This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
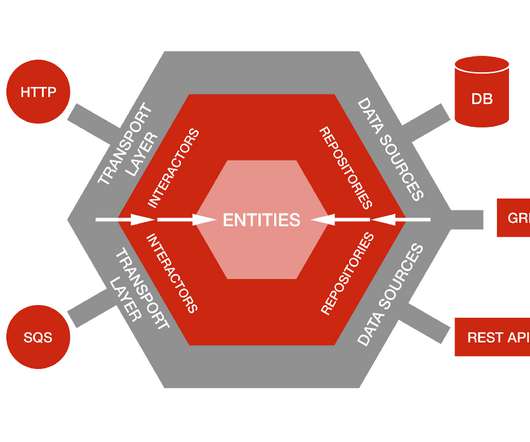
by Damir Svrtan and Sergii Makagon As the production of Netflix Originals grows each year, so does our need to build apps that enable efficiency throughout the entire creative process. We decided to build our app based on principles behind Hexagonal Architecture and Uncle Bob’s Clean Architecture.
In today's data-driven world, organizations need efficient and scalable data pipelines to process and analyze large volumes of data. Medallion Architecture provides a framework for organizing data processing workflows into different zones, enabling optimized batch and stream processing.
Process Automation is defined as “a centerpiece of digitalization efforts” – where workflow engines are used as “a vital building block in modern architectures.” We also dive deep into Robotic Process Automation, how organizations are finding success with it, the risks involved, and why he considers it as a "short-term painkiller".
If you are living in the same world as I am, you must have heard the latest coding buzzer termed “ microservices ”—a lifeline for developers and enterprise-scale businesses. Over the last few years, microservice architecture emerged to be on top of conventional SOA (Service Oriented Architecture).
Many organizations are taking a microservices approach to IT architecture. However, in some cases, an organization may be better suited to another architecture approach. Therefore, it’s critical to weigh the advantages of microservices against its potential issues, other architecture approaches, and your unique business needs.
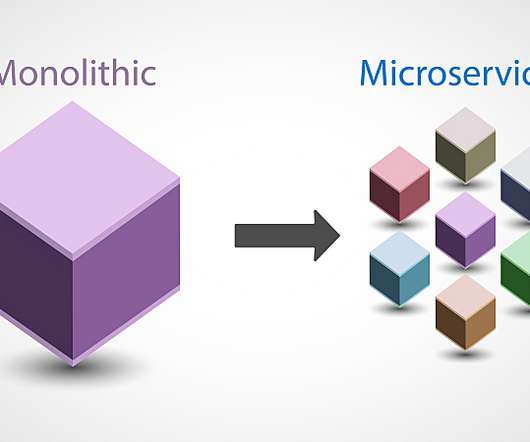
As a result, organizations are weighing microservices vs. monolithic architecture to improve software delivery speed and quality. Traditional monolithic architectures are built around the concept of large applications that are self-contained, independent, and incorporate myriad capabilities. What is monolithic architecture?
This method of structuring, developing, and operating complex, multi-function software as a collection of smaller independent services is known as microservice architecture. ” it helps to understand the monolithic architectures that preceded them. Understanding monolithic architectures.
This method of structuring, developing, and operating complex, multi-function software as a collection of smaller independent services is known as microservice architecture. ” it helps to understand the monolithic architectures that preceded them. Understanding monolithic architectures.
Without observability, the benefits of ARM are lost Over the last decade and a half, a new wave of computer architecture has overtaken the world. ARM architecture, based on a processor type optimized for cloud and hyperscale computing, has become the most prevalent on the planet, with billions of ARM devices currently in use.
The IT world is rife with jargon — and “as code” is no exception. “As code” means simplifying complex and time-consuming tasks by automating some, or all, of their processes. ” While this methodology extends to every layer of the IT stack, infrastructure as code (IAC) is the most prominent example.
Future blogs will provide deeper dives into each service, sharing insights and lessons learned from this process. The Netflix video processing pipeline went live with the launch of our streaming service in 2007. The Netflix video processing pipeline went live with the launch of our streaming service in 2007.
