This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Design a photo-sharing platform similar to Instagram where users can upload their photos and share it with their followers. High Level Design. Architecture. Component Design. API Design. We have provided the API design of posting an image on Instagram below. API Design. Problem Statement. Data Models.
RabbitMQ is designed for flexible routing and message reliability, while Kafka handles high-throughput event streaming and real-time data processing. This article outlines the key differences in architecture, performance, and use cases to help determine the best fit for your workload. What is RabbitMQ? What is Apache Kafka?
By: Rajiv Shringi , Oleksii Tkachuk , Kartik Sathyanarayanan Introduction In our previous blog post, we introduced Netflix’s TimeSeries Abstraction , a distributed service designed to store and query large volumes of temporal event data with low millisecond latencies. Today, we’re excited to present the Distributed Counter Abstraction.
This scenario underscored the need for a new recommender system architecture where member preference learning is centralized, enhancing accessibility and utility across different models. Yet, many are confined to a brief temporal window due to constraints in serving latency or training costs.
With the rise of microservices architecture , there has been a rapid acceleration in the modernization of legacy platforms, leveraging cloud infrastructure to deliver highly scalable, low-latency, and more responsive services. Traditional blocking architectures often struggle to keep up performance, especially under high load.
Timestone: Netflix’s High-Throughput, Low-Latency Priority Queueing System with Built-in Support for Non-Parallelizable Workloads by Kostas Christidis Introduction Timestone is a high-throughput, low-latency priority queueing system we built in-house to support the needs of Cosmos , our media encoding platform. Over the past 2.5
This decoupling is crucial in modern architectures where scalability and fault tolerance are paramount. The architecture of RabbitMQ is meticulously designed for complex message routing, enabling dynamic and flexible interactions between producers and consumers.
Remote calls are never free; they impose extra latency, increase probability of an error, and consume network bandwidth. How can we achieve a similar functionality when designing our gRPC APIs? When we process a request it is often beneficial to know which fields the caller is interested in and which ones they ignore.
The service should be able to serve real-time, aka UI, applications so CRUD and search operations should be achieved with low latency. Our service will be used by a lot of internal UI applications hence the latency for CRUD and search operations must be low. Search latency for the generic text queries are in milliseconds.
These include challenges with tail latency and idempotency, managing “wide” partitions with many rows, handling single large “fat” columns, and slow response pagination. Data Model At its core, the KV abstraction is built around a two-level map architecture.
Motivation With the rapid growth in Netflix member base and the increasing complexity of our systems, our architecture has evolved into an asynchronous one that enables both online and offline computation. Architecture As shown in the diagram above, the RENO service can be broken down into the following components.
Stream processing One approach to such a challenging scenario is stream processing, a computing paradigm and software architectural style for data-intensive software systems that emerged to cope with requirements for near real-time processing of massive amounts of data. We designed experimental scenarios inspired by chaos engineering.
Table 1: Movie and File Size Examples Initial Architecture A simplified view of our initial cloud video processing pipeline is illustrated in the following diagram. Figure 1: A Simplified Video Processing Pipeline With this architecture, chunk encoding is very efficient and processed in distributed cloud computing instances.
Our approach to NN-based video downscaling The deep downscaler is a neural network architecturedesigned to improve the end-to-end video quality by learning a higher-quality video downscaler. We employed an adaptive network design that is applicable to the wide variety of resolutions we use for encoding.
Rajiv Shringi Vinay Chella Kaidan Fullerton Oleksii Tkachuk Joey Lynch Introduction As Netflix continues to expand and diversify into various sectors like Video on Demand and Gaming , the ability to ingest and store vast amounts of temporal data — often reaching petabytes — with millisecond access latency has become increasingly vital.
As dynamic systems architectures increase in complexity and scale, IT teams face mounting pressure to track and respond to conditions and issues across their multi-cloud environments. The architects and developers who create the software must design it to be observed. Dynatrace news. Benefits of observability.
Retrieval-augmented generation emerges as the standard architecture for LLM-based applications Given that LLMs can generate factually incorrect or nonsensical responses, retrieval-augmented generation (RAG) has emerged as an industry standard for building GenAI applications.
We designed a unique concept called Annotation Operations which allows teams to create data pipelines and easily write annotations without worrying about access patterns of their data from different applications. But we cannot search or present low latency retrievals from files Etc.
Allegro experimented with different performance optimization options to improve Apache Kafka producer tail latency and eventually switched all its clusters to the XFS filesystem. The company used Kafka protocol sniffing, JVM profiling, and eBPF, which proved instrumental in identifying and eliminating performance bottlenecks.
The original assumptions and architectural choices were no longer viable. Overview The figure below depicts a simplified high-level architecture of a single Titus cluster (a.k.a We started seeing increased response latencies and leader servers running at dangerously high utilization.
We tried a few iterations of what this new service should look like, and eventually settled on a modern architecture that aimed to give more control of the API experience to the client teams. For us, it means that we now need to have ~15 MDN tabs open when writing routes :) Let’s briefly discuss the architecture of this microservice.
This architecture shift greatly reduced the processing latency and increased system resiliency. We expanded pipeline support to serve our studio/content-development use cases, which had different latency and resiliency requirements as compared to the traditional streaming use case.
It supports both high throughput services that consume hundreds of thousands of CPUs at a time, and latency-sensitive workloads where humans are waiting for the results of a computation. The subsystems all communicate with each other asynchronously via Timestone, a high-scale, low-latency priority queuing system.
