This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This year’s AWS re:Invent will showcase a suite of new AWS and Dynatrace integrations designed to enhance cloud performance, security, and automation. These innovations promise to streamline operations, boost efficiency, and offer deeper insights for enterprises using AWS services.
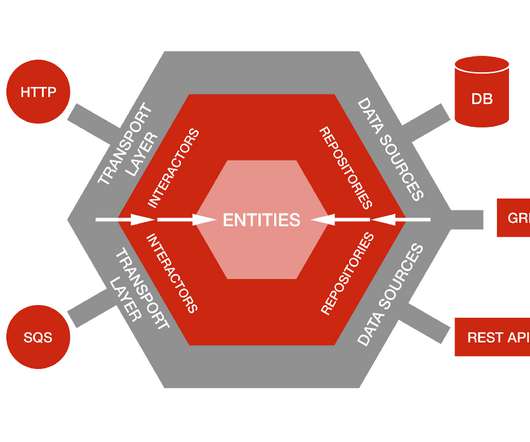
by Damir Svrtan and Sergii Makagon As the production of Netflix Originals grows each year, so does our need to build apps that enable efficiency throughout the entire creative process. We decided to build our app based on principles behind Hexagonal Architecture and Uncle Bob’s Clean Architecture.
In the landscape of computer architecture, two prominent paradigms shape the realm of parallel processing: SIMD (Single Instruction, Multiple Data) and MIMD (Multiple Instruction, Multiple Data) architectures. This approach enables efficient processing of large datasets by applying the same operation to multiple elements concurrently.
Protect data in multi-tenant architectures To bring you the most value by unifying observability and security in one analytics and automation platform powered by AI, Dynatrace SaaS leverages a multitenancy architecture, enabling efficient and scalable data ingestion, querying, and processing on shared infrastructure.
To create a CPU core that can execute a large number of instructions in parallel, it is necessary to improve both the architecturewhich includes the overall CPU design and the instruction set architecture (ISA) designand the microarchitecture, which refers to the hardware design that optimizes instruction execution.
This article will explore the concept of multi-layered caching from both architectural and development perspectives, focusing on real-world applications like Instagram, and provide insights into designing and implementing an efficient multi-layered cache system.
It is designed for simplicity and cost-efficiency. Grafana Loki is a horizontally scalable, highly available log aggregation system. Created by Grafana Labs in 2018, Loki has rapidly emerged as a compelling alternative to traditional logging systems, particularly for cloud-native and Kubernetes environments.
In the world of cloud computing and event-driven applications, efficiency and flexibility are absolute necessities. A proper architecture ensures that there are no bottlenecks in the movement of messages. A smooth flow of messages in an event-driven application is the key to its performance and efficiency.
RabbitMQ is designed for flexible routing and message reliability, while Kafka handles high-throughput event streaming and real-time data processing. This article outlines the key differences in architecture, performance, and use cases to help determine the best fit for your workload. What is RabbitMQ? What is Apache Kafka?
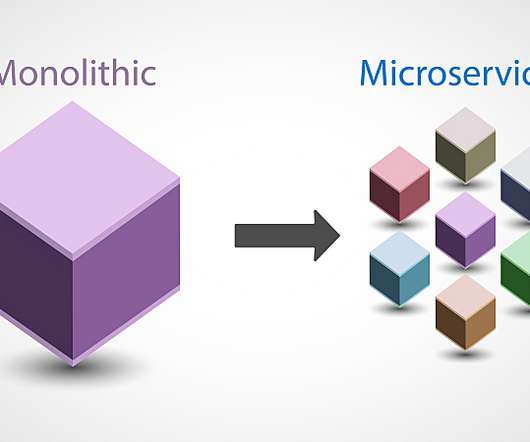
As a result, organizations are weighing microservices vs. monolithic architecture to improve software delivery speed and quality. Traditional monolithic architectures are built around the concept of large applications that are self-contained, independent, and incorporate myriad capabilities. What is monolithic architecture?
At financial services company, Soldo, efficiency and security by design are paramount goals. Since 2015, the Soldo business spend management platform has provided companies with a simple and efficient way to better spend and control company money. What is security by design?
