This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
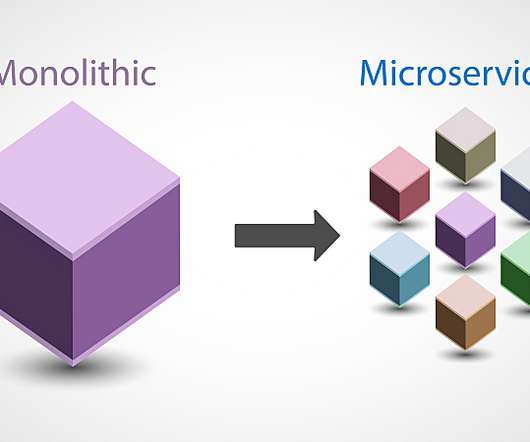
The Evolution of Back-End Complexity Until recently, back-end architectures were relatively straightforward: monolithic applications ruled the landscape, with everything neatly contained within a single codebase. Developers could understand and manage the entire systems intricacies.
Developers are key stakeholders in modern observability. In this blog post, we will see how Dynatrace harnesses the power of observability and analytics to tailor a new experience to easily extend to the left, allowing developers to solve issues faster, build more efficient software, and ultimately improve developer experience!
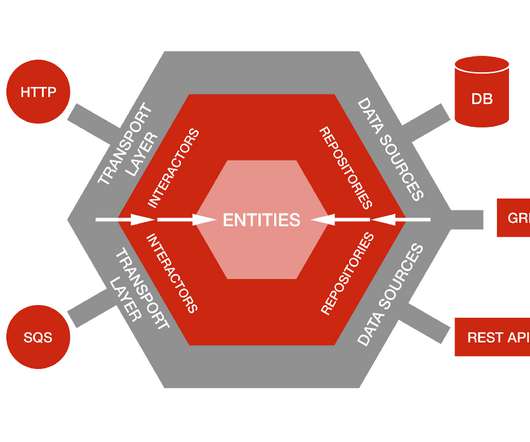
by Damir Svrtan and Sergii Makagon As the production of Netflix Originals grows each year, so does our need to build apps that enable efficiency throughout the entire creative process. The monolith allowed for rapid development and quick changes while the knowledge of the space was non-existent. Entities are the domain objects (e.g.,
2020 cemented the reality that modern software development practices require rapid, scalable delivery in response to unpredictable conditions. This method of structuring, developing, and operating complex, multi-function software as a collection of smaller independent services is known as microservice architecture.
2020 cemented the reality that modern software development practices require rapid, scalable delivery in response to unpredictable conditions. This method of structuring, developing, and operating complex, multi-function software as a collection of smaller independent services is known as microservice architecture.
Protect data in multi-tenant architectures To bring you the most value by unifying observability and security in one analytics and automation platform powered by AI, Dynatrace SaaS leverages a multitenancy architecture, enabling efficient and scalable data ingestion, querying, and processing on shared infrastructure.
If you are living in the same world as I am, you must have heard the latest coding buzzer termed “ microservices ”—a lifeline for developers and enterprise-scale businesses. Over the last few years, microservice architecture emerged to be on top of conventional SOA (Service Oriented Architecture).
As the pace of business quickens, software development has adapted. As a result, organizations are weighing microservices vs. monolithic architecture to improve software delivery speed and quality. Shifting from monolith to microservices makes it easier to test, develop, and release innovative features more rapidly.
This blog post will explore these exciting developments and what they mean for organizations. This integration simplifies the process of embedding Dynatrace full-stack observability directly into custom Amazon Machine Images (AMIs). Together, Dynatrace and AWS are paving the way for more robust and agile cloud solutions.
Many organizations are taking a microservices approach to IT architecture. A microservices approach enables DevOps teams to develop an application as a suite of small services. However, in some cases, an organization may be better suited to another architecture approach. What is the monolithic architecture approach?
Future blogs will provide deeper dives into each service, sharing insights and lessons learned from this process. The Netflix video processing pipeline went live with the launch of our streaming service in 2007. The Netflix video processing pipeline went live with the launch of our streaming service in 2007.
A Data Movement and Processing Platform @ Netflix By Bo Lei , Guilherme Pires , James Shao , Kasturi Chatterjee , Sujay Jain , Vlad Sydorenko Background Realtime processing technologies (A.K.A stream processing) is one of the key factors that enable Netflix to maintain its leading position in the competition of entertaining our users.
