This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
DevOps and security teams managing today’s multicloud architectures and cloud-native applications are facing an avalanche of data. Find and prevent application performance risks A major challenge for DevOps and security teams is responding to outages or poor application performance fast enough to maintain normal service.
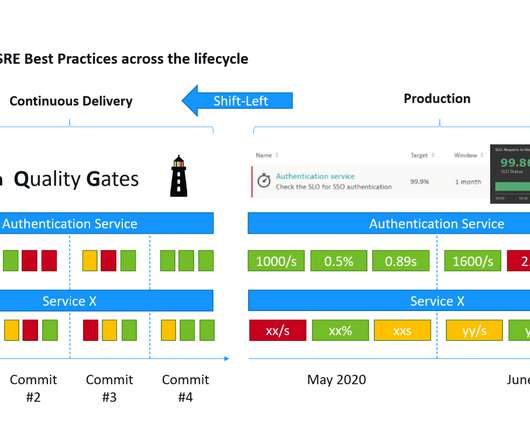
“This is a mouthful of buzzwords” is how I started my recent presentations at the Online Kubernetes Meetup as well as the DevOps Fusion 2020 Online Conference when explaining the three big challenges we are trying to solve with Keptn – our CNCF Open Source project: Automate build validation through SLI/SLO-based Quality Gates.
Takeaways from this article on DevOps practices: DevOps practices bring developers and operations teams together and enable more agile IT. Still, while DevOps practices enable developer agility and speed as well as better code quality, they can also introduce complexity and data silos. They need automated DevOps practices.
Streamlining site reliability at scale can be daunting, particularly with large-scale AWS environments and architecture that rely on hundredsor even thousandsof Amazon EC2 instances. This step-by-step guide will show you how to configure your architecture to trigger guardians whenever EC2 tags are updated.
I realized that our platforms unique ability to contextualize security events, metrics, logs, traces, and user behavior could revolutionize the security domain by converging observability and security. Collect observability and security data user behavior, metrics, events, logs, traces (UMELT) once, store it together and analyze in context.
When it comes to site reliability engineering (SRE) initiatives adopting DevOps practices, developers and operations teams frequently find themselves at odds with one another. Too many SLOs create complexity for DevOps. With many pipelines to maintain, DevOps teams need automated orchestration. Dynatrace news.
The first part of this blog post briefly explores the integration of SLO events with AI. Consequently, the AI is founded upon the related events, and due to the detection parameters (threshold, period, analysis interval, frequent detection, etc), an issue arose. See the following example with BurnRate formula for Failure rate event.
Data-driven applications span a wide breadth of complexity, from simple microservices to real-time event-driven systems under significant load. However, as any development and/or DevOps team tasked with performance improvements will attest, making data-driven apps fast globally is “non-trivial”. Guest post by Ben Hagan from PolyScale.ai
To keep up with current demands, DevOps and platform engineering teams need a solution that can fully embrace and understand complexity, delivering precise answers that enable the creation of trustworthy automation. The effectiveness of this automation relies on the quality of the underlying data.
Autonomous Cloud Enablement (ACE) and Keptn – the Event-Driven Autonomous Cloud Control Plane – are helping our Dynatrace customers to automate their delivery and operations processes. Dynatrace news. There’s more from Christian and the rest of the Keptn and Autonomous Cloud community that we can all benefit from.
Developing applications based on modern architectures comes with a challenge for release automation: integrating delivery of many services with similar processes but often with different technologies and tools along the delivery pipelines. Dynatrace helps to orchestrate processes independently of DevOps tooling. Dynatrace news.
Over the past 18 months, the need to utilize cloud architecture has intensified. As dynamic systems architectures increase in complexity and scale, IT teams face mounting pressure to track and respond to the activity in their multi-cloud environments. Modern cloud-native environments rely heavily on microservices architectures.
Cloud vendors such as Amazon Web Services (AWS), Microsoft, and Google provide a wide spectrum of serverless services for compute and event-driven workloads, databases, storage, messaging, and other purposes. AI-powered automation and deep, broad observability for serverless architectures. Dynatrace news.
Log monitoring, log analysis, and log analytics are more important than ever as organizations adopt more cloud-native technologies, containers, and microservices-based architectures. A log is a detailed, timestamped record of an event generated by an operating system, computing environment, application, server, or network device.
