This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
DevOps and security teams managing today’s multicloud architectures and cloud-native applications are facing an avalanche of data. Find and prevent application performance risks A major challenge for DevOps and security teams is responding to outages or poor application performance fast enough to maintain normal service.
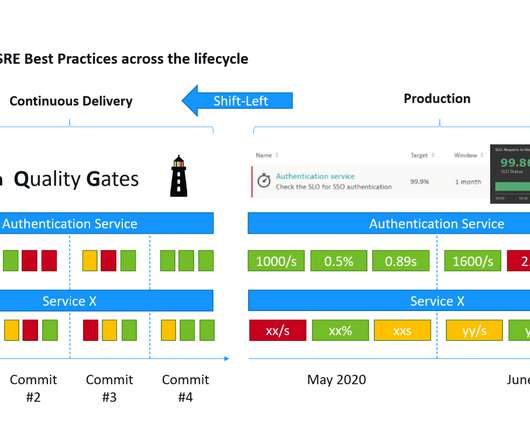
This is a mouthful of buzzwords” is how I started my recent presentations at the Online Kubernetes Meetup as well as the DevOps Fusion 2020 Online Conference when explaining the three big challenges we are trying to solve with Keptn – our CNCF Open Source project: Automate build validation through SLI/SLO-based Quality Gates. Dynatrace news.
As dynamic systems architectures increase in complexity and scale, IT teams face mounting pressure to track and respond to conditions and issues across their multi-cloud environments. As a result, IT operations, DevOps , and SRE teams are all looking for greater observability into these increasingly diverse and complex computing environments.
With the world’s increased reliance on digital services and the organizational pressure on IT teams to innovate faster, the need for DevOps monitoring tools has grown exponentially. But when and how does DevOps monitoring fit into the process? And how do DevOps monitoring tools help teams achieve DevOps efficiency?
That’s especially true of the DevOps teams who must drive digital-fueled sustainable growth. All of these factors challenge DevOps maturity. Data scale and silos present challenges to DevOps maturity DevOps teams often run into problems trying to drive better data-driven decisions with observability and security data.
I realized that our platforms unique ability to contextualize security events, metrics, logs, traces, and user behavior could revolutionize the security domain by converging observability and security. Collect observability and security data user behavior, metrics, events, logs, traces (UMELT) once, store it together and analyze in context.
When it comes to site reliability engineering (SRE) initiatives adopting DevOps practices, developers and operations teams frequently find themselves at odds with one another. Too many SLOs create complexity for DevOps. With many pipelines to maintain, DevOps teams need automated orchestration. Dynatrace news.
Many organizations are taking a microservices approach to IT architecture. A microservices approach enables DevOps teams to develop an application as a suite of small services. However, in some cases, an organization may be better suited to another architecture approach. What is the monolithic architecture approach?
To keep up, we’ve seen growing interest in DevOps and continuous delivery , as organizations aim to deliver new digital services and experiences faster. However, it isn’t as simple as just implementing a DevOps toolset, analyzing DevOpsmetrics, or investing in DevOps monitoring capabilities. What is DevOps?
As more organizations transition to distributed services, IT teams are experiencing the limitations of traditional monitoring tools, which were designed for yesterday’s monolithic architectures. The post Gartner: Observability drives the future of cloud monitoring for DevOps and SREs appeared first on Dynatrace blog.
This method of structuring, developing, and operating complex, multi-function software as a collection of smaller independent services is known as microservice architecture. Using a microservices approach, DevOps teams split services into functional APIs instead of shipping applications as one collective unit. Microservices benefits.
This method of structuring, developing, and operating complex, multi-function software as a collection of smaller independent services is known as microservice architecture. Using a microservices approach, DevOps teams split services into functional APIs instead of shipping applications as one collective unit. Microservices benefits.
Loosely defined, observability is the ability to understand what’s happening inside a system from the knowledge of the external data it produces, which are usually logs, metrics, and traces. OpenTelemetry reference architecture. Logs, metrics, and traces make up the bulk of all telemetry data. What is telemetry data?
As more organizations embrace microservices-based architecture to deliver goods and services digitally, maintaining customer satisfaction has become exponentially more challenging. By implementing service-level objectives, teams can avoid collecting and checking a huge amount of metrics for each service. SLOs minimize downtime.
In serverless and microservices architectures, messaging systems are often used to build asynchronous service-to-service communication. To know which services are impacted, DevOps teams need to know what’s happening with their messaging systems. Seamless observability of messaging systems is critical for DevOps teams.
To take full advantage of the scalability, flexibility, and resilience of cloud platforms, organizations need to build or rearchitect applications around a cloud-native architecture. So, what is cloud-native architecture, exactly? What is cloud-native architecture? The principles of cloud-native architecture.
Organizations are depending more and more on distributed architectures to provide application services. Monitoring focuses on watching specific metrics. Observability is the ability to understand a system’s internal state by analyzing the data it generates, such as logs, metrics, and traces. Dynatrace news.
Dynatrace enables various teams, such as developers, threat hunters, business analysts, and DevOps, to effortlessly consume advanced log insights within a single platform. DevOps teams operating, maintaining, and troubleshooting Azure, AWS, GCP, or other cloud environments are provided with an app focused on their daily routines and tasks.
IT, DevOps, and SRE teams are racing to keep up with the ever-expanding complexity of modern enterprise cloud ecosystems and the business demands they are designed to support. Observability is the new standard of visibility and monitoring for cloud-native architectures. Dynatrace news. Leaders in tech are calling for radical change.
Serverless architecture enables organizations to deliver applications more efficiently without the overhead of on-premises infrastructure, which has revolutionized software development. These tools simply can’t provide the observability needed to keep pace with the growing complexity and dynamism of hybrid and multicloud architecture.
