This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Machine Learning Engineer at Amazon and has led several machine-learning initiatives across the Amazon ecosystem. Design a photo-sharing platform similar to Instagram where users can upload their photos and share it with their followers. High Level Design. Architecture. Component Design. API Design.
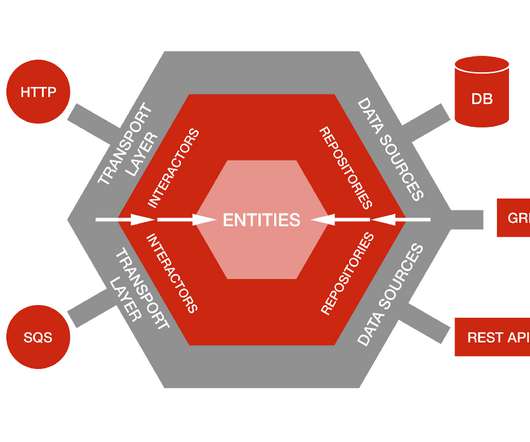
Our wider Studio Engineering Organization has built more than 30 apps that help content progress from pitch (aka screenplay) to playback: ranging from script content acquisition, deal negotiations and vendor management to scheduling, streamlining production workflows, and so on. The dependency graph in Hexagonal Architecture goes inward.
Part 3: System Strategies and Architecture By: VarunKhaitan With special thanks to my stunning colleagues: Mallika Rao , Esmir Mesic , HugoMarques This blog post is a continuation of Part 2 , where we cleared the ambiguity around title launch observability at Netflix. The request schema for the observability endpoint.
Building the dream package Observability for Developers, the newly introduced offering from Dynatrace, is designed to cater to developers’ specific needs and challenges. Additionally, Dynatrace integrates relevant trace data, providing full visibility into complex, microservices-based architectures.
Many organizations are taking a microservices approach to IT architecture. However, in some cases, an organization may be better suited to another architecture approach. Therefore, it’s critical to weigh the advantages of microservices against its potential issues, other architecture approaches, and your unique business needs.
As cloud-native, distributed architectures proliferate, the need for DevOps technologies and DevOps platform engineers has increased as well. DevOps engineer tools can help ease the pressure as environment complexity grows. ” What does a DevOps platform engineer do? .”
Challenge: Dont understand the cascading effects of their setup on these perceived black box personalization systems - Personalization System Engineers Role: Develop and operate the personalization systems. Up next In the next iteration we will talk about how to design an observability endpoint that works for all personalization systems.
Stream processing One approach to such a challenging scenario is stream processing, a computing paradigm and software architectural style for data-intensive software systems that emerged to cope with requirements for near real-time processing of massive amounts of data. We designed experimental scenarios inspired by chaos engineering.
This is article was written by Dirceu Pereira Tiegs, Site Reliability Engineer at Auth0, and originally was originally published in Auth0. We designed Auth0 from the beginning so that it could run anywhere: on our cloud, on your cloud, or even on your own private infrastructure. Core service architecture.
By Alex Hutter , Falguni Jhaveri and Senthil Sayeebaba Over the past few years Content Engineering at Netflix has been transitioning many of its services to use a federated GraphQL platform. In a federated graph architecture, how can we answer such a query given that each entity is served by its own service?
A summary of sessions at the first Data Engineering Open Forum at Netflix on April 18th, 2024 The Data Engineering Open Forum at Netflix on April 18th, 2024. At Netflix, we aspire to entertain the world, and our data engineering teams play a crucial role in this mission by enabling data-driven decision-making at scale.
Site reliability engineering (SRE) has become increasingly important to organizations looking to keep up with the rapid pace of digital transformation. Effective site reliability engineering requires enterprise-wide transformation Without a unified understanding of SRE practices, organizational silos can quickly form between departments.
By Abhinaya Shetty , Bharath Mummadisetty At Netflix, our Membership and Finance Data Engineering team harnesses diverse data related to plans, pricing, membership life cycle, and revenue to fuel analytics, power various dashboards, and make data-informed decisions. Our audits would detect this and alert the on-call data engineer (DE).
In this blog post, we explain what Greenplum is, and break down the Greenplum architecture, advantages, major use cases, and how to get started. It’s architecture was specially designed to manage large-scale data warehouses and business intelligence workloads by giving you the ability to spread your data out across a multitude of servers.
Following are some of the coolest things weve seen engineers do with Live Debugger. With Live Debugger, you can see the precise inputs called your by code in production so you can design your tests accordingly. Performance benchmarking Performance benchmarking is one of the unresolved mysteries of software engineering.