.” As more organizations expand services via the cloud and demand for digital services increases, SRE practices are essential to meet up-time service level agreements, and to meet the continuous-integration/continuous-delivery (CI/CD) demands of DevOps and DevSecOps teams. SRE bridges the gap between Dev and Ops teams. Solving for SR.
Serverless architecture enables organizations to deliver applications more efficiently without the overhead of on-premises infrastructure, which has revolutionized software development. These tools simply can’t provide the observability needed to keep pace with the growing complexity and dynamism of hybrid and multicloud architecture.
With a growing number of cloud-native applications built on containers and microservices-based architectures, the number and variety of databases become complex and difficult to manage at scale. In enterprise environments, DevOps and SRE teams struggle to optimize and troubleshoot databases and the applications they support at scale.
As dynamic systems architectures increase in complexity and scale, IT teams face mounting pressure to track and respond to conditions and issues across their multi-cloud environments. As a result, IT operations, DevOps , and SRE teams are all looking for greater observability into these increasingly diverse and complex computing environments.
Amplify PowerUP, our half-yearly global event to update our partner community, covered a lot of ground including key Partner Program announcements, Q2 earnings and partner contribution, market growth and momentum, Dynatrace platform capabilities, and the partner services offering the platform powers. DevOps and Cloud Ops Automation.
IT, DevOps, and SRE teams are racing to keep up with the ever-expanding complexity of modern enterprise cloud ecosystems and the business demands they are designed to support. Observability is the new standard of visibility and monitoring for cloud-native architectures. Dynatrace news. Leaders in tech are calling for radical change.
As organizations look to expand DevOps maturity, improve operational efficiency, and increase developer velocity, they are embracing platform engineering as a key driver. The pair showed how to track factors including developer velocity, platform adoption, DevOps research and assessment metrics, security, and operational costs.
As more organizations are moving from monolithic architectures to cloud architectures, the complexity continues to increase. AI applies advanced analytics and logic-based techniques to interpret data and events, support and automate decisions, and even take intelligent actions. IT operations don’t exist in a vacuum.
While the benefits of AIOps are plentiful — including increased automation, improved event prioritization and incident response, and accelerated digital transformation — applying AIOps use cases to an organization’s real-world operations issues can be challenging. CloudOps includes processes such as incident management and event management.
.” As more organizations expand services via the cloud and demand for digital services increases, SRE practices are essential to meet up-time service level agreements, and to meet the continuous-integration/continuous-delivery (CI/CD) demands of DevOps and DevSecOps teams. SRE bridges the gap between Dev and Ops teams. Solving for SR.
Kailey Smith, application architect on the DevOps team for Minnesota IT Services (MNIT), discussed her experience with an outage that left her and her peers to play defense and fight fires. State agencies measurably reduce outage severity and costs In the event of a performance problem, observability can reduce MTTR.
Also, these modern, cloud-native architectures produce an immense volume, velocity, and variety of data. Logs and events play an essential role in this mix; they include critical information which can’t be found anywhere else, like details on transactions, processes, users and environment changes.
Dynatrace enables various teams, such as developers, threat hunters, business analysts, and DevOps, to effortlessly consume advanced log insights within a single platform. DevOps teams operating, maintaining, and troubleshooting Azure, AWS, GCP, or other cloud environments are provided with an app focused on their daily routines and tasks.
To adapt, many are turning to AIOps and other automation technologies to solve the complex issues that accompany cloud-native architecture. This traditional approach to observability lacks the specificity needed to keep pace with cloud-native environments and automate DevOps processes.
Gartner defines AIOps as the combination of “big data and machine learning to automate IT operations processes, including event correlation, anomaly detection, and causality determination.” Typically, only the aggregated events will be accessible to ML and will often exclude additional details. What is AIOps?
Cloud application security remains challenging because organizations lack end-to-end visibility into cloud architecture. As organizations migrate applications to the cloud, they must balance the agility that microservices architecture brings with the complexity and lack of transparency that can also come with it.
Automatically collect and evaluate business, service, and architectural indicator metrics to promote or roll back deployments. Successful DevOps teams have figured out that “delivering more with less” requires careful management of release risks and automation to scale. Example #2 – Deployment information events.
Indeed, according to one survey, DevOps practices have led to 60% of developers releasing code twice as quickly. According to a Gartner report, “By 2023, 60% of organizations will use infrastructure automation tools as part of their DevOps toolchains, improving application deployment efficiency by 25%.”.
