SR.
The scope and scale of these environments are beyond human capacity to manage, with millions to billions of microservices coming and going each second in container-based architectures across multiple clouds. It’s an educated guess. To manage the complexity of these environments, teams need AI-assistance.
Site reliability engineering (SRE) is the practice of applying software engineering principles to operations and infrastructure processes to help organizations create highly reliable and scalable software systems. Dynatrace news. A major goal of SRE is to reduce duplication or redundancy of effort as much as possible. Solving for SR.
Our Journey so Far Over the past year, we’ve implemented the core infrastructure pieces necessary for a federated GraphQL architecture as described in our previous post: Studio Edge Architecture The first Domain Graph Service (DGS) on the platform was the former GraphQL monolith that we discussed in our first post (Studio API).
This information can enable more educated investment choices. The logs, metrics, traces, and other metadata that applications and infrastructure generate have historically been captured in separate data stores, creating poorly integrated data silos. These insights can reduce loan costs and protect against cascading defaults.
Consumers expect personalized, proactive, and convenient service, which traditional application architectures often struggle to provide. However, digital transformation requires significant investment in technology infrastructure and processes. Enable teams with ongoing education so they get the most out of Dynatrace capabilities.
Across the cloud operations lifecycle, especially in organizations operating at enterprise scale, the sheer volume of cloud-native services and dynamic architectures generate a massive amount of data. IT operations teams need ways to monitor infrastructure, even if it’s not within their data centers and under their direct management.
Over the past 18 months, the need to utilize cloud architecture has intensified. As dynamic systems architectures increase in complexity and scale, IT teams face mounting pressure to track and respond to the activity in their multi-cloud environments. Modern cloud-native environments rely heavily on microservices architectures.
Further discussions of emerging trends and opportunities ensure that this revised edition will remain an essential resource for educators and professionals working on the next generation of WSCs. At 189 pages it's not exactly light reading, but it's packed with information you can't find anywhere else.
Learn to balance architecture trade-offs and design scalable enterprise-level software. More than 400 companies rely on Stream for their production feed infrastructure, this includes apps with 30 million users. Created by former senior-level AWS engineers of 15 years. Stateful JavaScript Apps. Generous free tier.
I should start by saying this section does not offer a treatise on how to do architecture. Vitruvius and the principles of architecture. Architecture begins when someone has a nontrivial problem to be solved. Everyone who goes to architecture school learns his work. It must be beautiful, like Venus, inspiring love.
Learn to balance architecture trade-offs and design scalable enterprise-level software. More than 400 companies rely on Stream for their production feed infrastructure, this includes apps with 30 million users. Created by former senior-level AWS engineers of 15 years. Stateful JavaScript Apps. Generous free tier.
Learn to balance architecture trade-offs and design scalable enterprise-level software. More than 400 companies rely on Stream for their production feed infrastructure, this includes apps with 30 million users. Created by former senior-level AWS engineers of 15 years. Stateful JavaScript Apps. Generous free tier.
Learn to balance architecture trade-offs and design scalable enterprise-level software. More than 400 companies rely on Stream for their production feed infrastructure, this includes apps with 30 million users. Created by former senior-level AWS engineers of 15 years. Stateful JavaScript Apps. Generous free tier.
As Kinsta’s DevOps Engineer, you will be instrumental in making sure that our infrastructure is always on the bleeding edge of technology, remaining stable and high-performing at all times. Learn to balance architecture trade-offs and design scalable enterprise-level software. Get started for free! Stateful JavaScript Apps.
As Kinsta’s DevOps Engineer, you will be instrumental in making sure that our infrastructure is always on the bleeding edge of technology, remaining stable and high-performing at all times. Learn to balance architecture trade-offs and design scalable enterprise-level software. Get started for free! Stateful JavaScript Apps.
Learn to balance architecture trade-offs and design scalable enterprise-level software. More than 400 companies rely on Stream for their production feed infrastructure, this includes apps with 30 million users. Created by former senior-level AWS engineers of 15 years. Stateful JavaScript Apps. Generous free tier.
As Kinsta’s DevOps Engineer, you will be instrumental in making sure that our infrastructure is always on the bleeding edge of technology, remaining stable and high-performing at all times. No more hassles of benchmarking and tuning algorithms or building and maintaining infrastructure for vector search. Get started for free!
Learn to balance architecture trade-offs and design scalable enterprise-level software. More than 400 companies rely on Stream for their production feed infrastructure, this includes apps with 30 million users. Created by former senior-level AWS engineers of 15 years. Stateful JavaScript Apps. Generous free tier.
Learn to balance architecture trade-offs and design scalable enterprise-level software. More than 400 companies rely on Stream for their production feed infrastructure, this includes apps with 30 million users. Created by former senior-level AWS engineers of 15 years. Stateful JavaScript Apps. Generous free tier.
As Kinsta’s DevOps Engineer, you will be instrumental in making sure that our infrastructure is always on the bleeding edge of technology, remaining stable and high-performing at all times. Pinecone runs on managed, distributed infrastructure, so everything happens in real-time at any scale, even with billions of items.
As Kinsta’s DevOps Engineer, you will be instrumental in making sure that our infrastructure is always on the bleeding edge of technology, remaining stable and high-performing at all times. Pinecone runs on managed, distributed infrastructure, so everything happens in real-time at any scale, even with billions of items.
As Kinsta’s DevOps Engineer, you will be instrumental in making sure that our infrastructure is always on the bleeding edge of technology, remaining stable and high-performing at all times. Pinecone runs on managed, distributed infrastructure, so everything happens in real-time at any scale, even with billions of items.
As Kinsta’s DevOps Engineer, you will be instrumental in making sure that our infrastructure is always on the bleeding edge of technology, remaining stable and high-performing at all times. No more hassles of benchmarking and tuning algorithms or building and maintaining infrastructure for vector search. Get started for free!
