This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The Evolution of Back-End Complexity Until recently, back-end architectures were relatively straightforward: monolithic applications ruled the landscape, with everything neatly contained within a single codebase. Developers could understand and manage the entire systems intricacies.
Dynatrace continues to deliver on its commitment to keeping your data secure in the cloud. Enhancing data separation by partitioning each customer’s data on the storage level and encrypting it with a unique encryption key adds an additional layer of protection against unauthorized data access.
With the evolution of modern applications serving increasing needs for real-time data processing and retrieval, scalability does, too. One such open-source, distributed search and analytics engine is Elasticsearch, which is very efficient at handling data in large sets and high-velocity queries.
Multimodal data processing is the evolving need of the latest data platforms powering applications like recommendation systems, autonomous vehicles, and medical diagnostics. Handling multimodal data spanning text, images, videos, and sensor inputs requires resilient architecture to manage the diversity of formats and scale.
Grafana Loki is a horizontally scalable, highly available log aggregation system. We can then parse structured log data to be formatted for our customized analysis needs. It is designed for simplicity and cost-efficiency. Loki can provide a comprehensive log journey. Loki can provide a comprehensive log journey.
Sharding, a database architecture pattern, involves partitioning a database into smaller, faster, more manageable parts called shards. Sharding is particularly useful for managing large-scale databases, offering significant improvements in performance, maintainability, and scalability. What Is Sharding?
In today's data-driven world, organizations need efficient and scalabledata pipelines to process and analyze large volumes of data. Medallion Architecture provides a framework for organizing data processing workflows into different zones, enabling optimized batch and stream processing.
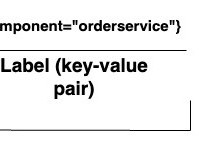
Scalable Annotation Service — Marken by Varun Sekhri , Meenakshi Jindal Introduction At Netflix, we have hundreds of micro services each with its own data models or entities. But there are more interesting cases where users want to store temporal (time-based) data or spatial data. Movie Entity with id 1234 has violence.
It can scale towards a multi-petabyte level data workload without a single issue, and it allows access to a cluster of powerful servers that will work together within a single SQL interface where you can view all of the data. This feature-packed database provides powerful and rapid analytics on data that scales up to petabyte volumes.
Snowflake is a powerful cloud-based data warehousing platform known for its scalability and flexibility. To fully leverage its capabilities and improve efficient data processing, it's crucial to optimize query performance. Snowflake’s architecture consists of three main layers:
RabbitMQ is designed for flexible routing and message reliability, while Kafka handles high-throughput event streaming and real-time data processing. Both serve distinct purposes, from managing message queues to ingesting large data volumes.
A messaging system serves as a backbone, allowing information transmission between different services or modules in a distributed architecture. However, maintaining scalability and fault tolerance in this system is a difficult but necessary task.
Without observability, the benefits of ARM are lost Over the last decade and a half, a new wave of computer architecture has overtaken the world. ARM architecture, based on a processor type optimized for cloud and hyperscale computing, has become the most prevalent on the planet, with billions of ARM devices currently in use.
Furthermore, it was difficult to transfer innovations from one model to another, given that most are independently trained despite using common data sources. This scenario underscored the need for a new recommender system architecture where member preference learning is centralized, enhancing accessibility and utility across different models.
Having a distributed and scalable graph database system is highly sought after in many enterprise scenarios. Do Not Be Misled Designing and implementing a scalable graph database system has never been a trivial task.
Some time ago, at a restaurant near Boston, three Dynatrace colleagues dined and discussed the growing data challenge for enterprises. At its core, this challenge involves a rapid increase in the amount—and complexity—of data collected within a company. Work with different and independent data types. Grail architectural basics.
2020 cemented the reality that modern software development practices require rapid, scalable delivery in response to unpredictable conditions. This method of structuring, developing, and operating complex, multi-function software as a collection of smaller independent services is known as microservice architecture. Dynatrace news.
2020 cemented the reality that modern software development practices require rapid, scalable delivery in response to unpredictable conditions. This method of structuring, developing, and operating complex, multi-function software as a collection of smaller independent services is known as microservice architecture. Dynatrace news.
Part 3: System Strategies and Architecture By: VarunKhaitan With special thanks to my stunning colleagues: Mallika Rao , Esmir Mesic , HugoMarques This blog post is a continuation of Part 2 , where we cleared the ambiguity around title launch observability at Netflix. Store the data in an optimized, highly distributed datastore.
In this article, we’ll dive deep into the concept of database sharding, a critical technique for scaling databases to handle large volumes of data and high levels of traffic. This section will provide insights into the architecture and strategies to ensure efficient query processing in a sharded environment.
Many organizations are taking a microservices approach to IT architecture. However, in some cases, an organization may be better suited to another architecture approach. Therefore, it’s critical to weigh the advantages of microservices against its potential issues, other architecture approaches, and your unique business needs.
Building and Scaling Data Lineage at Netflix to Improve Data Infrastructure Reliability, and Efficiency By: Di Lin , Girish Lingappa , Jitender Aswani Imagine yourself in the role of a data-inspired decision maker staring at a metric on a dashboard about to make a critical business decision but pausing to ask a question?—?“Can
ln a world driven by macroeconomic uncertainty, businesses increasingly turn to data-driven decision-making to stay agile. They’re unleashing the power of cloud-based analytics on large data sets to unlock the insights they and the business need to make smarter decisions. All of these factors challenge DevOps maturity.
