This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
A summary of sessions at the first DataEngineering Open Forum at Netflix on April 18th, 2024 The DataEngineering Open Forum at Netflix on April 18th, 2024. At Netflix, we aspire to entertain the world, and our dataengineering teams play a crucial role in this mission by enabling data-driven decision-making at scale.
By Abhinaya Shetty , Bharath Mummadisetty At Netflix, our Membership and Finance DataEngineering team harnesses diverse data related to plans, pricing, membership life cycle, and revenue to fuel analytics, power various dashboards, and make data-informed decisions.
DataEngineers of Netflix?—?Interview Interview with Samuel Setegne Samuel Setegne This post is part of our “DataEngineers of Netflix” interview series, where our very own dataengineers talk about their journeys to DataEngineering @ Netflix. What drew you to Netflix?
Architecture Overview The first pivotal step in managing impressions begins with the creation of a Source-of-Truth (SOT) dataset. The enriched data is seamlessly accessible for both real-time applications via Kafka and historical analysis through storage in an Apache Iceberg table.
Our data scientists often want to apply their knowledge of the business and statistics to fully understand the outcome of an experiment. Instead of relying on engineers to productionize scientific contributions, we’ve made a strategic bet to build an architecture that enables data scientists to easily contribute.
We adopted the following mission statement to guide our investments: “Provide a complete and accurate data lineage system enabling decision-makers to win moments of truth.” Nonetheless, Netflix data landscape (see below) is complex and many teams collaborate effectively for sharing the responsibility of our data system management.
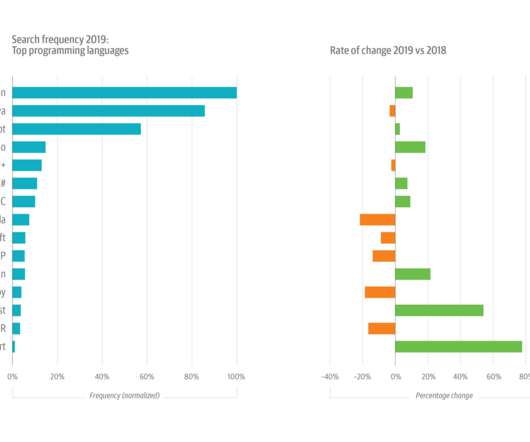
This year’s growth in Python usage was buoyed by its increasing popularity among data scientists and machine learning (ML) and artificial intelligence (AI) engineers. Software architecture, infrastructure, and operations are each changing rapidly. Trends in software architecture, infrastructure, and operations.
The evolution of your technology architecture should depend on the size, culture, and skill set of your engineering organization. There are no hard-and-fast rules to figure out interdependency between technology architecture and engineering organization but below is what I think can really work well for product startup.
As organizations continue to adopt multicloud strategies, the complexity of these environments grows, increasing the need to automate cloud engineering operations to ensure organizations can enforce their policies and architecture principles. How organizations benefit from automating IT practices.
While our engineering teams have and continue to build solutions to lighten this cognitive load (better guardrails, improved tooling, …), data and its derived products are critical elements to understanding, optimizing and abstracting our infrastructure. Give us a holler if you are interested in a thought exchange.
This article will list some of the use cases of AutoOptimize, discuss the design principles that help enhance efficiency, and present the high-level architecture. Some of the optimizations are prerequisites for a high-performance data warehouse.
Meson was based on a single leader architecture with high availability. It serves thousands of users, including data scientists, dataengineers, machine learning engineers, software engineers, content producers, and business analysts, for various use cases. Figure 1 shows the high-level architecture.
Inconsistent network performance affecting data synchronization. Introduce scalable microservices architectures to distribute computational loads efficiently. Key issues include: A shortage of edge-native dataengineers and architects. Limited understanding of edge-specific use cases among traditional IT teams.
To learn about Analytics and Viz Engineering, have a look at Analytics at Netflix: Who We Are and What We Do by Molly Jackman & Meghana Reddy and How Our Paths Brought Us to Data and Netflix by Julie Beckley & Chris Pham. Curious to learn about what it’s like to be a DataEngineer at Netflix?
These challenges are currently addressed in suboptimal and less cost efficient ways by individual local teams to fulfill the needs, such as Lookback: This is a generic and simple approach that dataengineers use to solve the data accuracy problem. Users configure the workflow to read the data in a window (e.g.
