This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Today, I want to share my experience working with Zabbix, its architecture, its pros, and its cons. My first encounter with this monitoring system was in 2014 when I joined a project where Zabbix was already in use for monitoring network devices (routers, switches). Back then, it was version 2.2,
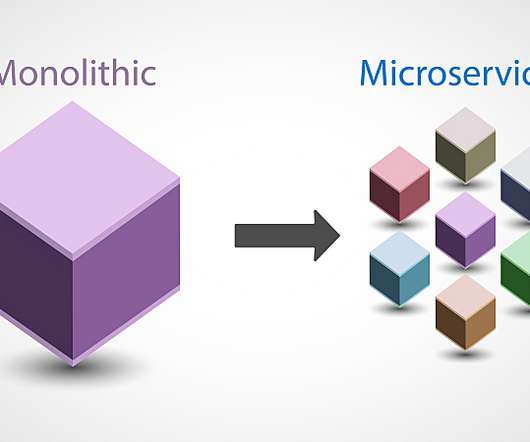
As a result, organizations are weighing microservices vs. monolithic architecture to improve software delivery speed and quality. Traditional monolithic architectures are built around the concept of large applications that are self-contained, independent, and incorporate myriad capabilities. What is monolithic architecture?
Eight years ago I wrote _Systems Performance: Enterprise and the Cloud_ (aka the "sysperf" book) on the performance of computing systems, and this year I'm excited to be releasing the second edition. A year ago I announced [BPF Performance Tools: Linux System and Application Observability]. Which book should you buy?
Grail architectural basics. The aforementioned principles have, of course, a major impact on the overall architecture. A data lakehouse addresses these limitations and introduces an entirely new architectural design. It’s based on cloud-native architecture and built for the cloud. But what does that mean?
The fact is, Reliability and Resiliency must be rooted in the architecture of a distributed system. The email walked through how our Dynatrace self-monitoring notified users of the outage but automatically remediated the problem thanks to our platform’s architecture. Fact #2: No significant impact on Dynatrace Users.
A distributed storage system is foundational in today’s data-driven landscape, ensuring data spread over multiple servers is reliable, accessible, and manageable. This guide delves into how these systems work, the challenges they solve, and their essential role in businesses and technology.
This means a system that is not merely available but is also engineered with extensive redundant measures to continue to work as its users expect. Fault tolerance The ability of a system to continue to be dependable (both available and reliable) in the presence of certain component or subsystem failures.
Over the course of the last year, we’ve incrementally extended the coverage of security policies to provide a common authorization mechanism for the entire Dynatrace platform. Having a configurable, flexible, and centralized system for authorization reduces management effort and allows you to handle complex authorization requirements.
New Architectures (this post). Cloud seriously impacts systemarchitectures that has a lot of performance-related consequences. First, we have a shift to centrally managed systems. Software as a Service’ (SaaS) basically are centrally managed systems with multiple tenants/instances. . – Agile.
The implications of software performance issues and outages have a significantly broader impact than in the past—with the potential to negatively impact revenue, customer experiences, patient outcomes, and, of course, brand reputation. Ideally, resiliency plans would lead to complete prevention.
Hyperscale is the ability of an architecture to scale appropriately as increased demand is added to the system. Organizations, and teams within them, need to stay the course, leveraging multicloud platforms to meet the demand of users proactively and proficiently, as well as drive business growth. What is hyperscale?
The need for fast product delivery led us to experiment with a multiplatform architecture. This approach works well for us for several reasons: Our Android and iOS studio apps have a shared architecture with similar or in some cases identical business logic written on both platforms. Networking Hendrix interprets rule set(s)?—?remotely
Imagine traditional support operations: for every alert detected by a monitoring system, a ticket is created in an ITSM solution, someone then takes action on the ticket, kicks-off activities until the situation is resolved and the ticket can be closed. For example, invoking a webhook that creates a ticket in an ITSM system.
Evaluating these on three levels—data center, host, and application architecture (plus code)—is helpful. You might optimize your cooling system or move your data center to a colder region with reduced cooling demands. Application architectures might not be conducive to rehosting. Unfortunately, it’s not that simple.
Lightweight architecture. The overall architecture – including the consolidated Dynatrace API – is shown below: Different problem visualizations build on top of a lightweight backend that uses the consolidated Dynatrace API. Getting the problem status of all environments has to be efficient. js framework. js framework.
I should start by saying this section does not offer a treatise on how to do architecture. Technology systems are difficult to wrangle. Our systems grow in accidental complexity and complication over time. Vitruvius and the principles of architecture. Architecture begins when someone has a nontrivial problem to be solved.
