This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The rapid evolution of cloud technology continues to shape how businesses operate and compete. This year’s AWS re:Invent will showcase a suite of new AWS and Dynatrace integrations designed to enhance cloud performance, security, and automation.
DevOps and security teams managing today’s multicloud architectures and cloud-native applications are facing an avalanche of data. Moreover, teams are constantly dealing with continuously evolving cyberthreats to data both on premises and in the cloud.
To this end, we developed a Rapid Event Notification System (RENO) to support use cases that require server initiated communication with devices in a scalable and extensible manner. In this blog post, we will give an overview of the Rapid Event Notification System at Netflix and share some of the learnings we gained along the way.
As an executive, I am always seeking simplicity and efficiency to make sure the architecture of the business is as streamlined as possible. Last year Dynatrace research revealed that the average multi-cloud environment spans 12 different platforms and services, exacerbating the issue of data silos.
I realized that our platforms unique ability to contextualize security events, metrics, logs, traces, and user behavior could revolutionize the security domain by converging observability and security. Collect observability and security data user behavior, metrics, events, logs, traces (UMELT) once, store it together and analyze in context.
Dynatrace enables our customers to monitor and optimize their cloud infrastructure and applications through the Dynatrace Software Intelligence Platform. We want to share how Dynatrace helped us identify and fix memory leaks in one of the most central and critical components within Keptn: our event broker. Dynatrace news. Yes, we can!
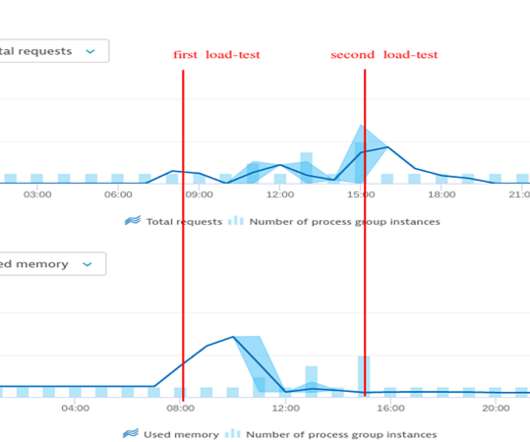
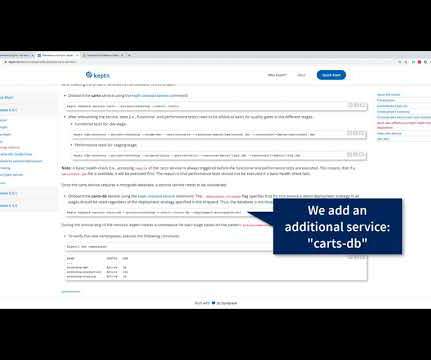
Self-Service Progressive Delivery of Microservices, Automated SLI/SLO based Quality Gates, Continuous Feedback through ChatOps and Automatic Remediation of Production Issues are some of the capabilities you expect from a modern cloud-native software delivery platform. The recent improvements released in Keptn 0.6,
However, with these benefits come complexities in terms of cloud management, Kubernetes observability, and automation, making it imperative for enterprises to address these intricacies to enhance reliability, performance, and resource usage.
Autonomous Cloud Enablement (ACE) and Keptn – the Event-Driven Autonomous Cloud Control Plane – are helping our Dynatrace customers to automate their delivery and operations processes. There’s more from Christian and the rest of the Keptn and Autonomous Cloud community that we can all benefit from. Dynatrace news.
By: Rajiv Shringi , Oleksii Tkachuk , Kartik Sathyanarayanan Introduction In our previous blog post, we introduced Netflix’s TimeSeries Abstraction , a distributed service designed to store and query large volumes of temporal event data with low millisecond latencies. Today, we’re excited to present the Distributed Counter Abstraction.
Leveraging cloud-native technologies like Kubernetes or Red Hat OpenShift in multicloud ecosystems across Amazon Web Services (AWS) , Microsoft Azure, and Google Cloud Platform (GCP) for faster digital transformation introduces a whole host of challenges. Dynatrace news. Logs provide information you can’t find anywhere else.
As cloud environments become increasingly complex, legacy solutions can’t keep up with modern demands. As a result, companies run into the cloud complexity wall – also known as the cloud observability wall – as they struggle to manage modern applications and gain multicloud observability with outdated tools.