Early this year, the book Software Architecture Metrics: Case Studies to Improve the Quality of Your Architecture was published. He wrote a chapter that is particularly useful in contexts where the architecture and environment still have many opportunities for improvement. Intro and Problem Statement.
One of those beautiful complications was the introduction of Agile methodologies, which have become a standard in software development by shifting how we develop software into a more responsive and collaborative process. Fortunately, the concept of Architectural Observability steps in to help.
RabbitMQ is designed for flexible routing and message reliability, while Kafka handles high-throughput event streaming and real-time data processing. This article outlines the key differences in architecture, performance, and use cases to help determine the best fit for your workload. What is RabbitMQ? What is Apache Kafka?
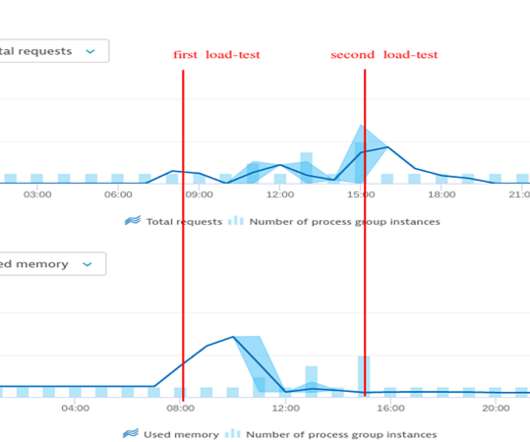
Today’s story is about how the Keptn development team is using Dynatrace during development and load-testing. We were in the process of developing a new feature and wanted to make sure it could handle the expected load behavior. Conclusion: Dynatrace is always on for us developers. It happened in June 2020.
Part 3: System Strategies and Architecture By: VarunKhaitan With special thanks to my stunning colleagues: Mallika Rao , Esmir Mesic , HugoMarques This blog post is a continuation of Part 2 , where we cleared the ambiguity around title launch observability at Netflix. The response schema for the observability endpoint.
This blog post dissects the vulnerability, explains how Struts processes file uploads, details the exploit mechanics, and outlines mitigation strategies. Developers and security professionals should take immediate steps to ensure the security of their Struts-based applications. and later, where the legacy class is fully removed.
We recently announced Dynatrace Live Debugger , which gives developers unprecedented access to real-time data and runtime behavior insights. This powerful tool can be leveraged across various environments, including production, to enhance developmentprocesses and ensure robust application performance.
Greenplum Database is a massively parallel processing (MPP) SQL database that is built and based on PostgreSQL. In this blog post, we explain what Greenplum is, and break down the Greenplum architecture, advantages, major use cases, and how to get started. The Greenplum Architecture. The Greenplum Architecture.
As organizations look to expand DevOps maturity, improve operational efficiency, and increase developer velocity, they are embracing platform engineering as a key driver. The goal is to abstract away the underlying infrastructure’s complexities while providing a streamlined and standardized environment for development teams.
At the 2024 Dynatrace Perform conference in Las Vegas, Michael Winkler, senior principal product management at Dynatrace, ran a technical session exploring just some of the many ways in which Dynatrace helps to automate the processes around development, releases, and operation. Real-time detection for fast remediation.
This scenario underscored the need for a new recommender system architecture where member preference learning is centralized, enhancing accessibility and utility across different models. This limitation has inspired us to develop a foundation model for recommendation.
by Jun He , Yingyi Zhang , and Pawan Dixit Incremental processing is an approach to process new or changed data in workflows. The key advantage is that it only incrementally processes data that are newly added or updated to a dataset, instead of re-processing the complete dataset.
In today's fast-paced software development landscape, microservices have emerged as a popular architectural pattern. This architectural style enables teams to develop and deploy services independently, offering flexibility and scalability to the software developmentprocess.
To get a better understanding of AWS serverless, we’ll first explore the basics of serverless architectures, review AWS serverless offerings, and explore common use cases. Serverless architecture: A primer. Serverless architecture shifts application hosting functions away from local servers onto those managed by providers.
To take full advantage of the scalability, flexibility, and resilience of cloud platforms, organizations need to build or rearchitect applications around a cloud-native architecture. So, what is cloud-native architecture, exactly? What is cloud-native architecture? The principles of cloud-native architecture.
This process involves: Identifying Stakeholders: Determine who is impacted by the issue and whose input is crucial for a successful resolution. In this context, were focused on developing systems that ensure successful title launches, build trust between content creators and our brand, and reduce engineering operational overhead.
