This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Greenplum Database is a massively parallel processing (MPP) SQL database that is built and based on PostgreSQL. In this blog post, we explain what Greenplum is, and break down the Greenplum architecture, advantages, major use cases, and how to get started. The Greenplum Architecture. The Greenplum Architecture.
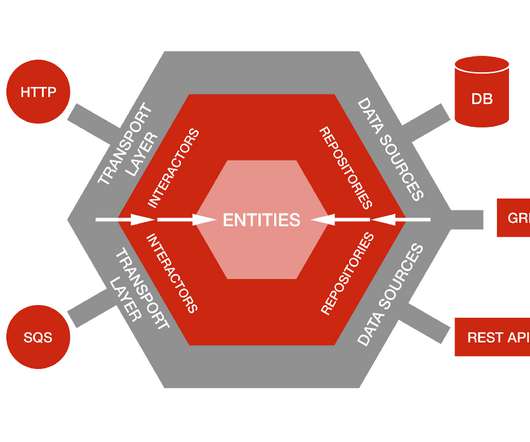
At one point, more than 30 developers were working on it, and it had well over 300 database tables. Leveraging Hexagonal Architecture We needed to support the ability to swap data sources without impacting business logic , so we knew we needed to keep them decoupled. The dependency graph in Hexagonal Architecture goes inward.
At this scale, we can gain a significant amount of performance and cost benefits by optimizing the storage layout (records, objects, partitions) as the data lands into our warehouse. We built AutoOptimize to efficiently and transparently optimize the data and metadata storage layout while maximizing their cost and performance benefits.
To get a better understanding of AWS serverless, we’ll first explore the basics of serverless architectures, review AWS serverless offerings, and explore common use cases. Serverless architecture: A primer. Serverless architecture shifts application hosting functions away from local servers onto those managed by providers.
ScaleGrid is a fully managed DBaaS that supports MySQL, PostgreSQL and Redis™, along with additional support for MongoDB® database and Greenplum® database. Along with many popular cloud providers, DigitalOcean also provides a Managed Databases service. So, which database service is right for your application? Single Node.
Ruchir Jha , Brian Harrington , Yingwu Zhao TL;DR Streaming alert evaluation scales much better than the traditional approach of polling time-series databases. It allows us to overcome high dimensionality/cardinality limitations of the time-series database. It opens doors to support more exciting use-cases.
Architecture. We will use a graph database such as Neo4j to store the information. Additionally, we can use columnar databases like Cassandra to store information like user feeds, activities, and counters. After that, the post gets added to the feed of all the followers in the columnar data storage. High Level Design.
Central to this infrastructure is our use of multiple online distributed databases such as Apache Cassandra , a NoSQL database known for its high availability and scalability. Over time as new key-value databases were introduced and service owners launched new use cases, we encountered numerous challenges with datastore misuse.
a Fast and Scalable NoSQL Database Service Designed for Internet Scale Applications. Today is a very exciting day as we release Amazon DynamoDB , a fast, highly reliable and cost-effective NoSQL database service designed for internet scale applications. Werner Vogels weblog on building scalable and robust distributed systems.
A distributed storage system is foundational in today’s data-driven landscape, ensuring data spread over multiple servers is reliable, accessible, and manageable. Understanding distributed storage is imperative as data volumes and the need for robust storage solutions rise.
Database monitoring. This ensures the database queries are performant, while also identifying host problems. For example, uptime detection can identify database instability and help to improve mean time to restoration. Cloud storage monitoring. Website monitoring. Virtual machine (VM) monitoring.
The strongest Kubernetes growth areas are security, databases, and CI/CD technologies. Strongest Kubernetes growth areas are security, databases, and CI/CD technologies. Of the organizations in the Kubernetes survey, 71% run databases and caches in Kubernetes, representing a +48% year-over-year increase. Java, Go, and Node.js
Having a distributed and scalable graph database system is highly sought after in many enterprise scenarios. Do Not Be Misled Designing and implementing a scalable graph database system has never been a trivial task.
Cloud vendors such as Amazon Web Services (AWS), Microsoft, and Google provide a wide spectrum of serverless services for compute and event-driven workloads, databases, storage, messaging, and other purposes. AI-powered automation and deep, broad observability for serverless architectures. Dynatrace news. New to Dynatrace?
Logs highlight observability challenges Ingesting, storing, and processing the unprecedented explosion of data from sources such as software as a service, multicloud environments, containers, and serverless architectures can be overwhelming for today’s organizations. Grail enables 100% precision insights into all stored data.
Research has found that 99% of organizations have embraced a multicloud architecture. The sheer number of permutations can break traditional databases. When data storage strategies become problematic to DevOps maturity Data warehouse-based approaches add cost and time to analytics projects.
Further, these resources support countless Kubernetes clusters and Java-based architectures. They can call on dozens of databases and deliver gigabytes of data across myriad devices. In most data storage models, indexing engines enable faster access to query logs. Cost-effective architecture.
Relational databases have been around for a long time. The core technologies underpinning the major relational database management systems of today were developed in the 1980–1990s. Those fundamentals helped make relational databases immensely popular with users everywhere.
To make data count and to ensure cloud computing is unabated, companies and organizations must have highly available databases. A basic high availability database system provides failover (preferably automatic) from a primary database node to redundant nodes within a cluster. HA is sometimes confused with “fault tolerance.”
IT infrastructure is the heart of your digital business and connects every area – physical and virtual servers, storage, databases, networks, cloud services. This shift requires infrastructure monitoring to ensure all your components work together across applications, operating systems, storage, servers, virtualization, and more.