As organizations look to expand DevOps maturity, improve operational efficiency, and increase developer velocity, they are embracing platform engineering as a key driver. The pair showed how to track factors including developer velocity, platform adoption, DevOps research and assessment metrics, security, and operational costs.
As companies accelerate digital transformation, cloud services such as AWS Lambda help companies to modernize their application architectures to quickly adapt to the needs of their customers while offloading the operational complexity to their cloud vendor. The need for a simplified approach to capture telemetry. How to get started.
With a growing number of cloud-native applications built on containers and microservices-based architectures, the number and variety of databases become complex and difficult to manage at scale. In enterprise environments, DevOps and SRE teams struggle to optimize and troubleshoot databases and the applications they support at scale.
Data lakehouse architecture stores data insights in context — handbook Organizations need a data architecture that can cost-efficiently store data and enable IT pros to access it in real time and with proper context. DevOpsmetrics and digital experience data are critical to this. Learn more. Here is what they reported.
Observability is made up of three key pillars: metrics, logs, and traces. Metrics are measures of critical system values, such as CPU utilization or average write latency to persistent storage. They are particularly important in distributed systems, such as microservices architectures.
Gone are the days for Christian manually looking at dashboards and metrics after a new build got deployed into a testing or acceptance environment: Integrating Keptn into your existing DevOps tools such as GitLab is just a matter of an API call.
Conventional approaches to application security can’t keep pace with cloud-native environments that rely on agile methodologies, API-driven architectures, microservices, containers, and serverless functions. Dynatrace news. You can find further details in Dynatrace Documentation.
A service-level objective ( SLO ) is the new contract between business, DevOps, and site reliability engineers (SREs). Example 1: Architecture boundaries. First, they took a big step back and looked at their end-to-end architecture (Figure 2). SLO dashboard defined by architectural boundary. So, what did they do?
And for observability to be successful, it requires much more than just logs, metrics, and traces. We start with metrics, traces, and logs (that’s table stakes) but also provide context and enrichment through topology, behavior, code, metadata, and network, combined with data from application programming interfaces (API) and OpenTelemetry.
Log monitoring, log analysis, and log analytics are more important than ever as organizations adopt more cloud-native technologies, containers, and microservices-based architectures. With clear insight into crucial system metrics, teams can automate more processes and responses with greater precision. Dynatrace news. What are logs?
Introducing Pitometer: Metrics-based Deployment Validation in your CI/CD. The following shows how to evaluate a deployment score based on metrics from Prometheus and Dynatrace. Bamboo, Azure DevOps, AWS CodePipeline …. Beyond basic metrics: Detecting Architectural Regressions. Pitometer is a Node.js
A service mesh is a dedicated infrastructure layer built into an application that controls service-to-service communication in a microservices architecture. A service mesh enables DevOps teams to manage their networking and security policies through code. What is a service mesh?
As a result, site reliability has emerged as a critical success metric for many organizations. Microservices-based architectures and software containers enable organizations to deploy and modify applications with unprecedented speed. That’s why good communication between SREs and DevOps teams is important. availability.
Also, these modern, cloud-native architectures produce an immense volume, velocity, and variety of data. Every service and component exposes observability data (metrics, logs, and traces) that contains crucial information to drive digital businesses. Track log metrics and receive alerts without manually setting thresholds.
Cloud application security remains challenging because organizations lack end-to-end visibility into cloud architecture. As organizations migrate applications to the cloud, they must balance the agility that microservices architecture brings with the complexity and lack of transparency that can also come with it.
Cloud-native applications now dominate IT as DevOps teams respond to growing demands to deliver functionality faster and more securely. As DevOps teams are pivoting to cloud-native technologies, IT environments have become increasingly complex. Dynatrace news. Improving cross-team collaboration improves cloud-native success.
The goal was to develop a custom solution that enables DevOps and engineering teams to analyze and improve pipeline performance issues and alert on health metrics across CI/CD platforms. Figure 2 provides an overview of Dynatrace’s core platform components which customers and partners can leverage to build custom apps.
This involves new software delivery models, adapting to complex software architectures, and embracing automation for analysis and testing. Install the Dynatrace OneAgent to gather metrics and feed the Dynatrace AI-powered problem causation engine that automatically shows impacted users, system, and root cause during testing.
IT, DevOps, and SRE teams seeking to know the health of their apps and services have always faced obstacles that can drain productivity, stifle collaboration, ratchet up the time to resolution, and limit the effectiveness of their collaboration with other parts of the business. Dynatrace news.
Thus, modern AIOps solutions encompass observability, AI, and analytics to help teams automate use cases related to cloud operations (CloudOps), software development and operations (DevOps), and securing applications (SecOps). DevOps: Applying AIOps to development environments. The deviating metric is response time.
As more organizations are moving from monolithic architectures to cloud architectures, the complexity continues to increase. In a machine learning model, a statistical analysis of current metrics, events, and alerts helps build a multidimensional model of a system to provide possible explanations for observed behavior.
A single pane of glass to view trace information along with AWS CloudWatch metrics. Serverless architectures help developers innovate more efficiently and effectively by removing the burden of managing underlying infrastructure. See your AWS serverless workloads in full context with customer experience and business outcome metrics.
To drive better outcomes using hybrid cloud architectures, it helps to understand their benefits—and how to orchestrate them seamlessly. What is hybrid cloud architecture? Hybrid cloud architecture is a computing environment that shares data and applications on a combination of public clouds and on-premises private clouds.
We believe at Soldo that efficiency is the key value to be very successful in the business we run,” said Luca Domenella, head of cloud operations and DevOps at Soldo. With end-to-end observability , the DevOps teams at Soldo can create rules and manage workflows. The most efficient one we found was Dynatrace.”
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content