A messaging system serves as a backbone, allowing information transmission between different services or modules in a distributed architecture. The cornerstone is a well-designed and painstakingly built messaging system, which allows for smooth communication and data exchange across diverse components.
In this blog post, we will see how Dynatrace harnesses the power of observability and analytics to tailor a new experience to easily extend to the left, allowing developers to solve issues faster, build more efficient software, and ultimately improve developer experience!
This scenario underscored the need for a new recommender system architecture where member preference learning is centralized, enhancing accessibility and utility across different models. At inference time, when multi-step decoding is needed, we can deploy KV caching to efficiently reuse past computations and maintain lowlatency.
Many organizations are taking a microservices approach to IT architecture. However, in some cases, an organization may be better suited to another architecture approach. Therefore, it’s critical to weigh the advantages of microservices against its potential issues, other architecture approaches, and your unique business needs.
Part 3: System Strategies and Architecture By: VarunKhaitan With special thanks to my stunning colleagues: Mallika Rao , Esmir Mesic , HugoMarques This blog post is a continuation of Part 2 , where we cleared the ambiguity around title launch observability at Netflix. The request schema for the observability endpoint.
It is reiterated that the positioning of this SLO includes the selection of strategic factors (entity positioning within the application architecture = ServiceFlow, sufficient traffic in requests per minute, etc). Contact Sales The post Efficient SLO event integration powers successful AIOps appeared first on Dynatrace news.
By: Rajiv Shringi , Oleksii Tkachuk , Kartik Sathyanarayanan Introduction In our previous blog post, we introduced Netflix’s TimeSeries Abstraction , a distributed service designed to store and query large volumes of temporal event data with low millisecond latencies. Today, we’re excited to present the Distributed Counter Abstraction.
This guide will cover how to distribute workloads across multiple nodes, set up efficient clustering, and implement robust load-balancing techniques. This decoupling is crucial in modern architectures where scalability and fault tolerance are paramount. This setup prioritizes data safety, with most replicas online at any given time.
How can we achieve a similar functionality when designing our gRPC APIs? Add FieldMask to the Request Message Instead of creating one-off “include” fields, API designers can add field_mask field to the request message: [link] Consumers can set paths for the fields they expect to receive in the response. Field names are not included.
Service-Oriented Architecture Overview. A service-oriented architecture (SOA) is an architectural pattern in computer software design in which application components provide services to other components via a communications protocol, typically over a network.
In this blog post, we explain what Greenplum is, and break down the Greenplum architecture, advantages, major use cases, and how to get started. It’s architecture was specially designed to manage large-scale data warehouses and business intelligence workloads by giving you the ability to spread your data out across a multitude of servers.
To get a better understanding of AWS serverless, we’ll first explore the basics of serverless architectures, review AWS serverless offerings, and explore common use cases. Serverless architecture: A primer. Serverless architecture shifts application hosting functions away from local servers onto those managed by providers.
While conventional video codecs remain prevalent, NN-based video encoding tools are flourishing and closing the performance gap in terms of compression efficiency. We employed an adaptive network design that is applicable to the wide variety of resolutions we use for encoding. How do we apply neural networks at scale efficiently?
We’re delighted to share that IBM and Dynatrace have joined forces to bring the Dynatrace Operator, along with the comprehensive capabilities of the Dynatrace platform, to Red Hat OpenShift on the IBM Power architecture (ppc64le).
In our experience, optimizing for operational efficiency requires answering one key question: for which tables does the maintenance cost supersede utility? Once identified, … The post Less is More: Engineering Data Warehouse Efficiency with Minimalist Design appeared first on Uber Engineering Blog.
One of our design principles is to make sure that Dynatrace is as easy to set up and use as possible. In short, over the last several months, we’ve completely rebuilt the architecture of the OneAgent installer for Windows. Dynatrace news. msi-based deployment. These aren’t just empty words.
As organizations increasingly migrate their applications to the cloud, efficient and scalable load balancing becomes pivotal for ensuring optimal performance and high availability. Load balancing is a critical component in cloud architectures for various reasons. What Is Load Balancing?