Observability agents are essential components in modern software development and operations. By efficiently capturing, processing, and transmitting logs, metrics, and traces, observability agents provide a comprehensive view of system health and behavior.
Transforming an application from monolith to microservices-based architecture can be daunting, and knowing where to start can be difficult. Unsurprisingly, organizations are breaking away from monolithic architectures and moving toward event-driven microservices. Understand the monolith Monolithic applications take work to understand.
This decoupling is crucial in modern architectures where scalability and fault tolerance are paramount. The architecture of RabbitMQ is meticulously designed for complex message routing, enabling dynamic and flexible interactions between producers and consumers. Erlang is the backbone of RabbitMQ clustering.
As businesses take steps to innovate faster, software development quality—and application security—have moved front and center. Indeed, according to one survey, DevOps practices have led to 60% of developers releasing code twice as quickly. It does so by creating repeatable, automated software-driven processes.
Trace your application Imagine a microservices architecture with hundreds of dependencies. This architecture also means you’re not required to determine your log data use cases beforehand or while analyzing logs within the new logs app. Interact with data intuitively and easily and benefit from immediate, AI-supported insights.
As dynamic systems architectures increase in complexity and scale, IT teams face mounting pressure to track and respond to conditions and issues across their multi-cloud environments. An advanced observability solution can also be used to automate more processes, increasing efficiency and innovation among Ops and Apps teams.
Microservices architecture is a software development approach that structures an application as a collection of small, independent services, each running in its own process and communicating with lightweight mechanisms, such as APIs.
To this end, we developed a Rapid Event Notification System (RENO) to support use cases that require server initiated communication with devices in a scalable and extensible manner. We thus assigned a priority to each use case and sharded event traffic by routing to priority-specific queues and the corresponding event processing clusters.
Building scalable systems using microservices architecture is a strategic approach to developing complex applications. This step-by-step guide outlines the process of creating a microservices-based system, complete with detailed examples.
The Astronomy Shop demo application , which has been actively developed since 2022, solves this problem, and Dynatrace is one of its leading contributors. Because it includes examples of 10 programming languages that OpenTelemetry supports with SDKs, the application makes a good reference for developers on how to use OpenTelemetry.
DevSecOps is a cross-team collaboration framework that integrates security into DevOps processes from the start rather than waiting to address security in a separate silo. With an integrated DevSecOps approach, organizations can reduce security risk without derailing development timelines. Development. What is DevSecOps?
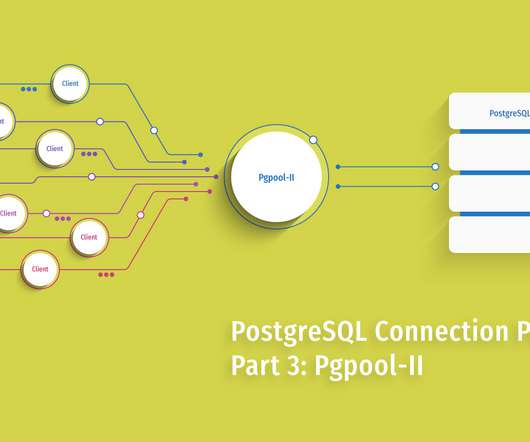
Check out the Pgpool-II architecture that supports all of its features, and learn how the connection pooler works. Pgpool-II has a more involved architecture than PgBouncer in order to support all the features it does. The Pgpool-II parent process forks 32 child processes by default – these are available for connection.
Our Journey so Far Over the past year, we’ve implemented the core infrastructure pieces necessary for a federated GraphQL architecture as described in our previous post: Studio Edge Architecture The first Domain Graph Service (DGS) on the platform was the former GraphQL monolith that we discussed in our first post (Studio API).
Specifically, we will dive into the architecture that powers search capabilities for studio applications at Netflix. We implemented a batch processing system for users to submit their requests and wait for the system to generate the output. Processing took several hours to complete. Here is a visualization of this flow.
Observability as a topic is becoming more important as applications are using microservice architectures and are deployed in Kubernetes environments. Davis not only identified the garbage collection as the root-cause, but pointed me to the specific process causing the trouble. Dynatrace news. The service flow . Conclusion.
Site reliability engineering (SRE) is the practice of applying software engineering principles to operations and infrastructure processes to help organizations create highly reliable and scalable software systems. SRE applies DevOps principles to developing systems and software that help increase site reliability and performance.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content