As Kinsta’s DevOps Engineer, you will be instrumental in making sure that our infrastructure is always on the bleeding edge of technology, remaining stable and high-performing at all times. No more hassles of benchmarking and tuning algorithms or building and maintaining infrastructure for vector search. Get started for free!
As Kinsta’s DevOps Engineer, you will be instrumental in making sure that our infrastructure is always on the bleeding edge of technology, remaining stable and high-performing at all times. No more hassles of benchmarking and tuning algorithms or building and maintaining infrastructure for vector search. Get started for free!
Learn to balance architecture trade-offs and design scalable enterprise-level software. More than 400 companies rely on Stream for their production feed infrastructure, this includes apps with 30 million users. Created by former senior-level AWS engineers of 15 years. Stateful JavaScript Apps. Generous free tier.
Learn to balance architecture trade-offs and design scalable enterprise-level software. More than 400 companies rely on Stream for their production feed infrastructure, this includes apps with 30 million users. Created by former senior-level AWS engineers of 15 years. Stateful JavaScript Apps. Generous free tier.
Learn to balance architecture trade-offs and design scalable enterprise-level software. More than 400 companies rely on Stream for their production feed infrastructure, this includes apps with 30 million users. Created by former senior-level AWS engineers of 15 years. Stateful JavaScript Apps. Generous free tier.
By leveraging automation and delivering security-as-code, Bridgecrew empowers teams to find, fix, and prevent misconfigurations in deployed cloud resources and in infrastructure as code. Learn to balance architecture trade-offs and design scalable enterprise-level software. Bridgecrew is the cloud security platform for developers.
As Kinsta’s DevOps Engineer, you will be instrumental in making sure that our infrastructure is always on the bleeding edge of technology, remaining stable and high-performing at all times. Learn to balance architecture trade-offs and design scalable enterprise-level software. Get started for free. Get started for free!
As Kinsta’s DevOps Engineer, you will be instrumental in making sure that our infrastructure is always on the bleeding edge of technology, remaining stable and high-performing at all times. Learn to balance architecture trade-offs and design scalable enterprise-level software. Get started for free. Get started for free!
As Kinsta’s DevOps Engineer, you will be instrumental in making sure that our infrastructure is always on the bleeding edge of technology, remaining stable and high-performing at all times. Learn to balance architecture trade-offs and design scalable enterprise-level software. Get started for free! Stateful JavaScript Apps.
As Kinsta’s DevOps Engineer, you will be instrumental in making sure that our infrastructure is always on the bleeding edge of technology, remaining stable and high-performing at all times. Learn to balance architecture trade-offs and design scalable enterprise-level software. Get started for free! Stateful JavaScript Apps.
If you have a passion for databases (both SQL and NoSQL), significant experience building, managing, and monitoring infrastructure, databases, and backend services at scale and want to work with a rag-tag team of hardworking, but humble humans, then come check us out! Get started for free. Get started for free! Stateful JavaScript Apps.
Learn to balance architecture trade-offs and design scalable enterprise-level software. More than 400 companies rely on Stream for their production feed infrastructure, this includes apps with 30 million users. Created by former senior-level AWS engineers of 15 years. Stateful JavaScript Apps. Generous free tier.
Learn to balance architecture trade-offs and design scalable enterprise-level software. More than 400 companies rely on Stream for their production feed infrastructure, this includes apps with 30 million users. Created by former senior-level AWS engineers of 15 years. Stateful JavaScript Apps. Generous free tier.
By leveraging automation and delivering security-as-code, Bridgecrew empowers teams to find, fix, and prevent misconfigurations in deployed cloud resources and in infrastructure as code. Learn to balance architecture trade-offs and design scalable enterprise-level software. Bridgecrew is the cloud security platform for developers.
By leveraging automation and delivering security-as-code, Bridgecrew empowers teams to find, fix, and prevent misconfigurations in deployed cloud resources and in infrastructure as code. Learn to balance architecture trade-offs and design scalable enterprise-level software. Bridgecrew is the cloud security platform for developers.
By leveraging automation and delivering security-as-code, Bridgecrew empowers teams to find, fix, and prevent misconfigurations in deployed cloud resources and in infrastructure as code. Learn to balance architecture trade-offs and design scalable enterprise-level software. Bridgecrew is the cloud security platform for developers.
By leveraging automation and delivering security-as-code, Bridgecrew empowers teams to find, fix, and prevent misconfigurations in deployed cloud resources and in infrastructure as code. Learn to balance architecture trade-offs and design scalable enterprise-level software. Bridgecrew is the cloud security platform for developers.
As Kinsta’s DevOps Engineer, you will be instrumental in making sure that our infrastructure is always on the bleeding edge of technology, remaining stable and high-performing at all times. Learn to balance architecture trade-offs and design scalable enterprise-level software. Get started for free! Stateful JavaScript Apps.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






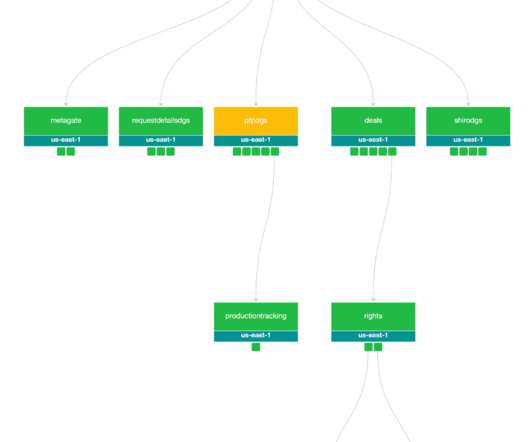






































Let's personalize your content