This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Teams often consider external caches when the existing database cannot meet the required service-level agreement (SLA). However, external caches are not as simple as they are often made out to be. However, external caches are not as simple as they are often made out to be. This is a clear performance-oriented decision.
Personalization systems handle the recommendation and serving of titles on these canvases, leveraging a vast ecosystem of microservices, caches, databases, code, and configurations to build these product canvases. What is the architecture of the systems involved? How do we ensure standardization?
Caches are very useful software components that all engineers must know. It is a transversal component that applies to all the tech areas and architecture layers such as operating systems, data platforms, backend, frontend, and other components. What Is a Cache?
The strongest Kubernetes growth areas are security, databases, and CI/CD technologies. Strongest Kubernetes growth areas are security, databases, and CI/CD technologies. Of the organizations in the Kubernetes survey, 71% run databases and caches in Kubernetes, representing a +48% year-over-year increase.
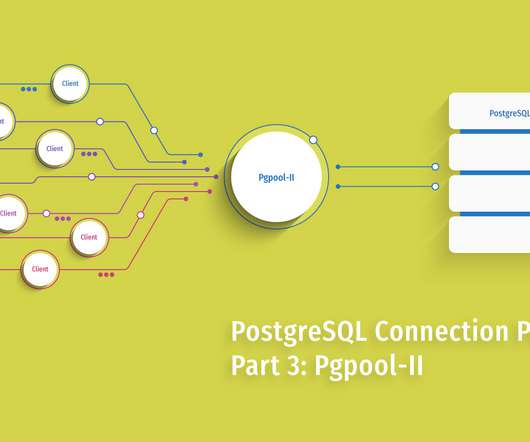
Check out the Pgpool-II architecture that supports all of its features, and learn how the connection pooler works. Pgpool-II has a more involved architecture than PgBouncer in order to support all the features it does. The architecture is similar to PostgreSQL server: one process = one connection. How it works.
To get a better understanding of AWS serverless, we’ll first explore the basics of serverless architectures, review AWS serverless offerings, and explore common use cases. Serverless architecture: A primer. Serverless architecture shifts application hosting functions away from local servers onto those managed by providers.
Ruchir Jha , Brian Harrington , Yingwu Zhao TL;DR Streaming alert evaluation scales much better than the traditional approach of polling time-series databases. It allows us to overcome high dimensionality/cardinality limitations of the time-series database. It opens doors to support more exciting use-cases.
Retrieval-augmented generation emerges as the standard architecture for LLM-based applications Given that LLMs can generate factually incorrect or nonsensical responses, retrieval-augmented generation (RAG) has emerged as an industry standard for building GenAI applications.
Central to this infrastructure is our use of multiple online distributed databases such as Apache Cassandra , a NoSQL database known for its high availability and scalability. Over time as new key-value databases were introduced and service owners launched new use cases, we encountered numerous challenges with datastore misuse.
Infrastructure Optimization: 100% improvement in Database Connectivity. Missing Cache Settings – Make sure you cache resources that don’t change often on the browser or use a CDN. Reducing performance and architectural issues in their backend system gave them a 99% performance improvement!
Architecture. We will use a graph database such as Neo4j to store the information. Additionally, we can use columnar databases like Cassandra to store information like user feeds, activities, and counters. Sample Queries supported by Graph Database. Sending and receiving messages from other users. High Level Design.
The need for fast product delivery led us to experiment with a multiplatform architecture. This approach works well for us for several reasons: Our Android and iOS studio apps have a shared architecture with similar or in some cases identical business logic written on both platforms.
a Fast and Scalable NoSQL Database Service Designed for Internet Scale Applications. Today is a very exciting day as we release Amazon DynamoDB , a fast, highly reliable and cost-effective NoSQL database service designed for internet scale applications. Werner Vogels weblog on building scalable and robust distributed systems.
Evaluating these on three levels—data center, host, and application architecture (plus code)—is helpful. Application architectures might not be conducive to rehosting. Reduce the volume of data volumes requested from databases (for example, request all, filter in memory). Is the solution to just move all workloads to the cloud?
Apache Cassandra is an open-source, distributed, NoSQL database. Because of its scalability and distributed architecture, thousands of companies trust it to run their cloud and hybrid-based workloads at high availability without compromising performance. Microsoft Azure offers multiple ways to manage Apache Cassandra databases.
These range from the simple lift-and-shift re-hosting approach to the significant architectural changes involved in refactoring. “Caching’s one of the key components of any commerce application,” as it has a major impact on performance, Bollampally said. For each on-premises application, Tractor Supply Co.
I am excited to share with you that today we are expanding DynamoDB with streams, cross-region replication, and database triggers. Streams provide you with the underlying infrastructure to create new applications, such as continuously updated free-text search indexes, caches, or other creative extensions requiring up-to-date table changes.
Heading into 2024, SQL databases will remain essential in data management, increasingly using distributed systems to meet growing needs for scalability and reliability. According to 2023 statistics, 49% of web applications use an SQL-based database , with SQL having a 75% adoption rate in the IT industry.
There are many naive solutions possible for this problem for example: Write different runs in different databases. Instead our challenge was to implement this feature on top of Cassandra and ElasticSearch databases because that’s what Marken uses. Marken Architecture Marken’s architecture diagram is as follows.
To make data count and to ensure cloud computing is unabated, companies and organizations must have highly available databases. A basic high availability database system provides failover (preferably automatic) from a primary database node to redundant nodes within a cluster. HA is sometimes confused with “fault tolerance.”
Organizations are depending more and more on distributed architectures to provide application services. For example, when monitoring a database, you’ll want to know about any latency when writing data to a disk or average query response time. Dynatrace news. This trend is prompting advances in both observability and monitoring.
