This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In this blog post, we explain what Greenplum is, and break down the Greenplum architecture, advantages, major use cases, and how to get started. It’s architecture was specially designed to manage large-scale data warehouses and business intelligence workloads by giving you the ability to spread your data out across a multitude of servers.
Having a distributed and scalable graph database system is highly sought after in many enterprise scenarios. Do Not Be Misled Designing and implementing a scalable graph database system has never been a trivial task.
The shortcomings and drawbacks of batch-oriented data processing were widely recognized by the BigData community quite a long time ago. As a result, the input data typically goes from the data source to the in-stream pipeline via a persistent buffer that allows clients to move their reading pointers back and forth.
Then, bigdata analytics technologies, such as Hadoop, NoSQL, Spark, or Grail, the Dynatrace data lakehouse technology, interpret this information. Here are the six steps of a typical ITOA process : Define the data infrastructure strategy. Identify data use cases and develop a scalable delivery model with documentation.
We adopted the following mission statement to guide our investments: “Provide a complete and accurate data lineage system enabling decision-makers to win moments of truth.” Nonetheless, Netflix data landscape (see below) is complex and many teams collaborate effectively for sharing the responsibility of our data system management.
Limited data availability constrains value creation. Modern IT environments — whether multicloud, on-premises, or hybrid-cloud architectures — generate exponentially increasing data volumes. Grail addresses today’s challenges of bigdata and cloud everywhere: Grail is highly scalable, cost-effective, and super-fast.
By collecting, accessing and analyzing network data from a variety of sources like VPC Flow Logs , ELB Access Logs, eBPF flow logs on the instances, etc, we can provide network insight to users and central teams through multiple data visualization techniques like Lumen , Atlas , etc. What is BPF?
As cloud and bigdata complexity scales beyond the ability of traditional monitoring tools to handle, next-generation cloud monitoring and observability are becoming necessities for IT teams. Hybrid cloud combines an on-premises or private data center with public cloud infrastructure. What is cloud monitoring?
Logs highlight observability challenges Ingesting, storing, and processing the unprecedented explosion of data from sources such as software as a service, multicloud environments, containers, and serverless architectures can be overwhelming for today’s organizations.
Through effortless provisioning, a larger number of small hosts provide a cost-effective and scalable platform. On-premises data centers invest in higher capacity servers since they provide more flexibility in the long run, while the procurement price of hardware is only one of many cost factors.
As Bigdata and ML became more prevalent and impactful, the scalability, reliability, and usability of the orchestrating ecosystem have increasingly become more important for our data scientists and the company. Meson was based on a single leader architecture with high availability.
When undertaking system migrations, one of the main challenges is establishing confidence and seamlessly transitioning the traffic to the upgraded architecture without adversely impacting the customer experience. This blog series will examine the tools, techniques, and strategies we have utilized to achieve this goal.
Kubernetes has emerged as go to container orchestration platform for data engineering teams. In 2018, a widespread adaptation of Kubernetes for bigdata processing is anitcipated. Organisations are already using Kubernetes for a variety of workloads [1] [2] and data workloads are up next. Key challenges. Performance.
To address this, we propose developing an intelligent agent that can automatically discover, map, and query all data within an enterprise. This “Enterprise Data Model/Architect Agent” employs generative AI techniques for autonomous enterprise data modeling and architecture.
Data scientists and engineers collect this data from our subscribers and videos, and implement data analytics models to discover customer behaviour with the goal of maximizing user joy. The processed data is typically stored as data warehouse tables in AWS S3. Moving data with Bulldozer at Netflix.
Using Marathon, its data center operating system (DC/OS) plugin, Mesos becomes a full container orchestration environment that, like Kubernetes and Docker Swarm, discovers services, balances loads, and manages application containers. Mesos also supports other orchestration engines, including Kubernetes and Docker Swarm.
