This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This article outlines the key differences in architecture, performance, and use cases to help determine the best fit for your workload. RabbitMQ follows a message broker model with advanced routing, while Kafkas event streaming architecture uses partitioned logs for distributed processing. What is RabbitMQ? What is Apache Kafka?
“Latency” is the duration from the execution of a load instruction (to an address that misses in all the caches), and the completion of that load instruction when the data is returned from memory. The example below is for a 2005-era processor with 60 ns memory latency and 6.4 cache lines -> 5.6 cache lines -> 5.6
With the rise of microservices architecture , there has been a rapid acceleration in the modernization of legacy platforms, leveraging cloud infrastructure to deliver highly scalable, low-latency, and more responsive services. Traditional blocking architectures often struggle to keep up performance, especially under high load.
Timestone: Netflix’s High-Throughput, Low-Latency Priority Queueing System with Built-in Support for Non-Parallelizable Workloads by Kostas Christidis Introduction Timestone is a high-throughput, low-latency priority queueing system we built in-house to support the needs of Cosmos , our media encoding platform. Over the past 2.5
This scenario underscored the need for a new recommender system architecture where member preference learning is centralized, enhancing accessibility and utility across different models. Yet, many are confined to a brief temporal window due to constraints in serving latency or training costs.
Leveraging this hierarchical structure can significantly reduce latency and improve overall performance. Multi-layered caching involves using multiple levels of cache to store and retrieve data.
This decoupling is crucial in modern architectures where scalability and fault tolerance are paramount. The architecture of RabbitMQ is meticulously designed for complex message routing, enabling dynamic and flexible interactions between producers and consumers. Keeping queues short maintains a responsive and efficient RabbitMQ setup.
Firstly, developers struggled to reason about consistency, durability and performance in this complex global deployment across multiple stores. Second, developers had to constantly re-learn new data modeling practices and common yet critical data access patterns.
The service should be able to serve real-time, aka UI, applications so CRUD and search operations should be achieved with low latency. Our service will be used by a lot of internal UI applications hence the latency for CRUD and search operations must be low. Search latency for the generic text queries are in milliseconds.
DigitalOcean is a cost-effective cloud provider that caters to, and is widely adopted by the developer community. Compare Latency. lower latency compared to DigitalOcean for PostgreSQL. Now, let’s take a look at the throughput and latency performance of our comparison. At a glance – TLDR. Compare Throughput.
As more organizations embrace microservices-based architecture to deliver goods and services digitally, maintaining customer satisfaction has become exponentially more challenging. When organizations implement SLOs, they can improve software development processes and application performance. SLOs improve software quality. Reliability.
Trace your application Imagine a microservices architecture with hundreds of dependencies. Without distributed tracing, pinpointing the cause of increased latency could take hours or even days. Collaborating with your peers based on your software development lifecycle and all data in context has never been easier.
The new Amazon capability enables customers to improve the startup latency of their functions from several seconds to as low as sub-second (up to 10 times faster) at P99 (the 99th latency percentile). This can cause latency outliers and may lead to a poor end-user experience for latency-sensitive applications.
Organizations have multiple stakeholders and almost always have different teams that set up monitoring, operate systems, and develop new functionality. Example 1: Architecture boundaries. First, they took a big step back and looked at their end-to-end architecture (Figure 2). SLO dashboard defined by architectural boundary.
Code development also benefits from a serverless approach. Application developers can spin up isolated test environments that pose no risk to current operations. Reduced latency. Serverless architecture makes it possible to host code anywhere, rather than relying on an origin server. Architectural complexity.
As a discipline, SRE focuses on improving software system reliability across key categories including availability, performance, latency, efficiency, capacity, and incident response. SRE applies DevOps principles to developing systems and software that help increase site reliability and performance. Solving for SR.
Stream processing One approach to such a challenging scenario is stream processing, a computing paradigm and software architectural style for data-intensive software systems that emerged to cope with requirements for near real-time processing of massive amounts of data. This significantly increases event latency.
It supports both high throughput services that consume hundreds of thousands of CPUs at a time, and latency-sensitive workloads where humans are waiting for the results of a computation. Local development tools including specialized test runners, code generators, and a command line interface. Modularity?—?An Productivity?—?Local
Within this paradigm, it is possible to run entire architectures without touching a traditional virtual server, either locally or in the cloud. In a serverless architecture, applications are distributed to meet demand and scale requirements efficiently. When an application is triggered, it can cause latency as the application starts.
This architecture shift greatly reduced the processing latency and increased system resiliency. We expanded pipeline support to serve our studio/content-development use cases, which had different latency and resiliency requirements as compared to the traditional streaming use case.
In that environment, the first PostgreSQL developers decided forking a process for each connection to the database is the safest choice. Moving to a multithreaded architecture will require extensive rewrites. Developers are often strongly discouraged from holding a database connection while other operations take place.
As dynamic systems architectures increase in complexity and scale, IT teams face mounting pressure to track and respond to conditions and issues across their multi-cloud environments. The architects and developers who create the software must design it to be observed. Dynatrace news.
As a discipline, SRE focuses on improving software system reliability across key categories including availability, performance, latency, efficiency, capacity, and incident response. SRE applies DevOps principles to developing systems and software that help increase site reliability and performance. Solving for SR.
Table 1: Movie and File Size Examples Initial Architecture A simplified view of our initial cloud video processing pipeline is illustrated in the following diagram. Figure 1: A Simplified Video Processing Pipeline With this architecture, chunk encoding is very efficient and processed in distributed cloud computing instances.