Today, we added two important choices for customers running high performance apps in the cloud: support for Redis in Amazon ElastiCache and a new high memory database instance (db.cr1.8xlarge) for Amazon RDS. No single databasearchitecture or solution can meet all of Amazon.com’s or our customers’ needs.
Dynatrace’s Lambda extension fully supports Arm-based architectures. You can use Dynatrace to monitor all your AWS Lambda functions, whether they are running on x86 or Arm architecture. According to the official AWS announcement, Graviton2-based Lambda functions offer up to 34% better price-performance improvement.
Key Takeaways Redis offers complex data structures and additional features for versatile data handling, while Memcached excels in simplicity with a fast, multi-threaded architecture for basic caching needs. Introduction Caching serves a dual purpose in web development – speeding up client requests and reducing server load.
A cleanup process to prune stale relationships from the database. Over time, each node caches a subset of subproblems to support a distributed cache, reduce the datastore load, and achieve SpiceDB’s horizontal scalability. What was problematic about this design? SpiceDB walks the graph and decomposes it into subproblems.
RevenueCat extensively uses caching to improve the availability and performance of its product API while ensuring consistency. The company shared its techniques to deliver the platform, which can handle over 1.2 billion daily API requests. The team at RevenueCat created an open-source memcache client that provides several advanced features.
Active Memory Caching. When you want to get data that you already had quickly, you need to do caching — caching stores data that a user recently retrieved. Caching partially stores your data and is not used as permanent storage. Caching partially stores your data and is not used as permanent storage.
Andreas Andreakis , Ioannis Papapanagiotou Overview Change-Data-Capture (CDC) allows capturing committed changes from a database in real-time and propagating those changes to downstream consumers [1][2]. In databases like MySQL and PostgreSQL, transaction logs are the source of CDC events. Designed with High Availability in mind.
Andreas Andreakis , Ioannis Papapanagiotou Overview Change-Data-Capture (CDC) allows capturing committed changes from a database in real-time and propagating those changes to downstream consumers [1][2]. In databases like MySQL and PostgreSQL, transaction logs are the source of CDC events. Designed with High Availability in mind.
As organizations adopt microservices architecture with cloud-native technologies such as Microsoft Azure , many quickly notice an increase in operational complexity. The Azure Well-Architected Framework is a set of guiding tenets organizations can use to evaluate architecture and implement designs that will scale over time.
I’ve used a fourth instance to host a PMM server to monitor servers A and B and used the data collected by the PMM agents installed on the database servers to compare performance. That’s a heritage of the LAMP model when the same server would host both the database and the web server.
In the world of databases, data management, and data platforms, this entropy usually takes the form of a simple database or data platform that might be ideal for early use cases evolving (or rather, de volving) into an expensive and unmanageable nightmare due to operational strain from use-case gluttony. How hard can it be?
OpenTelemetry reference architecture. This occurs once data is safely stored within a local cache. Cloud databases excel at storing large volumes of information for later reference, and this data often has business value or privacy restrictions. Source: OpenTelemetry Documentation. What is telemetry data?
In previous blog posts, we introduced the Key-Value Data Abstraction Layer and the Data Gateway Platform , both of which are integral to Netflix’s data architecture. Note: Contrary to what the name may suggest, this system is not built as a general-purpose time series database. Also, with Cassandra 4.x,
In fact, before we even had the word microservices in our lexicon, back when it was just good old-fashioned service-oriented architecture, we were talking about data: how to access it, where it lives, who “owns” it. Back then, the most common pattern I saw for service-based systems was sharing a database among multiple services.
Choosing a cloud DBMS: architectures and tradeoffs Tan et al., As it is infeasible to test every OLAP system runnable on AWS, we chose widely-used systems that represented a variety of architectures and cost models. Query performance is measured from both warm and cold caches. VLDB’19. The last word.
Here’s the update: Improve architectural design to eliminate SSO bottleneck risk [In progress] Security and access are critical aspects of our architecture, and as such, there are many areas we’re looking to improve. Hopefully never.) This has been completed.
You can get summaries of your database servers, or you verify replication lag on MySQL and PostgreSQL servers. You get thirty-eight scripts that can do any manner of actions, and you will find them very valuable in your regular database work. 33-generic Architecture | CPU = 64-bit, OS = 64-bit Threading | NPTL 2.35 Caches | 12.4G
With its widespread use in modern application architectures, understanding the ins and outs of Redis monitoring is essential for any tech professional. Redis Monitoring Essentials Ensuring the performance, reliability, and safety of a Redis database requires active monitoring. Redis, a powerful in-memory data store, is no exception.
Last week we looked at a function shipping solution to the problem; Cloudburst uses the more common data shipping to bring data to caches next to function runtimes (though you could also make a case that the scheduling algorithm placing function execution in locations where the data is cached a flavour of function-shipping too).
the order of the rows on your Netflix home page, issuing content licenses when you click play, finding the Open Connect cache closest to you with the content you requested, and many more). A majority of the Netflix product features are either partially or completely dependent on one of our many micro-services (e.g.,
Maintaining rapidly changing data in back-end databases creates bottlenecks that impact responsiveness. In addition, repeatedly accessing back-end databases to serve up popular items, such as product descriptions and news stories, also adds to the bottleneck. The Solution: Distributed Caching.
Maintaining rapidly changing data in back-end databases creates bottlenecks that impact responsiveness. In addition, repeatedly accessing back-end databases to serve up popular items, such as product descriptions and news stories, also adds to the bottleneck. The Solution: Distributed Caching.
The service workers enable the offline usage of the PWA by fetching cached data or informing the user about the absence of an Internet connection. Application shell architecture. When developing a PWA, you can cache the application shell’s resources and assets in the browser. Cached content with IndexedDB.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content