Key Takeaways Distributed storage systems benefit organizations by enhancing data availability, fault tolerance, and system scalability, leading to cost savings from reduced hardware needs, energy consumption, and personnel. Variations within these storage systems are called distributed file systems.
This article will help you understand the core differences in data structure, scalability, and use cases. Whether you need a relational database for complex transactions or a NoSQL database for flexible data storage, weve got you covered. Diverging from MySQLs methodology, MongoDB employs an architecture without fixed schemas.
Integrating such a backend service system supported by RabbitMQ into a web application’s architecture can drastically alter its operational dynamics. It enables the smooth processing of various actions like uploading user content, sending notifications, or performing heavy-duty data operations.
Heading into 2024, SQL databases will remain essential in data management, increasingly using distributed systems to meet growing needs for scalability and reliability. They keep the features that developers like but can handle much more data, similar to NoSQL systems.
The Data Mesh SQL Processor is a platform-managed, parameterized Flink Job that takes schematized sources and a Flink SQL query that will be executed against those sources. By leveraging Flink SQL within a Data Mesh Processor, we were able to support the streaming SQL functionality without changing the architecture of Data Mesh.
This approach allows companies to combine the security and control of private clouds with public clouds’ scalability and innovation potential. Defining Hybrid Cloud Strategy The decision-making process about where to situate data and applications is vital to any hybrid cloud solution. A hybrid cloud strategy could be your answer.
In this comparison of Redis vs Memcached, we strip away the complexity, focusing on each in-memory data store’s performance, scalability, and unique features. Redis is better suited for complex data models, and Memcached is better suited for high-throughput, string-based caching scenarios.
Whether in analyzing A/B tests, optimizing studio production, training algorithms, investing in content acquisition, detecting security breaches, or optimizing payments, well structured and accurate data is foundational. Backfill: Backfilling datasets is a common operation in bigdata processing. append, overwrite, etc.).
This blog post gives a glimpse of the computer systems research papers presented at the USENIX Annual Technical Conference (ATC) 2019, with an emphasis on systems that use new hardware architectures. As a consequence, the vast majority of the papers in the past has usually focused on conventional X86 or GPU-accelerated architectures.
Werner Vogels weblog on building scalable and robust distributed systems. To our shareowners: Random forests, naïve Bayesian estimators, RESTful services, gossip protocols, eventual consistency, data sharding, anti-entropy, Byzantine quorum, erasure coding, vector clocks. Driving down the cost of Big-Data analytics.
Werner Vogels weblog on building scalable and robust distributed systems. These trade-offs have even impacted the way the lowest level building blocks in our computer architectures have been designed. All Things Distributed. Expanding the Cloud - Adding the Incredible Power of the Amazon EC2 Cluster GPU Instances. Comments ().
Given this, enterprises, public sector bodies, startups, and small businesses are looking to adopt agile, scalable, and secure public cloud solutions. Access to secure, scalable, low-cost AWS infrastructure in Canada allows customers to innovate and provide tools to meet privacy, sovereignty, and compliance requirements. Scalability.
Scrapinghub is hiring a Senior Software Engineer (BigData/AI). You will be designing and implementing distributed systems : large-scale web crawling platform, integrating Deep Learning based web data extraction components, working on queue algorithms, large datasets, creating a development platform for other company departments, etc.
Scrapinghub is hiring a Senior Software Engineer (BigData/AI). You will be designing and implementing distributed systems : large-scale web crawling platform, integrating Deep Learning based web data extraction components, working on queue algorithms, large datasets, creating a development platform for other company departments, etc.
Scrapinghub is hiring a Senior Software Engineer (BigData/AI). You will be designing and implementing distributed systems : large-scale web crawling platform, integrating Deep Learning based web data extraction components, working on queue algorithms, large datasets, creating a development platform for other company departments, etc.
Werner Vogels weblog on building scalable and robust distributed systems. The scalability, reliability and durability requirements for Cloud Drive are very high which is why they decided to make use of the Amazon Simple Storage Service (S3) as the core component of their service. Driving down the cost of Big-Data analytics.