What developers want Developers want to own their code in a distributed, ephemeral, cloud, microservices-based environment. This ownership starts with understanding how their code behaves in all environments, resolving issues, and writing and optimizing code in a high-quality, secure, and timely manner.
To get a better understanding of AWS serverless, we’ll first explore the basics of serverless architectures, review AWS serverless offerings, and explore common use cases. Serverless architecture: A primer. Serverless architecture shifts application hosting functions away from local servers onto those managed by providers.
In today's fast-paced software development landscape, microservices have emerged as a popular architectural pattern. This architectural style enables teams to develop and deploy services independently, offering flexibility and scalability to the software development process. But what exactly are microservices?
by Jun He , Yingyi Zhang , and Pawan Dixit Incremental processing is an approach to process new or changed data in workflows. The key advantage is that it only incrementally processes data that are newly added or updated to a dataset, instead of re-processing the complete dataset.
Indeed, according to one survey, DevOps practices have led to 60% of developers releasing code twice as quickly. But increased speed creates a tradeoff: According to another study, nearly half of organizations consciously deploy vulnerable code because of time pressure. Increased adoption of Infrastructure as code (IaC).
Transforming an application from monolith to microservices-based architecture can be daunting, and knowing where to start can be difficult. Unsurprisingly, organizations are breaking away from monolithic architectures and moving toward event-driven microservices. Likewise, refactoring and rewriting code takes a lot of time and effort.
To take full advantage of the scalability, flexibility, and resilience of cloud platforms, organizations need to build or rearchitect applications around a cloud-native architecture. So, what is cloud-native architecture, exactly? What is cloud-native architecture? The principles of cloud-native architecture.
The reality of the startup is that engineering teams are often at a crossroads when it comes to choosing the foundational architecture for their software applications. The allure of a microservice architecture is understandable in today's tech state of affairs, where scalability, flexibility, and independence are highly valued.
As dynamic systems architectures increase in complexity and scale, IT teams face mounting pressure to track and respond to conditions and issues across their multi-cloud environments. An advanced observability solution can also be used to automate more processes, increasing efficiency and innovation among Ops and Apps teams.
We’re delighted to share that IBM and Dynatrace have joined forces to bring the Dynatrace Operator, along with the comprehensive capabilities of the Dynatrace platform, to Red Hat OpenShift on the IBM Power architecture (ppc64le). It also detects new containers and injects OneAgent code modules into application pods.
Trace your application Imagine a microservices architecture with hundreds of dependencies. This architecture also means you’re not required to determine your log data use cases beforehand or while analyzing logs within the new logs app. Interact with data intuitively and easily and benefit from immediate, AI-supported insights.
This article delves deep into the essence of Istio, illustrating its pivotal role in a Kubernetes (KIND) based environment, and guides you through a Helm-based installation process, ensuring a comprehensive understanding of Istio's capabilities and its impact on microservices architecture.
Evaluating these on three levels—data center, host, and application architecture (plus code)—is helpful. Application architectures might not be conducive to rehosting. From here, it’s time to consider the next level of energy optimization, green coding. Many of the same principles can be applied to green coding.
Grail architectural basics. The aforementioned principles have, of course, a major impact on the overall architecture. A data lakehouse addresses these limitations and introduces an entirely new architectural design. Ingest and process with Grail. It’s based on cloud-native architecture and built for the cloud.
In most financial firms, online transaction processing (OLTP) often relies on static or infrequently updated data, also called reference data. I will share a coding lab to measure the performance of AWS-managed NoSQL databases such as DynamoDB , Cassandra , Redis , and MongoDB.
Cloud-native technologies and microservice architectures have shifted technical complexity from the source code of services to the interconnections between services. Heterogeneous cloud-native microservice architectures can lead to visibility gaps in distributed traces. Deep-code execution details. Dynatrace news.
DevSecOps is a cross-team collaboration framework that integrates security into DevOps processes from the start rather than waiting to address security in a separate silo. DevOps has gained ground in recent years as a way to combine key operational principles with development cycles, recognizing that these two processes must coexist.