Democratizing Stream Processing @ Netflix By Guil Pires , Mark Cho , Mingliang Liu , Sujay Jain Data powers much of what we do at Netflix. On the Data Platform team, we build the infrastructure used across the company to process data at scale. The existing Data Mesh Processors have a lot of overlap with SQL.
Modern organizations ingest petabytes of data daily, but legacy approaches to log analysis and management cannot accommodate this volume of data. based financial services group, discussed how the bank uses log monitoring on the Dynatrace platform with an emphasis on observability and security data.
Youll also learn strategies for maintaining data safety and managing node failures so your RabbitMQ setup is always up to the task. Key Takeaways RabbitMQ improves scalability and fault tolerance in distributed systems by decoupling applications, enabling reliable message exchanges.
It supports multi-line logs, handles log rotation, and even includes mechanisms to check for data corruption. For forensic log analytics use cases, the Security Investigator app benefits from the scalability and analytics power of Dynatrace Grail.
Rajiv Shringi Vinay Chella Kaidan Fullerton Oleksii Tkachuk Joey Lynch Introduction As Netflix continues to expand and diversify into various sectors like Video on Demand and Gaming , the ability to ingest and store vast amounts of temporal data — often reaching petabytes — with millisecond access latency has become increasingly vital.
Now we’re adding Smartscape to DQL and two new data sources to Grail: Metrics on Grail and Traces on Grail. Introducing Metrics on Grail Despite their many advantages, modern cloud-native architectures can result in scalability and fragmentation challenges. Grail solves this scalability issue!
To get a better understanding of AWS serverless, we’ll first explore the basics of serverless architectures, review AWS serverless offerings, and explore common use cases. Serverless architecture: A primer. Serverless architecture shifts application hosting functions away from local servers onto those managed by providers.
Central to this infrastructure is our use of multiple online distributed databases such as Apache Cassandra , a NoSQL database known for its high availability and scalability. Second, developers had to constantly re-learn new data modeling practices and common yet critical data access patterns.
By Tianlong Chen and Ioannis Papapanagiotou Netflix has more than 195 million subscribers that generate petabytes of data everyday. Data scientists and engineers collect this data from our subscribers and videos, and implement data analytics models to discover customer behaviour with the goal of maximizing user joy.
While our engineering teams have and continue to build solutions to lighten this cognitive load (better guardrails, improved tooling, …), data and its derived products are critical elements to understanding, optimizing and abstracting our infrastructure. In the Reliability space, our data teams focus on two main approaches.
by Jun He , Akash Dwivedi , Natallia Dzenisenka , Snehal Chennuru , Praneeth Yenugutala , Pawan Dixit At Netflix, Data and Machine Learning (ML) pipelines are widely used and have become central for the business, representing diverse use cases that go beyond recommendations, predictions and data transformations.
The jobs executing such workloads are usually required to operate indefinitely on unbounded streams of continuous data and exhibit heterogeneous modes of failure as they run over long periods. Summary Ensuring fault tolerance in data-intensive, event-driven applications is crucial for successful industry deployments.
IT operations analytics is the process of unifying, storing, and contextually analyzing operational data to understand the health of applications, infrastructure, and environments and streamline everyday operations. ITOA collects operational data to identify patterns and anomalies for faster incident management and near-real-time insights.
A summary of sessions at the first Data Engineering Open Forum at Netflix on April 18th, 2024 The Data Engineering Open Forum at Netflix on April 18th, 2024. At Netflix, we aspire to entertain the world, and our data engineering teams play a crucial role in this mission by enabling data-driven decision-making at scale.
Grail: Enterprise-ready data lakehouse Grail, the Dynatrace causational data lakehouse, was explicitly designed for observability and security data, with artificial intelligence integrated into its foundation. Tables are a physical data model, essentially the type of observability data that you can store.
As dynamic systems architectures increase in complexity and scale, IT teams face mounting pressure to track and respond to conditions and issues across their multi-cloud environments. As teams begin collecting and working with observability data, they are also realizing its benefits to the business, not just IT. Dynatrace news.
Lifting and shifting applications from the data center to the cloud delivers only marginal benefits. To take full advantage of the scalability, flexibility, and resilience of cloud platforms, organizations need to build or rearchitect applications around a cloud-native architecture. What is cloud-native architecture?
Netflix applies data science to hundreds of use cases across the company, including optimizing content delivery and video encoding. Data scientists at Netflix relish our culture that empowers them to work autonomously and use their judgment to solve problems independently. How could we improve the quality of life for data scientists?
2 billion : Pokémon GO revenue since launch; 10 : say happy birthday to StackOverflow; $148 million : Uber data breach fine; 75% : streaming music industry revenue in the US; 5.2 Martin Sústrik : Philosophers, by and large, tend to be architecture astronauts. Programmers' insight is that architecture astronauts fail.
At much less than 1% of CPU and memory on the instance, this highly performant sidecar provides flow data at scale for network insight. Flow Exporter The Flow Exporter is a sidecar that uses eBPF tracepoints to capture TCP flows at near real time on instances that power the Netflix microservices architecture. What is BPF?
By Anupom Syam Background At Netflix, our current data warehouse contains hundreds of Petabytes of data stored in AWS S3 , and each day we ingest and create additional Petabytes. We built AutoOptimize to efficiently and transparently optimize the data and metadata storage layout while maximizing their cost and performance benefits.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content