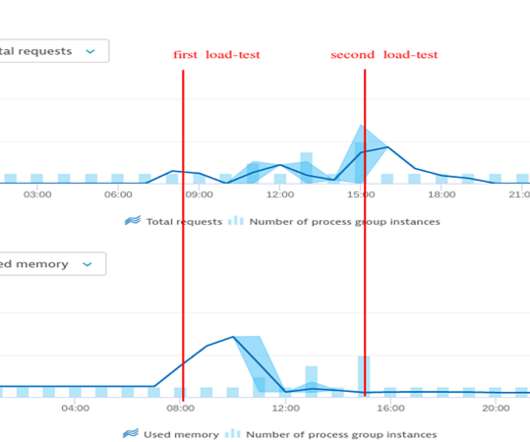
For that reason, we started a simple load-test scenario where we flooded our event-based system with 100 cloud-events per minute. Thanks to the simplicity of our microservice architecture, we were able to quickly identify that our MongoDB connection handling was the root cause of the memory leak. And of course: no more OOMs.
According to IBM , application modernization takes existing legacy applications and modernizes their platform infrastructure, internal architecture, or features. Of course, cloud application modernization solutions are not always focused on rebuilding from the ground up. Why should organizations modernize applications?
“Because of the uncertainty of the times and the likely realities of the ‘new normal,’ more and more organizations are now charting the course for their journeys toward cloud computing and digital transformation,” wrote Gaurav Aggarwal in a Forbes article the impact of COVID-19 on cloud adoption.
As digital transformation accelerates, organizations turn to hybrid and multicloud architectures to innovate, grow, and reduce costs. But the complexity and scale of multicloud architecture invites new enterprise challenges. Security vulnerabilities can easily creep into IT systems and create costly risks.
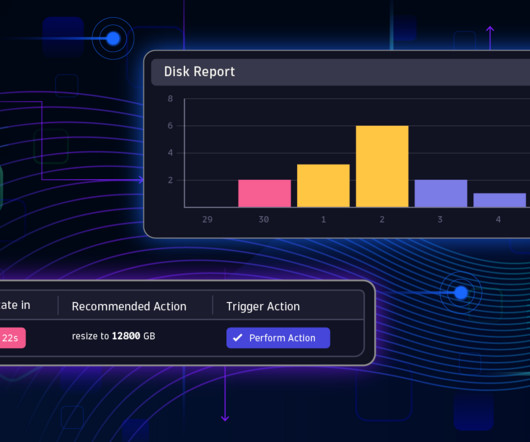
Figure 1: Overview of upcoming resizing operations Developer Observability app provides a shared view of issues Dynatrace production systems generate about 10 TB of log data each day, which contains valuable information about errors and other issues.
Distributed tracing describes the act of following a transaction through all participating applications (tiers) and sub-systems, such as databases. All systems that support distributed tracing use some identifiers, the trace context, that is passed along with the transaction. Of course, Dynatrace supports W3C Trace Context as well.
Kubernetes can be a confounding platform for system architects. Cloud-native software design, much like microservices architecture, is founded on the premise of speed to delivery via phases, or iterations. Dynatrace news. Microservice design principles force people to think along a spectrum of loose coupling.
Distributing accounts across the infrastructure is an architectural decision, as a given account often has similar usage patterns, languages, and sizes for their Lambda functions. Of course, this requires a VM that provides rock-solid isolation, and in AWS Lambda, this is the Firecracker microVM. The virtual CPU is turned off.
Hyperconverged infrastructure (HCI) is an IT architecture that combines servers, storage, and networking functions into a unified, software-centric platform to streamline resource management. In a standard server or resource model, silos are par for the course. That’s where hyperconverged infrastructure, or HCI, comes in.
With the acceleration of complexity, scale, and dynamic systemsarchitectures, under-resourced IT teams are under increasing pressure to understand when there is abnormal behavior, identify the precise reason why this occurred, quickly remediate the issue, and prevent this behavior in the future. How do you make a system ‘observable’?
The increasing number of smaller, decoupled services brings new challenges for controlling complexity within systems. Of course, this comes with all the benefits that Dynatrace is known for: the Davis® AI causation engine and entity model, automatic topology detection in Smartscape, auto-baselining, automated error detection, and much more.