Summary Providing Network Insight into the Cloud Network Infrastructure using VPC Flow Logs at hyper scale is made possible with the Sqooby architecture. After several iterations of this architecture and some tuning, Sqooby has proven to be able to scale.
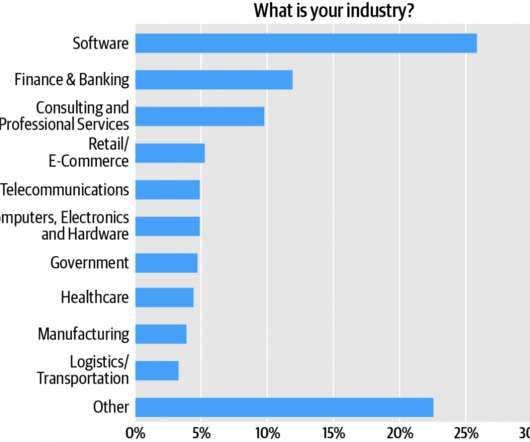
Software engineers comprise the survey audience’s single largest cluster, over one quarter (27%) of respondents (Figure 1). If you combine the different architectural roles—i.e., Adding architects and engineers, we see that roughly 55% of the respondents are directly involved in software development.
Collaboration between AI developers and operations teams will lead to growing pains on both sides, especially since many data scientists and AI researchers have had limited exposure to, or knowledge of, software engineering. O’Reilly Strata Data & AI Conference , San Jose, March 15-18.
T riplebyte lets exceptional software engineers skip screening steps at hundreds of top tech companies like Apple, Dropbox, Mixpanel, and Instacart. Learn to balance architecture trade-offs and design scalable enterprise-level software. Make your job search O (1), not O ( n ). Apply here. Need excellent people? Advertise your job here!
Data ingestion is the foremost layer in a dataengineering pipeline, acting as a vital pillar in the overall analytics architecture. Thus, it is essential to implement data ingestion just right. Here is everything you need to know to take the first step toward a flawless data pipeline.
T riplebyte lets exceptional software engineers skip screening steps at hundreds of top tech companies like Apple, Dropbox, Mixpanel, and Instacart. Learn to balance architecture trade-offs and design scalable enterprise-level software. Make your job search O (1), not O ( n ). Apply here. Need excellent people? Advertise your job here!
T riplebyte lets exceptional software engineers skip screening steps at hundreds of top tech companies like Apple, Dropbox, Mixpanel, and Instacart. Learn to balance architecture trade-offs and design scalable enterprise-level software. Make your job search O (1), not O ( n ). Apply here. Need excellent people? Advertise your job here!
Evolving to Auto Remediation: Service Architecture Methodology To address the above-mentioned challenges, our basic methodology is to integrate the rule-based classifier with an ML service to generate recommendations, and use a configuration service to apply the recommendations automatically: Generating recommendations.
Created by former senior-level AWS engineers of 15 years. Learn to balance architecture trade-offs and design scalable enterprise-level software. Etleap is analyst-friendly , enterprise-grade ETL-as-a-service , built for Redshift and Snowflake data warehouses and S3/Glue data lakes. Learn the Good Parts of AWS.
The reality is that many traditional BI solutions are built on top of legacy desktop and on-premises architectures that are decades old. They require teams of dataengineers to spend months building complex data models and synthesizing the data before they can generate their first report.
Businesses can unlock the value of data only after it is transformed into actionable insights and when those insights are delivered promptly. But implementing such robust data pipelines can be complex and challenging. This blog discusses all the ins and outs of building data pipelines and how they can help strengthen businesses.
A common theme across all these trends is to remove the complexity by simplifying data management as a whole. In 2018, we anticipate that ETL will either lose relevance or the ETL process will disintegrate and be consumed by new dataarchitectures. Unified data management architecture.
STP213 Scaling global carbon footprint management — Blake Blackwell Persefoni Manager DataEngineering and Michael Floyd AWS Head of Sustainability Solutions. SUS302 Optimizing architectures for sustainability — Katja Philipp AWS SA and Szymon Kochanski AWS SA. SUS209 — there was no talk with this code.
Uber uses Presto, an open-source distributed SQL query engine, to provide analytics across several data sources, including Apache Hive, Apache Pinot, MySQL, and Apache Kafka. To improve its performance, Uber engineers explored the advantages of dealing with quick queries, a.k.a.