An example of a critical event-based messaging service for many businesses is adding a product to a shopping cart. In serverless and microservices architectures, messaging systems are often used to build asynchronous service-to-service communication. Seamless observability of messaging systems is critical for DevOps teams.
Check out the guide from last year’s event. Data lakehouse architecture stores data insights in context — handbook Organizations need a data architecture that can cost-efficiently store data and enable IT pros to access it in real time and with proper context. We’ll post news here as it happens! Learn more.
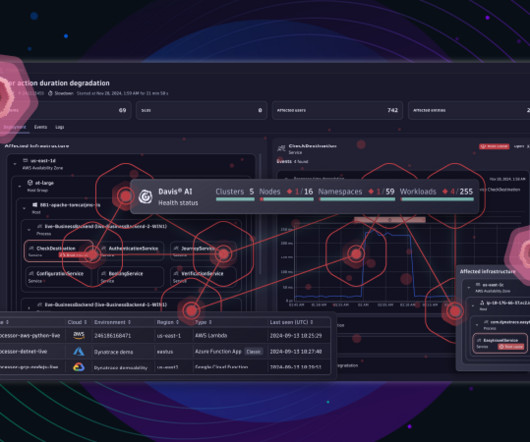
Modern observability has evolved from simple metric telemetry monitoring to encompass a wide range of data, including logs, traces, events, alerts, and resource attributes. Instead, you receive an AI-generated summary as an affected deployment architecture diagram. Confirm the AI-detected root cause and review the deployment context.
Trace your application Imagine a microservices architecture with hundreds of dependencies. This architecture also means you’re not required to determine your log data use cases beforehand or while analyzing logs within the new logs app. Interact with data intuitively and easily and benefit from immediate, AI-supported insights.
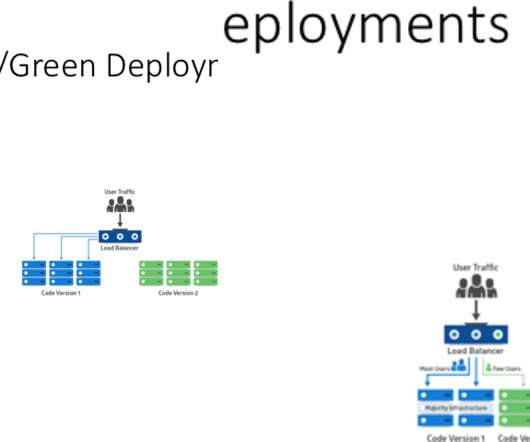
In the past, monolith architectures could only be implemented with big bang deployments which result in a slow pace of innovation and significant downtime. Dynatrace provides built-in features, such as tagging, adding deployment events, and request tagging to mark and compare deployments for performance and feature parity.
ITOps vs. DevOps and DevSecOps. ITOps is responsible for all an organization’s IT operations, including the end users’ IT needs, while DevOps is focused on agile continuous integration and delivery (CI/CD) practices and improving workflows. DevOps works in conjunction with IT. ITOps vs. AIOps.
As more organizations embrace microservices-based architecture to deliver goods and services digitally, maintaining customer satisfaction has become exponentially more challenging. SLOs enable DevOps teams to predict problems before they occur and especially before they affect customer experience. SLOs minimize downtime.
For Federal, State and Local agencies to take full advantage of the agility and responsiveness of a DevOps approach to the software lifecycle, Security must also play an integral role across lifecycle stages. Modern DevOps permits high velocity development cycles resulting in weekly, daily, or even hourly software releases.
Scale with confidence: Leverage AI for instant insights and preventive operations Using Dynatrace, Operations, SRE, and DevOps teams can scale efficiently while maintaining software quality and ensuring security and reliability. With a single click in Problems, all incident logs are surfaced automatically.
Security analysts are drowning, with 70% of security events left unexplored , crucial months or even years can pass before breaches are understood. After a security event, many organizations often don’t know for months—or even years—when, why, or how it happened. Learn more in this blog.
AWS Lambda is a serverless compute service that can run code in response to predetermined events or conditions and automatically manage all the computing resources required for those processes. It also enables DevOps teams to connect to any number of AWS services or run their own functions. Many events can trigger a lambda function.
At its most basic, automating IT processes works by executing scripts or procedures either on a schedule or in response to particular events, such as checking a file into a code repository. When monitoring tools release a stream of alerts, teams can easily identify which ones are false and assess whether an event requires human intervention.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content