Operations teams want to make sure the system doesn’t break. Dieter Landenahuf, a senior ACE Engineer at Dynatrace, built Jenkins pipelines for new microservice architectures by creating templates and copying, pasting, and modifying them slightly. Charting the course with Keptn. Limits of scripting for DevOps and SRE.
Such a gigantic log analysis system is part of their cybersecurity management. For the need of real-time monitoring, threat tracing, and alerting, they require a log analytic system that can automatically collect, store, analyze, and visualize logs and event records.
Cloud-based application architectures commonly leverage microservices. In response to this trend, open source communities birthed new companies like WSO2 (of course, industry giants like Google, IBM, Software AG, and Tibco are also competing for a piece of the API management cake). In fact, it’s a multidimensional discipline.
From a technical standpoint, I think multi-threaded architecture is quite superior; the cost of process context switch is a lot more expensive than thread context switch. The database is performance-critical software; you must use the most high-performance operating system concepts to get the best performance possible.
These systems are often difficult to scale because the underlying ML engine doesn’t provide continuous, real-time insight into the precise root cause of issues. This contrasts stochastic AIOps approaches that use probability models to infer the state of systems. Why is AIOps needed? AIOps use cases.
Anomalous behavior in a newly deployed application can easily escape human detection, but AIOps systems complement SecOps engineers by identifying and reporting on potentially exploitable vulnerabilities. This process continues until the system identifies a root cause. The four stages of data processing. Two types of root cause.
As they move into the workforce, they need to deepen their knowledge and become part of a team writing a software system for a paying customer. You have to think about how any code you write fits in with what’s there already and also with what might be there in the future; you have to think about larger designs and architectures.
Statoscope: A Course Of Intensive Therapy For Your Bundle. Statoscope: A Course Of Intensive Therapy For Your Bundle. It might not be completely efficient if we use modules in raw form, as they are in the file system: there might be some doubles, some modules could be combined, and others are only partially used. Sergey Melukov.
Despite the drive in some quarters to make microservice architectures the default approach for software, I feel that due to their numerous challenges, adopting them still requires careful thought. They are an architectural approach, not the architectural approach. Where microservices don’t work well.
Introducing Metrics on Grail Despite their many advantages, modern cloud-native architectures can result in scalability and fragmentation challenges. For more complex cloud-native architectures, adding more services and applications leads to a massive increase in the volume of collected traces.
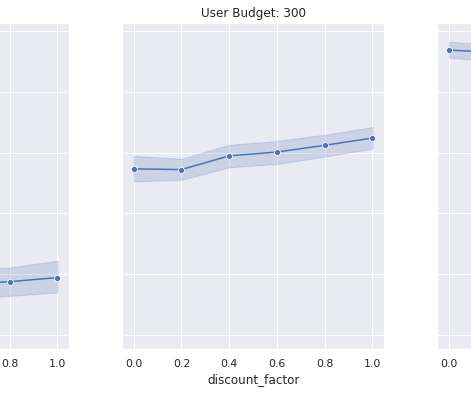
Working within the time budget introduces an extra resource constraint for the recommender system. It is important to point out that the user’s time budget, like their preferences, may not be directly observable and the recommender system may have to learn that in addition to the user’s latent preferences.
Managing and operating asynchronous workflows can be difficult without the proper tools and architecture that puts observability, debugging, and tracing at the forefront. However, they are scattered across multiple systems, and there isn’t an easy way to tie related messages together. Imagine getting paged outside normal work hours?—?users
Other distributions like Debian and Fedora are available as well, in addition to other software like VMware, NGINX, Docker, and, of course, Java. We anticipate massive growth in the popularity of this architecture in the coming quarters, driven additionally by companies’ push for cost reductions.
Distributed tracing is used to understand control flow within distributed systems. Especially in dynamic microservices architectures, distributed tracing is an essential component of efficient monitoring, application optimization, debugging, and troubleshooting. Dynatrace news. What is distributed tracing?
Of course, much like the grapes, no two organizations are the same; how they adapted; how they took the challenge head-on; and how they changed their focus. Initially, there was an expectation that remote working would make this almost impossible, especially as teams were used to going into a room to whiteboard development and architecture.
Computer architecture is an important and exciting field of computer science, which enables many other fields (eg. For those of us who pursued computer architecture as a career, this is well understood. In most curriculums, undergrad students do not have much exposure to computer architecture. Why is that? Lack of Exposure.
At best, this is a false summit on the right path; at worst, it’s a local maximum far from AGI, which lies along a very different route in a different range of architectures and thinking. When we look at other systems and scales, it’s easy to be drawn to superficial similarities in the small and project them into the large.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content