How can we achieve a similar functionality when designing our gRPC APIs? The solution we use within the Netflix Studio Engineering is protobuf FieldMask. This blog post covered how and why it is used at Netflix Studio Engineering for APIs that read the data.
The reality of the startup is that engineering teams are often at a crossroads when it comes to choosing the foundational architecture for their software applications. The allure of a microservice architecture is understandable in today's tech state of affairs, where scalability, flexibility, and independence are highly valued.
By Ricky Gardiner , Alex Borysov Background In our previous post , we discussed how we utilize FieldMask as a solution when designing our APIs so that consumers can request the data they need when fetched via gRPC. API designers should aim for simplicity, but make their APIs open for extension and evolution.
To get a better understanding of AWS serverless, we’ll first explore the basics of serverless architectures, review AWS serverless offerings, and explore common use cases. Serverless architecture: A primer. Serverless architecture shifts application hosting functions away from local servers onto those managed by providers.
Motivation With the rapid growth in Netflix member base and the increasing complexity of our systems, our architecture has evolved into an asynchronous one that enables both online and offline computation. Personalized Experience Refresh Netflix Recommendation engine continuously refreshes recommendations for every member.
Our Journey so Far Over the past year, we’ve implemented the core infrastructure pieces necessary for a federated GraphQL architecture as described in our previous post: Studio Edge Architecture The first Domain Graph Service (DGS) on the platform was the former GraphQL monolith that we discussed in our first post (Studio API).
Growth Engineering at Netflix?—?Automated In the Growth Engineering team, we refer to this as the top of the signup funnel. For more background on the signup funnel and Growth Engineering’s role in the signup funnel, please read our initial post on the topic: Growth Engineering at Netflix? Accelerating Innovation.
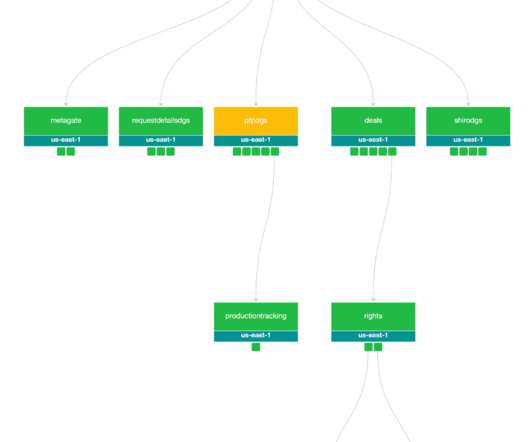
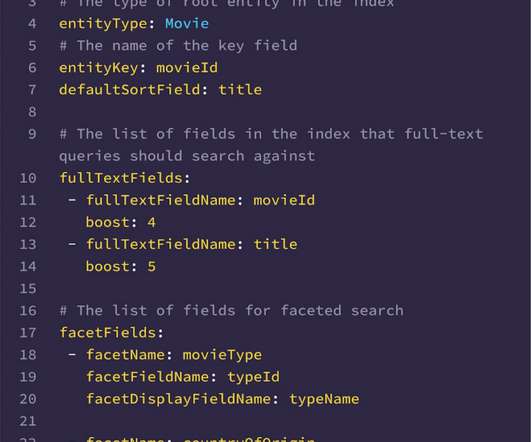
By Alex Hutter , Falguni Jhaveri , and Senthil Sayeebaba In a previous post , we described the indexing architecture of Studio Search and how we scaled the architecture by building a config-driven self-service platform that allowed teams in Content Engineering to spin up search indices easily.
The Growth Engineering team is responsible for executing growth initiatives that help us anticipate and adapt to this change. In particular, it’s our job to design and build the systems and protocols that enable customers from all over the world to sign up for Netflix with the plan features and incentives that best suit their needs.
The fact is, Reliability and Resiliency must be rooted in the architecture of a distributed system. The email walked through how our Dynatrace self-monitoring notified users of the outage but automatically remediated the problem thanks to our platform’s architecture. Let me start with the end-user impact.
This scenario underscored the need for a new recommender system architecture where member preference learning is centralized, enhancing accessibility and utility across different models. Furthermore, it was difficult to transfer innovations from one model to another, given that most are independently trained despite using common data sources.
Our approach to NN-based video downscaling The deep downscaler is a neural network architecturedesigned to improve the end-to-end video quality by learning a higher-quality video downscaler. We employed an adaptive network design that is applicable to the wide variety of resolutions we use for encoding.