Today’s streaming analytics architectures are not equipped to make sense of this rapidly changing information and react to it as it arrives. This data is also periodically uploaded to a data lake for offline batch analysis that calculates key statistics and looks for big trends that can help optimize operations.
Scrapinghub is hiring a Senior Software Engineer (BigData/AI). You will be designing and implementing distributed systems : large-scale web crawling platform, integrating Deep Learning based web data extraction components, working on queue algorithms, large datasets, creating a development platform for other company departments, etc.
We built AutoOptimize to efficiently and transparently optimize the data and metadata storage layout while maximizing their cost and performance benefits. This article will list some of the use cases of AutoOptimize, discuss the design principles that help enhance efficiency, and present the high-level architecture.
Werner Vogels weblog on building scalable and robust distributed systems. Additionally, many high-end HPC applications take advantage of knowing their in-house hardware platforms to achieve major speedup by exploiting the specific processor architecture. Driving down the cost of Big-Data analytics. Comments ().
Werner Vogels weblog on building scalable and robust distributed systems. Often these namespaces are hierarchical in nature such that it becomes easier to manage them and to decentralize control, which makes the system more scalable. a Fast and Scalable NoSQL Database Service Designed for Internet Scale Applications.
Werner Vogels weblog on building scalable and robust distributed systems. There are sessions in many different categories: Architecture, BigData, HPC, Computer & Networking, Storage, Databases, Security, Tools & Languages, Media Sharing & Content Delivery, Managing AWS Resources, Enterprise IT, Mobile, Start-up, and more.
Shell leverages AWS for bigdata analytics to help achieve these goals. Due to the exponential growth of the biology and informatics fields, Unilever needs to maintain this new program within a highly-scalable environment that supports parallel computation and heavy data storage demands.
Werner Vogels weblog on building scalable and robust distributed systems. This team is constantly rethinking the assumptions behind how traditional databases were built and constantly working on building the right database architectures suited for the Cloud environment. Driving down the cost of Big-Data analytics.
Werner Vogels weblog on building scalable and robust distributed systems. Visiting future customers is equally exiting as you get a change to understand their current architecture, if it is a migration, and how they plan to exploit cloud services in their new setup. Driving down the cost of Big-Data analytics.
Werner Vogels weblog on building scalable and robust distributed systems. Big news this week was of course the launch of Cluster GPU instances for Amazon EC2. Understanding Throughput-Oriented Architectures - background article in CACM on massively parallel and throughput vs latency oriented architectures. Comments ().
The stateless + RInk (S+RInK) architecture attempts to provide the best of both worlds: to simultaneously offer both the implementation and operational simplicity of stateless application servers and the performance benefits of servers caching state in RAM. We’ve seen similar high marshalling overheads in bigdata systems too.)
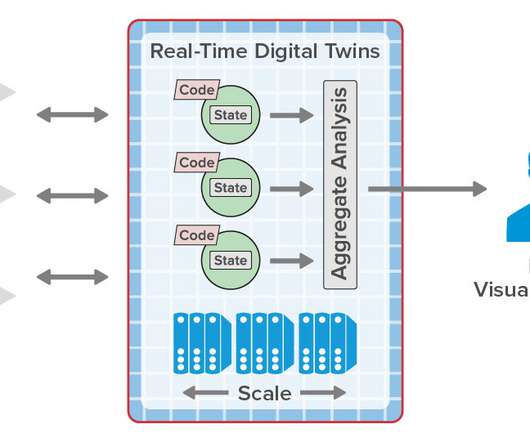
Real-Time Digital Twins Can Add Important New Capabilities to Telematics Systems and Eliminate Scalability Bottlenecks. However, telematics architectures face challenges in responding to telemetry in real time. Current Telematics Architecture. Challenges for Current Architectures.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content