This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Teams often consider external caches when the existing database cannot meet the required service-level agreement (SLA). However, external caches are not as simple as they are often made out to be. However, external caches are not as simple as they are often made out to be. This is a clear performance-oriented decision.
By: Rajiv Shringi , Oleksii Tkachuk , Kartik Sathyanarayanan Introduction In our previous blog post, we introduced Netflix’s TimeSeries Abstraction , a distributed service designed to store and query large volumes of temporal event data with low millisecond latencies. Today, we’re excited to present the Distributed Counter Abstraction.
The original assumptions and architectural choices were no longer viable. We introduce a caching mechanism in the API gateway layer, allowing us to offload processing from singleton leader elected controllers without giving up strict data consistency and guarantees clients observe. How do I know that my cache is up to date?
Caching is a critical technique for optimizing application performance by temporarily storing frequently accessed data, allowing for faster retrieval during subsequent requests. Multi-layered caching involves using multiple levels of cache to store and retrieve data.
“Latency” is the duration from the execution of a load instruction (to an address that misses in all the caches), and the completion of that load instruction when the data is returned from memory. . The example below is for a 2005-era processor with 60 ns memory latency and 6.4
This scenario underscored the need for a new recommender system architecture where member preference learning is centralized, enhancing accessibility and utility across different models. Yet, many are confined to a brief temporal window due to constraints in serving latency or training costs.
Caches are very useful software components that all engineers must know. It is a transversal component that applies to all the tech areas and architecture layers such as operating systems, data platforms, backend, frontend, and other components. What Is a Cache?
These include challenges with tail latency and idempotency, managing “wide” partitions with many rows, handling single large “fat” columns, and slow response pagination. Data Model At its core, the KV abstraction is built around a two-level map architecture. Developers just provide their data problem rather than a database solution!
Because microprocessors are so fast, computer architecture design has evolved towards adding various levels of caching between compute units and the main memory, in order to hide the latency of bringing the bits to the brains. This avoids thrashing caches too much for B and evens out the pressure on the L3 caches of the machine.
Table 1: Movie and File Size Examples Initial Architecture A simplified view of our initial cloud video processing pipeline is illustrated in the following diagram. Figure 1: A Simplified Video Processing Pipeline With this architecture, chunk encoding is very efficient and processed in distributed cloud computing instances.
Retrieval-augmented generation emerges as the standard architecture for LLM-based applications Given that LLMs can generate factually incorrect or nonsensical responses, retrieval-augmented generation (RAG) has emerged as an industry standard for building GenAI applications.
The new Amazon capability enables customers to improve the startup latency of their functions from several seconds to as low as sub-second (up to 10 times faster) at P99 (the 99th latency percentile). This can cause latency outliers and may lead to a poor end-user experience for latency-sensitive applications.
When undertaking system migrations, one of the main challenges is establishing confidence and seamlessly transitioning the traffic to the upgraded architecture without adversely impacting the customer experience. It provides a good read on the availability and latency ranges under different production conditions.
Architecture. When a user requests for feed then there will be two parallel threads involved in fetching the user feeds to optimize for latency. We will use a cache having an LRU based eviction policy for caching user feeds of active users. Sending and receiving messages from other users. High Level Design. Optimization.
Moreover, common database optimizations like caching recently queried data don’t really work for alerting queries because, generally speaking, the last received datapoint is required for correctness. First and foremost, we have successfully alleviated our initial scalability problem with the polling based architecture. OK, Results?
This allows the app to query a list of “paths” in each HTTP request, and get specially formatted JSON (jsonGraph) that we use to cache the data and hydrate the UI. For us, it means that we now need to have ~15 MDN tabs open when writing routes :) Let’s briefly discuss the architecture of this microservice. It was a Node.js
Because of its scalability and distributed architecture, thousands of companies trust it to run their cloud and hybrid-based workloads at high availability without compromising performance. With the Dynatrace Data Explorer, you can easily analyze metrics, such as client read/write latency by Cassandra nodes and disk space usage by keyspaces.
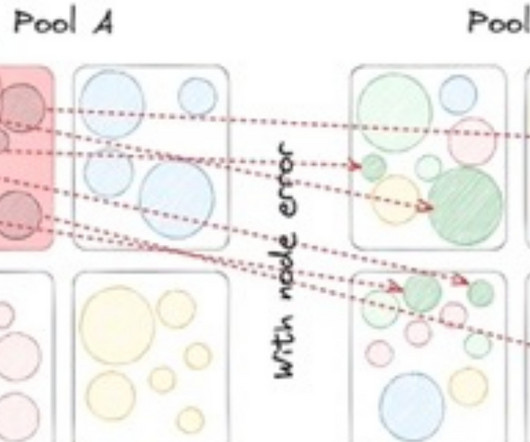
Rajiv Shringi Vinay Chella Kaidan Fullerton Oleksii Tkachuk Joey Lynch Introduction As Netflix continues to expand and diversify into various sectors like Video on Demand and Gaming , the ability to ingest and store vast amounts of temporal data — often reaching petabytes — with millisecond access latency has become increasingly vital.
But we cannot search or present low latency retrievals from files Etc. Marken Architecture Marken’s architecture diagram is as follows. Marken Architecture Marken’s architecture diagram is as follows. Using memcache allows us to keep latencies for our search low (most of our queries are less than 100ms).
The Tech Hollow , an OSS technology we released a few years ago, has been best described as a total high-density near cache : Total : The entire dataset is cached on each node?—?there there is no eviction policy, and there are no cache misses. Near : the cache exists in RAM on any instance which requires access to the dataset.
While data lakes and data warehousing architectures are commonly used modes for storing and analyzing data, a data lakehouse is an efficient third way to store and analyze data that unifies the two architectures while preserving the benefits of both. Data lakehouses deliver the query response with minimal latency.