RabbitMQ is designed for flexible routing and message reliability, while Kafka handles high-throughput event streaming and real-time data processing. This article outlines the key differences in architecture, performance, and use cases to help determine the best fit for your workload. What is RabbitMQ? What is Apache Kafka?
How can you reduce the carbon footprint of your hybrid cloud? Evaluating these on three levels—data center, host, and application architecture (plus code)—is helpful. energy-efficient data centers—cloud providers—achieve values closer to 1.2. Is the solution to just move all workloads to the cloud? Want to learn more?
Cloud observability is fast becoming an imperative as more organizations adopt multicloud IT strategies. To adapt, many are turning to AIOps and other automation technologies to solve the complex issues that accompany cloud-native architecture. Multicloud complexity obscures cloud observability. Dynatrace news.
As more organizations invest in a multicloud strategy, improving cloud operations and observability for increased resilience becomes critical to keep up with the accelerating pace of digital transformation. American Family turned to observability for cloud operations. Step 2: Instrument compute and serverless cloud technologies.
Cloud observability can bring business value, said Rick McConnell, CEO at Dynatrace. Organizations have clearly experienced growth, agility, and innovation as they move to cloud computing architecture. But without effective cloud observability, they continue to experience challenges in their cloud environments.
For many companies, the journey to modern cloud applications starts with serverless. To get a better understanding of AWS serverless, we’ll first explore the basics of serverless architectures, review AWS serverless offerings, and explore common use cases. Serverless architecture: A primer. Dynatrace news. Reliability.
Perform serves yearly as the marquis Dynatrace event to unveil new announcements, learn about new uses and best practices, and meet with peers and partners alike. More so than ever before, organizations are investing in cloud migration and cloud modernization to lower total cost of ownership (TCO). What can we move?
Streamlining site reliability at scale can be daunting, particularly with large-scale AWS environments and architecture that rely on hundredsor even thousandsof Amazon EC2 instances. This step-by-step guide will show you how to configure your architecture to trigger guardians whenever EC2 tags are updated.
Logs complement metrics and enable automation Cloud practitioners agree that observability, security, and automation go hand in hand. The increasing complexity of cloud service architectures requires a rock-solid understanding of the activity, health status, and security of cloud services.
For IT teams seeking agility, cost savings, and a faster on-ramp to innovation, a cloud migration strategy is critical. Cloud migration enables IT teams to enlist public cloud infrastructure so an organization can innovate without getting bogged down in managing all aspects of IT infrastructure as it scales. Dynatrace news.
Today’s organizations face increasing pressure to keep their cloud-based applications performing and secure. Cloud application security remains challenging because organizations lack end-to-end visibility into cloudarchitecture.
As dynamic systems architectures increase in complexity and scale, IT teams face mounting pressure to track and respond to conditions and issues across their multi-cloud environments. Observability relies on telemetry derived from instrumentation that comes from the endpoints and services in your multi-cloud computing environments.
The path to Autonomous Cloud Management (ACM) and NoOps is a transformational journey that reaches all parts of an organization. For these reasons, and to educate you, we have developed a five-day immersive Autonomous Cloud Lab (ACL) which will walk you through some of the key concepts of what it means to not only talk ACM but also walk it.
Challenges The cloud network infrastructure that Netflix utilizes today consists of AWS services such as VPC, DirectConnect, VPC Peering, Transit Gateways, NAT Gateways, etc and Netflix owned devices. IP addresses within the cloud can move from one EC2 instance or Titus container to another over time. What is BPF?
In this blog post, we explain what Greenplum is, and break down the Greenplum architecture, advantages, major use cases, and how to get started. It’s architecture was specially designed to manage large-scale data warehouses and business intelligence workloads by giving you the ability to spread your data out across a multitude of servers.
Transforming an application from monolith to microservices-based architecture can be daunting, and knowing where to start can be difficult. Unsurprisingly, organizations are breaking away from monolithic architectures and moving toward event-driven microservices. Migration is time-consuming and involved.
As organizations increasingly migrate their applications to the cloud, efficient and scalable load balancing becomes pivotal for ensuring optimal performance and high availability. Load balancing is a critical component in cloudarchitectures for various reasons. What Is Load Balancing?