Because microprocessors are so fast, computer architecturedesign has evolved towards adding various levels of caching between compute units and the main memory, in order to hide the latency of bringing the bits to the brains. This avoids thrashing caches too much for B and evens out the pressure on the L3 caches of the machine.
Lambda’s highly efficient, on-demand computing environment aligns with today’s microservices-centric architectures, and readily integrates with other popular AWS offerings that an organization may already be using. AWS continues to improve how it handles latency issues. It helps SRE teams automate responses.
While data lakes and data warehousing architectures are commonly used modes for storing and analyzing data, a data lakehouse is an efficient third way to store and analyze data that unifies the two architectures while preserving the benefits of both. Data lakehouses deliver the query response with minimal latency.
a Fast and Scalable NoSQL Database Service Designed for Internet Scale Applications. Today is a very exciting day as we release Amazon DynamoDB , a fast, highly reliable and cost-effective NoSQL database service designed for internet scale applications. Amazon DynamoDB offers low, predictable latencies at any scale. Comments ().
Today we have a wealth of tools, both OSS and commercial, all designed for cloud-native environments. To improve availability, we designed systems where components could fail separately and avoid single points of failure. There is a downside to fetching this data on-demand: this adds latency to the first request to a cluster.
Plus, the architecture of the Edge tier was evolving to a PaaS (platform as a service) model, and we had some tough decisions to make about how, and where, to handle identity token handling. The system architecture now takes the form of: Notice that tokens never traverse past the Edge gateway / EAS boundary. We are serving over 2.5
At Netflix, we also heavily embrace a microservice architecture that emphasizes separation of concerns. The data warehouse is not designed to serve point requests from microservices with low latency. Therefore, we must efficiently move data from the data warehouse to a global, low-latency and highly-reliable key-value store.
This is a set of best practices and guidelines that help you design and operate reliable, secure, efficient, cost-effective, and sustainable systems in the cloud. If you use AWS cloud services to build and run your applications, you may be familiar with the AWS Well-Architected framework.
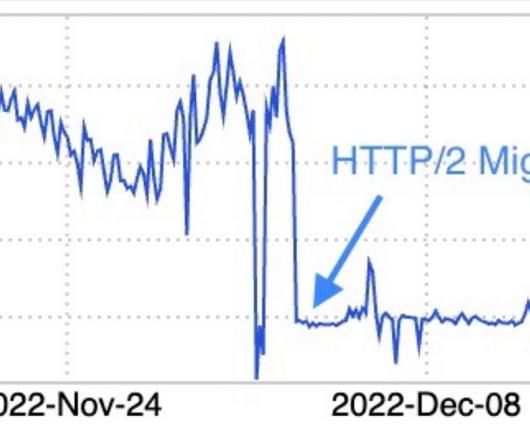
to HTTP2, resulting in a reduction in the number of connections, latency, and garbage collection times. LinkedIn was able to dramatically improve the scalability and performance of its Espresso database by migrating it from HTTP1.1 To achieve these gains, the team had to optimize the Netty’s default HTTP2 stack to make it fit their needs.
For example, when we design a new version of VMAF, we need to effectively roll it out throughout the entire Netflix catalog of movies and TV shows. This article explains how we designed microservices and workflows on top of the Cosmos platform to bolster such video quality innovations. via bug fixes). We call this system Cosmos.
System Setup Architecture The following diagram summarizes the architecture description: Figure 1: Event-sourcing architecture of the Device Management Platform. By the following morning, alerts were received regarding high memory consumption and GC latencies, to the point where the service was unresponsive to HTTP requests.
Today, I want to explore the Amazon ECS architecture and what this architecture enables. This architecture affords Amazon ECS high availability, low latency, and high throughput because the data store is never pessimistically locked. Below is a diagram of the basic components of Amazon ECS: How we coordinate the cluster.
This article will list some of the use cases of AutoOptimize, discuss the design principles that help enhance efficiency, and present the high-level architecture. These principles reduce resource usage by being more efficient and effective while lowering the end-to-end latency in data processing. Transparency to end-users.
By bringing computation closer to the data source, edge-based deployments reduce latency, enhance real-time capabilities, and optimize network bandwidth. Increased latency during peak loads. Introduce scalable microservices architectures to distribute computational loads efficiently.
ITOps refers to the process of acquiring, designing, deploying, configuring, and maintaining equipment and services that support an organization’s desired business outcomes. This includes response time, accuracy, speed, throughput, uptime, CPU utilization, and latency. Performance. What does IT operations do?
As organizations adopt microservices-based architecture , service-level objectives (SLOs) have become a vital way for teams to set specific, measurable targets that ensure users are receiving agreed-upon service levels. You can set SLOs based on individual indicators, such as batch throughput, request latency, and failures-per-second.
RISELabs , those wonderfully innovative folks over at Berkeley, have uplifted their Anna datatabase —a shared-nothing, thread-per-core architecture to achieve lightning-fast speeds by avoiding all coordination mechanisms—to become cloud-aware. While database neogenesis has slowed down considerably, it has not gone necrotic.
By collecting and analyzing key performance metrics of the service over time, we can assess the impact of the new changes and determine if they meet the availability, latency, and performance requirements. A/B testing is also a key technique in migrations where the updates to the architecture involve changing device contracts as well.
In the future posts, we will do an architectural deep dive into the several components of Netflix Drive. Fig 3: POSIX interface of Netflix Drive The POSIX files and folders interface for Netflix Drive is designed as a layered system with the FUSE implementation hooks forming the top layer.
Building general purpose architectures has always been hard; there are often so many conflicting requirements that you cannot derive an architecture that will serve all, so we have often ended up focusing on one side of the requirements that allow you to serve that area really well.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content