Because of its scalability and distributed architecture, thousands of companies trust it to run their cloud and hybrid-based workloads at high availability without compromising performance. It also removes the need for developers and database administrators to manage infrastructure or update database versions.
To this end, we developed a Rapid Event Notification System (RENO) to support use cases that require server initiated communication with devices in a scalable and extensible manner. Architecture As shown in the diagram above, the RENO service can be broken down into the following components.
Rajiv Shringi Vinay Chella Kaidan Fullerton Oleksii Tkachuk Joey Lynch Introduction As Netflix continues to expand and diversify into various sectors like Video on Demand and Gaming , the ability to ingest and store vast amounts of temporal data — often reaching petabytes — with millisecond access latency has become increasingly vital.
How we migrated our Android endpoints out of a monolith into a new microservice by Rohan Dhruva , Ed Ballot As Android developers, we usually have the luxury of treating our backends as magic boxes running in the cloud, faithfully returning us JSON. It was a Node.js Java…Script? The context around why the Node.js
These include website hosting, database management, backup and restore, IoT capabilities, e-commerce solutions, app development tools and more, with new services released regularly. Lambda’s toolbox of automated processes helps developers streamline to build fast, robust, and scalable applications on accelerated timelines.
Retrieval-augmented generation emerges as the standard architecture for LLM-based applications Given that LLMs can generate factually incorrect or nonsensical responses, retrieval-augmented generation (RAG) has emerged as an industry standard for building GenAI applications.
Observability gives developers and system operators real-time awareness of a highly distributed system’s current state based on the data it generates. Metrics are measures of critical system values, such as CPU utilization or average write latency to persistent storage. What is observability?
Currently, he is in the Alexa Shopping organization where he is developing machine-learning-based solutions to send personalized reorder hints to customers for improving their experience. Architecture. When a user requests for feed then there will be two parallel threads involved in fetching the user feeds to optimize for latency.
Today we are excited to announce latency heatmaps and improved container support for our on-host monitoring solution?—?Vector?—?to Remotely view real-time process scheduler latency and tcp throughput with Vector and eBPF What is Vector? to the broader community. Vector is open source and in use by multiple companies.
The practice uses continuous monitoring and high levels of automation in close collaboration with agile development teams to ensure applications are highly available and perform without friction. Microservices-based architectures and software containers enable organizations to deploy and modify applications with unprecedented speed.
Dynatrace enables various teams, such as developers, threat hunters, business analysts, and DevOps, to effortlessly consume advanced log insights within a single platform. This architecture also means you are not required to determine your log data use cases beforehand or while analyzing logs within the new logs app.
by AIM Team Members Karen Casella , Travis Nelson , Sunny Singh ; with prior art and contributions by Justin Ryan , Satyajit Thadeshwar As most developers can attest, dealing with security protocols and identity tokens, as well as user and device authentication, can be challenging. We are serving over 2.5
High Level Architecture The idea, at a high level, was to avoid the need to query the Atlas database almost entirely and transition most alert queries to streaming evaluation. First and foremost, we have successfully alleviated our initial scalability problem with the polling based architecture. OK, Results?
While this abundance of dashboards and information is by no means unique to Netflix, it certainly holds true within our microservices architecture. Telltale provides Edgar with latency benchmarks that indicate if the individual trace’s latency is abnormal for this given service.
With Configuration as Code, developers can manage their observability and security tasks with config files that can be developed alongside source code conveniently and at scale. As software development grows more complex, managing components using an automated onboarding process becomes increasingly important.
Because Google offers its own Google Cloud Architecture Framework and Microsoft its Azure Well-Architected Framework , organizations that use a combination of these platforms triple the challenge of integrating their performance frameworks into a cohesive strategy. SRG validates the status of the resiliency SLOs for the experiment period.
As organizations adopt microservices-based architecture , service-level objectives (SLOs) have become a vital way for teams to set specific, measurable targets that ensure users are receiving agreed-upon service levels. Properly set and defined SLOs should have error budgets that give developers space to innovate without impacting operations.
Today, I want to explore the Amazon ECS architecture and what this architecture enables. This architecture affords Amazon ECS high availability, low latency, and high throughput because the data store is never pessimistically locked. Below is a diagram of the basic components of Amazon ECS: How we coordinate the cluster.
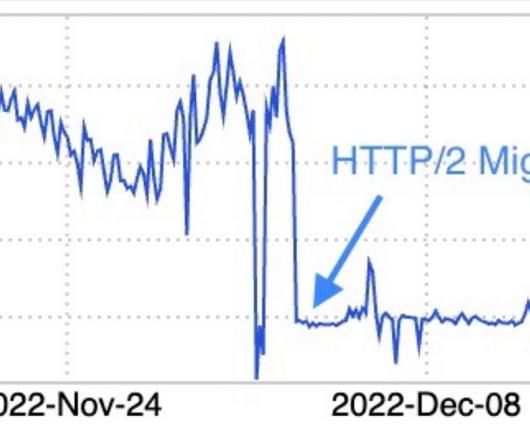
to HTTP2, resulting in a reduction in the number of connections, latency, and garbage collection times. LinkedIn was able to dramatically improve the scalability and performance of its Espresso database by migrating it from HTTP1.1 To achieve these gains, the team had to optimize the Netty’s default HTTP2 stack to make it fit their needs.
At Netflix, we also heavily embrace a microservice architecture that emphasizes separation of concerns. The data warehouse is not designed to serve point requests from microservices with low latency. Therefore, we must efficiently move data from the data warehouse to a global, low-latency and highly-reliable key-value store.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content