Specifically, we will dive into the architecture that powers search capabilities for studio applications at Netflix. Dawn Chenette , Design Lead This approach had several benefits for product engineering. At the same time we experienced growing engineering pains that limited our ability to scale. Incredible!”
Site reliability engineering (SRE) continues to gain popularity as organizations embrace hybrid cloud strategies and IT automation at scale. By applying software engineering principles to operations and infrastructure practices, SRE enables organizations to streamline and automate IT processes. Dynatrace news.
This decoupling is crucial in modern architectures where scalability and fault tolerance are paramount. The architecture of RabbitMQ is meticulously designed for complex message routing, enabling dynamic and flexible interactions between producers and consumers.
We look here at a Gedankenexperiment: move 16 bytes per cycle , addressing not just the CPU movement, but also the surrounding system design. A lesser design cannot possibly move 16 bytes per cycle. This base design can map easily onto many current chips. Thought Experiment. bytes remaining to move. Longer Prefetching matters.
We’re delighted to share that IBM and Dynatrace have joined forces to bring the Dynatrace Operator, along with the comprehensive capabilities of the Dynatrace platform, to Red Hat OpenShift on the IBM Power architecture (ppc64le).
In this article, we discuss the concepts of dependability and fault tolerance in detail and explain how the Ably platform is designed with fault tolerant approaches to uphold its dependability guarantees. Fault tolerant design approaches address these shortfalls to provide continuity both to business and to the user experience.
Experienced engineers used Perl scripts, vi, grep and awk to make log searches more efficient. These historical approaches worked for a different era of software applications: ones more monolithic in design, changing relatively infrequently (once every few weeks or months) and with only a handful of log types to monitor.
Simpler UI Testing with CasperJS ( Architects Zone – ArchitecturalDesign Patterns & Best Practices). Using MongoDB as a cache store ( Architects Zone – ArchitecturalDesign Patterns & Best Practices). Why haven’t cash-strapped American schools embraced open source? Hacker News).
Grail architectural basics. The aforementioned principles have, of course, a major impact on the overall architecture. A data lakehouse addresses these limitations and introduces an entirely new architecturaldesign. It’s based on cloud-native architecture and built for the cloud. But what does that mean?
Now, imagine yourself in the role of a software engineer responsible for a micro-service which publishes data consumed by few critical customer facing services (e.g. You are about to make structural changes to the data and want to know who and what downstream to your service will be impacted.
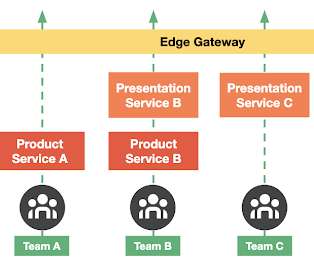
In October 2014, Uber had started its journey of scale in what … The post Designing Edge Gateway, Uber’s API Lifecycle Management Platform appeared first on Uber Engineering Blog. Evolution of Uber’s API gateway.
Performance testing is mainly a subset of Performance engineering and is also referred to as ' Perf Tests.' It is almost a part of the wider performance engineering portrait, concentrating on performance glitches in the architecture and design of any software.
As we did with IBM Power , we’re delighted to share that IBM and Dynatrace have joined forces to bring the Dynatrace Operator, along with the comprehensive capabilities of the Dynatrace platform, to Red Hat OpenShift on the IBM Z and LinuxONE architecture (s390x). Dynatrace is designed to scale easily across the entire Kubernetes stack.
Observability as a topic is becoming more important as applications are using microservice architectures and are deployed in Kubernetes environments. Shortly after applying the heavy load, Davis, the Dynatrace AI engine, notified me of a problem. Dynatrace news. The setup . The service flow . Conclusion.
The goal was to develop a custom solution that enables DevOps and engineering teams to analyze and improve pipeline performance issues and alert on health metrics across CI/CD platforms. Faced with these requirements, Omnilogy carefully evaluated the following two options for implementing a solution to the pipeline observability challenge.
As organizations plan, migrate, transform, and operate their workloads on AWS, it’s vital that they follow a consistent approach to evaluating both the on-premises architecture and the upcoming design for cloud-based architecture. these metrics are also automatically analyzed by Dynatrace’s AI engine, Davis ).
Evaluating these on three levels—data center, host, and application architecture (plus code)—is helpful. Options at each level offer significant potential benefits, especially when complemented by practices that influence the design and purchase decisions made by IT leaders and individual contributors.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content