Before an organization moves to function as a service, it’s important to understand how it works, its benefits and challenges, its effect on scalability, and why cloud-native observability is essential for attaining peak performance. Cloud providers then manage physical hardware, virtual machines, and web server software management.
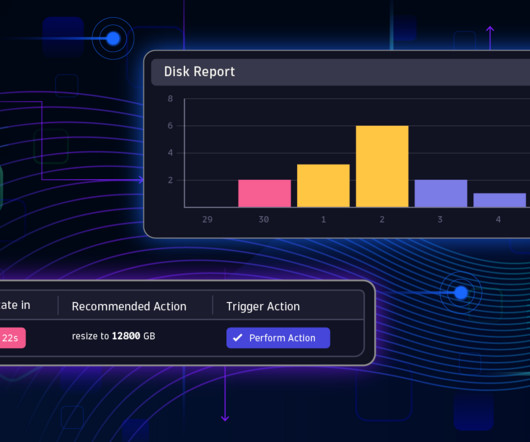
Automate disk resizing operations with Davis AI predictive analytics The Dynatrace Site Reliability Engineering (SRE) team was looking for a way to automatically adjust disk space for cloud volumes on a regular basis to avoid over- or under-provisioning them. Hyperscaler security events are ingested into Grail as BizEvents.
In an era dominated by automated, code-driven software deployments through Kubernetes and cloud services, human operators simply can’t keep up without intelligent observability and root cause analysis tools. In the realm of cloud infrastructure management, having a clear and concise view of your deployment’s health is crucial.
In the world of cloud computing and event-driven applications, efficiency and flexibility are absolute necessities. A proper architecture ensures that there are no bottlenecks in the movement of messages. A smooth flow of messages in an event-driven application is the key to its performance and efficiency.
Distributed tracing is a method of observing requests as they propagate through distributed cloud environments. As legacy monolithic applications give way to more nimble and portable services, the tools once used to monitor their performance are unable to serve the complex cloud-native architectures that now host them.
Grail architectural basics. The aforementioned principles have, of course, a major impact on the overall architecture. A data lakehouse addresses these limitations and introduces an entirely new architectural design. It’s based on cloud-native architecture and built for the cloud. But what does that mean?
Reference data sources don’t always require ACID transaction capabilities, rather need support for fast read queries often based on simple data access patterns, and event-driven architecture to ensure the target systems remain up-to-date.
We’re delighted to share that IBM and Dynatrace have joined forces to bring the Dynatrace Operator, along with the comprehensive capabilities of the Dynatrace platform, to Red Hat OpenShift on the IBM Power architecture (ppc64le). Captures metrics, traces, logs, and other telemetry data in context.
Log monitoring, log analysis, and log analytics are more important than ever as organizations adopt more cloud-native technologies, containers, and microservices-based architectures. Driving this growth is the increasing adoption of hyperscale cloud providers (AWS, Azure, and GCP) and containerized microservices running on Kubernetes.
Cloud vendors such as Amazon Web Services (AWS), Microsoft, and Google provide a wide spectrum of serverless services for compute and event-driven workloads, databases, storage, messaging, and other purposes. AI-powered automation and deep, broad observability for serverless architectures. Dynatrace news. New to Dynatrace?
Developing applications based on modern architectures comes with a challenge for release automation: integrating delivery of many services with similar processes but often with different technologies and tools along the delivery pipelines. Dynatrace Cloud Automation now enables you to implement process definitions that are tool agnostic.
Kubernetes teams lack simple, consistent, vendor-agnostic architectures for analyzing observability signals across teams. Kubernetes workload pages offer resource analysis, lists of services, pods, events, and logs. The same page provides further analysis with workload logs and events. What’s ahead in 2023.
All these micro-services are currently operated in AWS cloud infrastructure. Finally, provisioning our infrastructure itself is also becoming an increasingly complex task, so our data teams contribute to tools for diagnosis and automation of our cloud capacity management.
IT, DevOps, and SRE teams are racing to keep up with the ever-expanding complexity of modern enterprise cloud ecosystems and the business demands they are designed to support. Observability is the new standard of visibility and monitoring for cloud-native architectures. Dynatrace news.
Distributed tracing is a method of observing requests as they propagate through distributed cloud environments. As legacy monolithic applications give way to more nimble and portable services, the tools once used to monitor their performance are unable to serve the complex cloud-native architectures that now host them.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content