This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
By Abhinaya Shetty , Bharath Mummadisetty At Netflix, our Membership and Finance DataEngineering team harnesses diverse data related to plans, pricing, membership life cycle, and revenue to fuel analytics, power various dashboards, and make data-informed decisions. It also becomes inefficient as the data scale increases.
A summary of sessions at the first DataEngineering Open Forum at Netflix on April 18th, 2024 The DataEngineering Open Forum at Netflix on April 18th, 2024. At Netflix, we aspire to entertain the world, and our dataengineering teams play a crucial role in this mission by enabling data-driven decision-making at scale.
Architecture Overview The first pivotal step in managing impressions begins with the creation of a Source-of-Truth (SOT) dataset. Collecting Raw Impression Events As Netflix members explore our platform, their interactions with the user interface spark a vast array of raw events.
At its most basic, automating IT processes works by executing scripts or procedures either on a schedule or in response to particular events, such as checking a file into a code repository. When monitoring tools release a stream of alerts, teams can easily identify which ones are false and assess whether an event requires human intervention.
We adopted the following mission statement to guide our investments: “Provide a complete and accurate data lineage system enabling decision-makers to win moments of truth.” Nonetheless, Netflix data landscape (see below) is complex and many teams collaborate effectively for sharing the responsibility of our data system management.
While our engineering teams have and continue to build solutions to lighten this cognitive load (better guardrails, improved tooling, …), data and its derived products are critical elements to understanding, optimizing and abstracting our infrastructure. Give us a holler if you are interested in a thought exchange.
This article will list some of the use cases of AutoOptimize, discuss the design principles that help enhance efficiency, and present the high-level architecture. Some of the optimizations are prerequisites for a high-performance data warehouse. Both automatic (event-driven) as well as manual (ad-hoc) optimization.
Meson was based on a single leader architecture with high availability. It serves thousands of users, including data scientists, dataengineers, machine learning engineers, software engineers, content producers, and business analysts, for various use cases. Figure 1 shows the high-level architecture.
It is easier to tune a large Spark job for a consistent volume of data. As you may know, S3 can emit messages when events (such as a file creation events) occur which can be directed into an AWS SQS queue. These events represent a specific cut of data from the table.
This year’s growth in Python usage was buoyed by its increasing popularity among data scientists and machine learning (ML) and artificial intelligence (AI) engineers. Software architecture, infrastructure, and operations are each changing rapidly. Key survey results: The C-suite is engaged with data quality.
These challenges are currently addressed in suboptimal and less cost efficient ways by individual local teams to fulfill the needs, such as Lookback: This is a generic and simple approach that dataengineers use to solve the data accuracy problem. Users configure the workflow to read the data in a window (e.g.
The creation and management of data pipelines isn’t something that operations groups are responsible for–though, despite the proliferation of new titles like “dataengineer” and “data ops,” in the future I suspect these jobs will be subsumed into “operations.”. Upcoming events.
Canva evaluated different data massaging solutions for its Product Analytics Platform, including the combination of AWS SNS and SQS, MKS, and Amazon KDS, and eventually chose the latter, primarily based on its much lower costs. The company compared many aspects of these solutions, like performance, maintenance effort, and cost.
T riplebyte lets exceptional software engineers skip screening steps at hundreds of top tech companies like Apple, Dropbox, Mixpanel, and Instacart. Learn to balance architecture trade-offs and design scalable enterprise-level software. Make your job search O (1), not O ( n ). Apply here. Need excellent people? Advertise your job here!
T riplebyte lets exceptional software engineers skip screening steps at hundreds of top tech companies like Apple, Dropbox, Mixpanel, and Instacart. Learn to balance architecture trade-offs and design scalable enterprise-level software. Make your job search O (1), not O ( n ). Apply here. Need excellent people? Advertise your job here!
T riplebyte lets exceptional software engineers skip screening steps at hundreds of top tech companies like Apple, Dropbox, Mixpanel, and Instacart. Learn to balance architecture trade-offs and design scalable enterprise-level software. Make your job search O (1), not O ( n ). Apply here. Need excellent people? Advertise your job here!
Created by former senior-level AWS engineers of 15 years. Learn to balance architecture trade-offs and design scalable enterprise-level software. Etleap is analyst-friendly , enterprise-grade ETL-as-a-service , built for Redshift and Snowflake data warehouses and S3/Glue data lakes. Learn the Good Parts of AWS.
A common theme across all these trends is to remove the complexity by simplifying data management as a whole. In 2018, we anticipate that ETL will either lose relevance or the ETL process will disintegrate and be consumed by new dataarchitectures. Unified data management architecture.
This event is designed to help senior developers navigate their immediate development challenges, focusing exclusively on the technical aspects that matter right now. InfoQ is delighted to announce a new two-day conference, InfoQ Dev Summit Boston 2024, taking place June 24-25, 2024. By Artenisa Chatziou
The engineering organisation described may not work for you because of a team of 8-10 people is still a very big overhead. In this model, software architecture and code ownership is a reflection of the organisational model. Thirdly, let engineers themselves choose the delivery teams and organise them around the initiative.
Kubernetes has emerged as go to container orchestration platform for dataengineering teams. In 2018, a widespread adaptation of Kubernetes for big data processing is anitcipated. Organisations are already using Kubernetes for a variety of workloads [1] [2] and data workloads are up next.
This summer also marks the 4-yearly event that is La Copa Mundial (we only get Telemundo in my apartment, not Fox Sports Network) but since the good old US of A are absent from the men’s World Cup this year, football fever is distinctly frigid. It’s a great event full of deep technology experience, and a whole breadth of diversity.
Cheap storage and on-demand compute in the cloud coupled with the emergence of new big data frameworks and tools are forcing us to rethink the whole ETL and data warehousing architecture. In addition, this approach is more tailored for both structured as well unstructured data sets. Classic ETL. Late transformation.
Data integration generally requires in-depth domain knowledge, a strong understanding of data schemas and underlying relationships. This can be time-consuming and bit challenging if you are dealing with hundreds of data sources and thousands of event types (see my recent article on ELT architecture ).
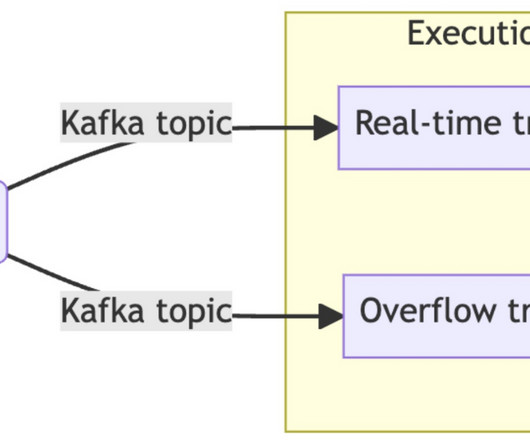
HubSpot adopted routing messages over multiple Kafka topics (called swimlanes) for the same producer to avoid the build-up in the consumer group lag and prioritize the processing of real-time traffic.
To learn about Analytics and Viz Engineering, have a look at Analytics at Netflix: Who We Are and What We Do by Molly Jackman & Meghana Reddy and How Our Paths Brought Us to Data and Netflix by Julie Beckley & Chris Pham. Curious to learn about what it’s like to be a DataEngineer at Netflix?
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
































Let's personalize your content