Relational databases have been around for a long time. The core technologies underpinning the major relational database management systems of today were developed in the 1980–1990s. Those fundamentals helped make relational databases immensely popular with users everywhere.
Metrics are measures of critical system values, such as CPU utilization or average write latency to persistent storage. They are particularly important in distributed systems, such as microservices architectures. Observability platforms are becoming essential as the complexity of cloud-native architectures increases.
There are many naive solutions possible for this problem for example: Write different runs in different databases. Instead our challenge was to implement this feature on top of Cassandra and ElasticSearch databases because that’s what Marken uses. Marken Architecture Marken’s architecture diagram is as follows.
The choice of self-managed cloud databases vs DBaaS is a common debate among those who are looking for the best option that will cater to their particular needs. Database as a Service (DBaaS) and managed databases offer distinct advantages along with certain challenges.
New databases used to be announced seemingly every week. While database neogenesis has slowed down considerably, it has not gone necrotic. Each storage server collects statistics about the requests it serves, the data it stores, etc. Our monitoring engine automatically moves data between tiers based on access patterns.
Today, we are releasing a plugin that allows customers to use the Titan graph engine with Amazon DynamoDB as the backend storage layer. It opens up the possibility to enjoy the value that graph databases bring to relationship-centric use cases, without worrying about managing the underlying storage. Enter graph databases.
Grail combines the big-data storage of a data warehouse with the analytical flexibility of a data lake. This unified approach enables Grail to vault past the limitations of traditional databases. And without the encumbrances of traditional databases, Grail performs fast. “In
In previous blog posts, we introduced the Key-Value Data Abstraction Layer and the Data Gateway Platform , both of which are integral to Netflix’s data architecture. Note: Contrary to what the name may suggest, this system is not built as a general-purpose time series database.
Traditionally, though, to gain true business insight, organizations had to make tradeoffs between accessing quality, real-time data and factors such as data storage costs. Additionally, it provides index-free storage and direct analytics access to source data without requiring data rehydration. Don’t reinvent the wheel.
There is no need to think about schema and indexes, re-hydration, or hot/cold storage. This architecture also means you are not required to determine your log data use cases beforehand or while analyzing logs within the new logs app. Keep in mind that Dynatrace Grail is schema-on-read and indexless, built with scaling in mind.
The use of open source databases has increased steadily in recent years. Past trepidation — about perceived vulnerabilities and performance issues — has faded as decision makers realize what an “open source database” really is and what it offers. What is an open source database?
Choosing the right database often comes down to MongoDB vs MySQL. Whether you need a relational database for complex transactions or a NoSQL database for flexible data storage, weve got you covered. Data modeling is a critical skill for developers to manage and analyze data within these database systems effectively.
A horizontally scalable exabyte-scale blob storage system which operates out of multiple regions, Magic Pocket is used to store all of Dropbox’s data. Adopting SMR technology and erasure codes, the system has extremely high durability guarantees but is cheaper than operating in the cloud. By Facundo Agriel
Google recently announced various improvements to Cloud Spanner, its distributed, decoupled relational database service with a “50% increase in throughput and 2.5 times the storage per node than before” without a price change. By Steef-Jan Wiggers
Unlike traditional row-based relational databases, which store data for each row sequentially on disk, Amazon Redshift stores each column sequentially. This means that Redshift performs much less wasted IO than a row-based database because it doesnâ??t t read data from columns it doesnâ??t t need when executing a given query.
In many, high-throughput, OLTP style applications the database plays a crucial role to achieve scale, reliability, high-performance and cost efficiency. For a long time, these requirements were almost exclusively served by commercial, proprietary databases.
MySQL 8 brought a significant architectural transformation by replacing the traditional MyISAM-based system tables with the Transaction Data Dictionary (TDD), a more efficient and reliable approach. The primary goal of the Transaction Data Dictionary (TDD) is to enhance the overall performance, stability, and scalability of MySQL databases.
Data powers everything, and unlike coal and coal combustion, data and databases aren’t going away. In this blog, we’ll focus on the elements of database backup and disaster recovery, and we’ll introduce proven solutions for maintaining business continuity, even amid otherwise dire circumstances.
At Netflix, we also heavily embrace a microservice architecture that emphasizes separation of concerns. The KV DAL allows applications to use a well-defined and storage engine agnostic HTTP/gRPC key-value data interface that in turn decouples applications from hard to maintain and backwards-incompatible datastore APIs.
Pinterest has modernized and enhanced its Goku time-series database. The recent updates focus on optimizing storage and resource usage without compromising service quality. By Mohit Palriwal
The goal is to simplify the provisioning and management of database capacity. One approach is to separate compute and storage to allow for independent scaling. It’s an open source alternative to AWS Aurora Postgres that utilizes a serverless architecture. This can now be achieved with ease using Serverless PostgreSQL.
With Dynatrace, there is no need to think about schema and indexes, re-hydration, or hot/cold storage concepts. This architecture also means you’re not required to determine your log data use cases beforehand or while analyzing logs within the new Logs app.
Rather than listing the concepts, function calls, etc, available in Citus, which frankly is a bit boring, I’m going to explore scaling out a database system starting with a single host. I won’t cover all the features but show just enough that you’ll want to see more of what you can learn to accomplish for yourself.
Key Takeaways Redis offers complex data structures and additional features for versatile data handling, while Memcached excels in simplicity with a fast, multi-threaded architecture for basic caching needs. It uses a hash table to manage these pairs, divided into fixed-size buckets with linked lists for key-value storage.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content