To take full advantage of the scalability, flexibility, and resilience of cloud platforms, organizations need to build or rearchitect applications around a cloud-native architecture. So, what is cloud-native architecture, exactly? What is cloud-native architecture? The principles of cloud-native architecture.
Scalable software architectures are the backbone of efficient and flexible production lines, enabling manufacturers to meet the increasing demands for innovative display technologies. As display manufacturing continues to evolve, the demand for scalable software solutions to support automation has become more critical than ever.
Cloud-native architecture has become a key concept in the software industry, providing an efficient way to develop, deploy, and manage applications in the cloud. As more and more applications are moved to the cloud, it becomes increasingly important to design and build them in a way that takes full advantage of cloud computing.
This includes custom, built-in-house apps designed for a single, specific purpose, API-driven connections that bridge the gap between legacy systems and new services, and innovative apps that leverage open-source code to streamline processes. Each has its own role to play in successfully implementing this tactical trifecta at scale.
Evaluating these on three levels—data center, host, and application architecture (plus code)—is helpful. Options at each level offer significant potential benefits, especially when complemented by practices that influence the design and purchase decisions made by IT leaders and individual contributors. A PUE of 1.0
Experienced engineers used Perl scripts, vi, grep and awk to make log searches more efficient. These historical approaches worked for a different era of software applications: ones more monolithic in design, changing relatively infrequently (once every few weeks or months) and with only a handful of log types to monitor.
As we did with IBM Power , we’re delighted to share that IBM and Dynatrace have joined forces to bring the Dynatrace Operator, along with the comprehensive capabilities of the Dynatrace platform, to Red Hat OpenShift on the IBM Z and LinuxONE architecture (s390x). Dynatrace is designed to scale easily across the entire Kubernetes stack.
Grail architectural basics. The aforementioned principles have, of course, a major impact on the overall architecture. A data lakehouse addresses these limitations and introduces an entirely new architecturaldesign. It’s based on cloud-native architecture and built for the cloud. But what does that mean?
Enhanced data security, better data integrity, and efficient access to information. Despite initial investment costs, DBMS presents long-term savings and improved efficiency through automated processes, efficient query optimizations, and scalability, contributing to enhanced decision-making and end-user productivity.
Building and Scaling Data Lineage at Netflix to Improve Data Infrastructure Reliability, and Efficiency By: Di Lin , Girish Lingappa , Jitender Aswani Imagine yourself in the role of a data-inspired decision maker staring at a metric on a dashboard about to make a critical business decision but pausing to ask a question?—?“Can
In this post, we dive deep into how Netflix’s KV abstraction works, the architectural principles guiding its design, the challenges we faced in scaling diverse use cases, and the technical innovations that have allowed us to achieve the performance and reliability required by Netflix’s global operations.
As dynamic systems architectures increase in complexity and scale, IT teams face mounting pressure to track and respond to conditions and issues across their multi-cloud environments. An advanced observability solution can also be used to automate more processes, increasing efficiency and innovation among Ops and Apps teams.
In the dynamic world of microservices architecture, efficient service communication is the linchpin that keeps the system running smoothly. This dedicated infrastructure layer is designed to cater to service-to-service communication, offering essential features like load balancing, security, monitoring, and resilience.
Table 1: Movie and File Size Examples Initial Architecture A simplified view of our initial cloud video processing pipeline is illustrated in the following diagram. Figure 1: A Simplified Video Processing Pipeline With this architecture, chunk encoding is very efficient and processed in distributed cloud computing instances.
Our Journey so Far Over the past year, we’ve implemented the core infrastructure pieces necessary for a federated GraphQL architecture as described in our previous post: Studio Edge Architecture The first Domain Graph Service (DGS) on the platform was the former GraphQL monolith that we discussed in our first post (Studio API).
The system could work efficiently with a specific number of concurrent users; however, it may get dysfunctional with extra loads during peak traffic. It is almost a part of the wider performance engineering portrait, concentrating on performance glitches in the architecture and design of any software.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content