Organizations are depending more and more on distributed architectures to provide application services. For example, when monitoring a database, you’ll want to know about any latency when writing data to a disk or average query response time. Dynatrace news. This trend is prompting advances in both observability and monitoring.
Because Google offers its own Google Cloud Architecture Framework and Microsoft its Azure Well-Architected Framework , organizations that use a combination of these platforms triple the challenge of integrating their performance frameworks into a cohesive strategy. SRG validates the status of the resiliency SLOs for the experiment period.
Choosing your database architecture may be the most critical decision you’ll make and has a disproportionate impact on the performance, scalability, and availability of your app. No single database architecture or solution can meet all of Amazon.com’s or our customers’ needs.
RevenueCat extensively uses caching to improve the availability and performance of its product API while ensuring consistency. The company shared its techniques to deliver the platform, which can handle over 1.2 billion daily API requests. The team at RevenueCat created an open-source memcache client that provides several advanced features.
Key Takeaways Redis offers complex data structures and additional features for versatile data handling, while Memcached excels in simplicity with a fast, multi-threaded architecture for basic caching needs. Introduction Caching serves a dual purpose in web development – speeding up client requests and reducing server load.
We are standing on the eve of the 5G era… 5G, as a monumental shift in cellular communication technology, holds tremendous potential for spurring innovations across many vertical industries, with its promised multi-Gbps speed, sub-10 ms low latency, and massive connectivity. Throughput and latency. energy consumption).
Amazon DynamoDB offers low, predictable latencies at any scale. This architectural pattern was a response to the scaling challenges that had challenged Amazon.com through its first 5 years, when direct database access was one of the major bottlenecks in scaling and operating the business. This impacts the predictability of a Domainâ??s
Last week we looked at a function shipping solution to the problem; Cloudburst uses the more common data shipping to bring data to caches next to function runtimes (though you could also make a case that the scheduling algorithm placing function execution in locations where the data is cached a flavour of function-shipping too).
With its widespread use in modern application architectures, understanding the ins and outs of Redis monitoring is essential for any tech professional. Identifying key Redis metrics such as latency, CPU usage, and memory metrics is crucial for effective Redis monitoring. Redis, a powerful in-memory data store, is no exception.
Choosing a cloud DBMS: architectures and tradeoffs Tan et al., As it is infeasible to test every OLAP system runnable on AWS, we chose widely-used systems that represented a variety of architectures and cost models. Query performance is measured from both warm and cold caches. VLDB’19.
When designing an architecture, many components need to be considered before deciding on the best solution. In this context, features like filtering, firewalling, or caching are redundant and may consume resources that could be allocated to scaling. MySQL Router is the one that has the higher latency no matter what.
In this blog post, I will explain how these three new capabilities empower you to build applications with distributed systems architecture and create responsive, reliable, and high-performance applications using DynamoDB that work at any scale. DynamoDB Cross-region Replication.
With its widespread use in modern application architectures, understanding the ins and outs of Redis® monitoring is essential for any tech professional. Identifying key Redis® metrics such as latency, CPU usage, and memory metrics is crucial for effective Redis monitoring. Redis®, a powerful in-memory data store, is no exception.
Here’s how the same test performed when running Percona Distribution for PostgreSQL 14 on these same servers: Queries: reads Queries: writes Queries: other Queries: total Transactions Latency (95th) MySQL (A) 1584986 1645000 245322 3475308 122277 20137.61 MySQL (B) 2517529 2610323 389048 5516900 194140 11523.48
CDNs cache content on edge servers distributed globally, reducing the distance between users and the content they want.CDNs use load-balancing techniques to distribute incoming traffic across multiple servers called Points of Presence (PoPs) which distribute content closer to end-users and improve overall performance.
CDNs cache content on edge servers distributed globally, reducing the distance between users and the content they want.â€CDNs â€What is CDN Architecture? CDNs cache content on edge servers distributed globally, reducing the distance between users and the content they want.â€CDNs â€What is CDN Architecture?â€CDN
Helios also serves as a reference architecture for how Microsoft envisions its next generation of distributed big-data processing systems being built. These two narratives of reference architecture and ingestion/indexing system are interwoven throughout the paper. Why do we need a new reference architecture? Emphasis mine ).
While registrars manage the namespace in the DNS naming architecture, DNS servers are used to provide the mapping between names and the addresses used to identify an access point. There are two main types of DNS servers: authoritative servers and caching resolvers. Authoritative servers hold the definitive mappings.
Generally to cache data (including non-persistent data that never sees a backing store), to share non-persistent data across application services (e.g. ” Even re-reading that today, the letter of the law there is surprisingly strict to me: you can use the local memory space or filesystem as a brief single transaction cache, but no more.
A message-based microservices architecture offers many advantages, making solutions easier to scale and expand with new services. The asynchronous nature of interservice interactions inherent to this architecture, however, poses challenges for user-initiated actions such as create-read-update-delete (CRUD) requests on an object.
“Latency” is the duration from the execution of a load instruction (to an address that misses in all the caches), and the completion of that load instruction when the data is returned from memory. . The example below is for a 2005-era processor with 60 ns memory latency and 6.4
The most obvious and common way this happens is when companies try to evolve their caches into a data platform that can, for example, be used as highly available enterprise key-value stores for volatile data. Let’s look at a typical scenario involving the javax cache API, also known as JSR107. How hard can it be?
LinkedIn introduced Couchbase as a centralized caching tier for scaling member profile reads to handle increasing traffic that has outgrown their existing database cluster. The new solution achieved over 99% hit rate, helped reduce tail latencies by more than 60% and costs by 10% annually. By Rafal Gancarz
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content