Our Journey so Far Over the past year, we’ve implemented the core infrastructure pieces necessary for a federated GraphQL architecture as described in our previous post: Studio Edge Architecture The first Domain Graph Service (DGS) on the platform was the former GraphQL monolith that we discussed in our first post (Studio API).
Observability as a topic is becoming more important as applications are using microservice architectures and are deployed in Kubernetes environments. Davis not only identified the garbage collection as the root-cause, but pointed me to the specific process causing the trouble. Dynatrace news. The setup . The service flow .
When undertaking system migrations, one of the main challenges is establishing confidence and seamlessly transitioning the traffic to the upgraded architecture without adversely impacting the customer experience. There is also an increased risk that bugs in the replay logic have the potential to impact production code and metrics.
As cloud-native, distributed architectures proliferate, the need for DevOps technologies and DevOps platform engineers has increased as well. DevOps teams are responsible for all phases of the software development lifecycle, from code commit to the deployment of products and services. A DevOps platform engineer is a more recent term.
This blog post guides you through configuring Dynatrace to automate CI/CD processes to achieve these objectives. Dynatrace observability architecture can be classified into three layers: Orchestration (Dynatrace) CI/CD toolset (Jenkins / Chef / Puppet / Bamboo, etc.) The below screenshot shows the code initiating the Jenkins job.
The show surrounding logs function provides Dynatrace users with the ability to dive deeper and surface context-specific log lines of the components and services linked to the problem—all without a single line of code or complex query language knowledge. Petabyte per day and tenant; this will soon increase to one Petabyte per day and tenant.
The risk of impact from an existing known vulnerability also depends on whether certain processes are using the vulnerable parts of a software component. This information specifies which function in the source code relates to a vulnerability. Process group 1 doesn’t use the function that contains the vulnerability.
As companies strive to innovate and deliver faster, modern software architecture is evolving at near the speed of light. This gives you deep visibility into your code running in Azure Functions, and, as a result, an understanding of its impact on overall application performance and user experience. Dynatrace news.
Dynatrace Configuration as Code enables complete automation of the Dynatrace platform’s configuration, ensuring that software is secure and reliable. With Configuration as Code, developers can manage their observability and security tasks with config files that can be developed alongside source code conveniently and at scale.
Still, while DevOps practices enable developer agility and speed as well as better code quality, they can also introduce complexity and data silos. More seamless handoffs between tasks in the toolchain can improve DevOps efficiency, software development innovation, and better code quality. They need automated DevOps practices.
As we did with IBM Power , we’re delighted to share that IBM and Dynatrace have joined forces to bring the Dynatrace Operator, along with the comprehensive capabilities of the Dynatrace platform, to Red Hat OpenShift on the IBM Z and LinuxONE architecture (s390x).
While data lakes and data warehousing architectures are commonly used modes for storing and analyzing data, a data lakehouse is an efficient third way to store and analyze data that unifies the two architectures while preserving the benefits of both. Massively parallel processing. What is a data lakehouse?
To drive better outcomes using hybrid cloud architectures, it helps to understand their benefits—and how to orchestrate them seamlessly. What is hybrid cloud architecture? Hybrid cloud architecture is a computing environment that shares data and applications on a combination of public clouds and on-premises private clouds.
According to IBM , application modernization takes existing legacy applications and modernizes their platform infrastructure, internal architecture, or features. Document and benchmark existing applications, processes, and services. Once a modernization plan is in place, strategize how to monitor and measure the process.
Site reliability engineering (SRE) is the practice of applying software engineering principles to operations and infrastructure processes to help organizations create highly reliable and scalable software systems. Shift-left using an SRE approach means that reliability is baked into each process, app and code change.
Cloud-native CI/CD pipelines and build processes often expose Kubernetes to attack vectors via internet-sourced container images. Incorporating signed Dynatrace containers into your pipeline To enhance security in CI/CD processes, Dynatrace customers can integrate verified Dynatrace container images into their deployment pipelines.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content