Unfortunately, building data pipelines remains a daunting, time-consuming, and costly activity. Not everyone is operating at Netflix or Spotify scale dataengineering function. Often companies underestimate the necessary effort and cost involved to build and maintain data pipelines.
The engineering organisation described may not work for you because of a team of 8-10 people is still a very big overhead. In this model, software architecture and code ownership is a reflection of the organisational model. Thirdly, let engineers themselves choose the delivery teams and organise them around the initiative.
Kubernetes has emerged as go to container orchestration platform for dataengineering teams. In 2018, a widespread adaptation of Kubernetes for big data processing is anitcipated. Organisations are already using Kubernetes for a variety of workloads [1] [2] and data workloads are up next.
Mei-Chin Tsai, Vinod discuss the internal architecture of Azure Cosmos DB and how it achieves high availability, low latency, and scalability. By Mei-Chin Tsai, Vinod Sridharan
Stream processing has become a core part of enterprise dataarchitecture today due to the explosive growth of data from sources such as IoT sensors, security logs, and web applications. This blog discusses the topic of stream processing in detail to help you navigate its landscape with ease.
I was fortunate to be both presenting a 2-day workshop (on AWS Serverless Architectures and Continuous Deployment) as well as hosting a full-day Serverless track of talks. One of the catalysts for starting Symphonia was the massive interest in my article on “ Serverless Architectures ” that is published on Martin Fowler’s site.
Zendesk reduced its data storage costs by over 80% by migrating from DynamoDB to a tiered storage solution using MySQL and S3. The company considered different storage technologies and decided to combine the relational database and the object store to strike a balance between querybility and scalability while keeping the costs down.
He specifically delved into Venice DB, the NoSQL data store used for feature persistence. At the QCon London 2024 conference, Félix GV from LinkedIn discussed the AI/ML platform powering the company’s products. By Rafal Gancarz
Cheap storage and on-demand compute in the cloud coupled with the emergence of new big data frameworks and tools are forcing us to rethink the whole ETL and data warehousing architecture. In addition, this approach is more tailored for both structured as well unstructured data sets. Classic ETL. Stateless and elastic.
Maintaining Uber’s large-scale data warehouse comes with an operational cost in terms of ETL functions and storage. Once identified, … The post Less is More: EngineeringData Warehouse Efficiency with Minimalist Design appeared first on Uber Engineering Blog.
Canva evaluated different data massaging solutions for its Product Analytics Platform, including the combination of AWS SNS and SQS, MKS, and Amazon KDS, and eventually chose the latter, primarily based on its much lower costs. The company compared many aspects of these solutions, like performance, maintenance effort, and cost.
Data integration generally requires in-depth domain knowledge, a strong understanding of data schemas and underlying relationships. This can be time-consuming and bit challenging if you are dealing with hundreds of data sources and thousands of event types (see my recent article on ELT architecture ).
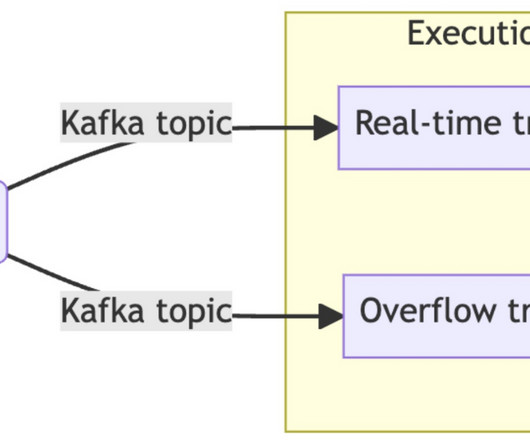
HubSpot adopted routing messages over multiple Kafka topics (called swimlanes) for the same producer to avoid the build-up in the consumer group lag and prioritize the processing of real-time traffic.
InfoQ is delighted to announce a new two-day conference, InfoQ Dev Summit Boston 2024, taking place June 24-25, 2024. This event is designed to help senior developers navigate their immediate development challenges, focusing exclusively on the technical aspects that matter right now. By Artenisa Chatziou
LinkedIn introduced Couchbase as a centralized caching tier for scaling member profile reads to handle increasing traffic that has outgrown their existing database cluster. The new solution achieved over 99% hit rate, helped reduce tail latencies by more than 60% and costs by 10% annually. By Rafal Gancarz
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content