This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This article outlines the key differences in architecture, performance, and use cases to help determine the best fit for your workload. RabbitMQ follows a message broker model with advanced routing, while Kafkas event streaming architecture uses partitioned logs for distributed processing. What is RabbitMQ? What is Apache Kafka?
As more organizations embrace microservices-based architecture to deliver goods and services digitally, maintaining customer satisfaction has become exponentially more challenging. Instead, they can ensure that services comport with the pre-established benchmarks. Latency is the time that it takes a request to be served.
Compare Latency. lower latency compared to DigitalOcean for PostgreSQL. Now, let’s take a look at the throughput and latency performance of our comparison. Next, we are going to test and compare the latency performance between ScaleGrid and DigitalOcean for PostgreSQL. PostgreSQL DigitalOcean Latency Averages (ms).
Stream processing One approach to such a challenging scenario is stream processing, a computing paradigm and software architectural style for data-intensive software systems that emerged to cope with requirements for near real-time processing of massive amounts of data. This significantly increases event latency.
Leveraging pgbench , which is a benchmarking utility that comes bundled with PostgreSQL, I will put the cluster through its paces by executing a series of DML operations. And now, execute the benchmark: -- execute the following on the coordinator node pgbench -c 20 -j 3 -T 60 -P 3 pgbench The results are not pretty.
Choosing a cloud DBMS: architectures and tradeoffs Tan et al., use the TPC-H benchmark to assess Redshift, Redshift Spectrum, Athena, Presto, Hive, and Vertica to find out what works best and the trade-offs involved. in the TPC-H Benchmark Standard for details of the queries). VLDB’19. System initialisation time.
Most publications have simply reported the benchmark improvement claims, but if you stop to think about them, the numbers dont make sense based on a simplistic view of the technology changes. So first thing to understand is that the benchmark skips a generation and compares product that differs over about a two year interval.
I have a lot of historical data using my ReadOnly benchmark (as described in some of the earliest entries in this blog [link] A read-only access pattern removes the need to understand and explain the many complexities associated with the “streaming stores” typically used in the STREAM benchmark (e.g., Stay tuned!
Here’s some predictions I’m making: Jack Dongarra’s efforts to highlight the low efficiency of the HPCG benchmark as an issue will influence the next generation of supercomputer architectures to optimize for sparse matrix computations. Next generation architectures will use CXL3.0 petaflops, which is 0.8% of peak capacity.
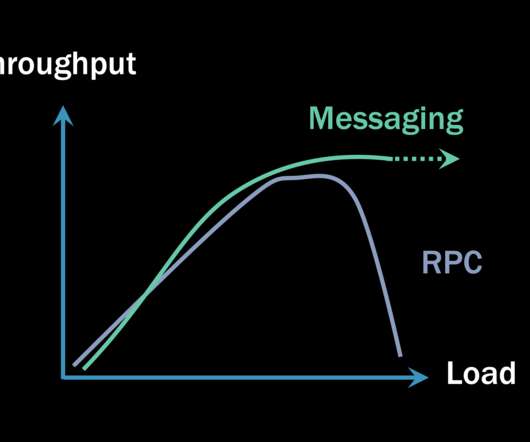
Some will claim that any type of RPC communication ends up being faster (meaning it has lower latency) than any equivalent invocation using asynchronous messaging. If you did such a benchmark, here’s an incomplete picture you might end up with: Graph of microbenchmark showing RPC is faster than messaging. Messaging doesn’t do that.
Key Takeaways Redis offers complex data structures and additional features for versatile data handling, while Memcached excels in simplicity with a fast, multi-threaded architecture for basic caching needs. However, Redis, with its single-threaded architecture, may encounter bottlenecks with large numbers of concurrent connections.
When designing an architecture, many components need to be considered before deciding on the best solution. Let us take a look also the latency: Here the situation starts to be a little bit more complicated. MySQL Router is the one that has the higher latency no matter what. That allows it to go a bit further. and ProxySQL 6.6k.
This includes all architectures, all compilers, all operating systems, and all system configurations. To show that I can criticize my own work as well, here I show that sustained memory bandwidth (using an approximation to the STREAM Benchmark ) is also inadequate as a single figure of metric. (It
To illustrate this, I ran the Sysbench-TPCC synthetic benchmark against two different GCP instances running a freshly installed Percona Server for MySQL version 8.0.31 on CentOS 7, both of them spec’d with four vCPUs but with the second one (server B) having a tad over twice as much memory than the reference one (server A).
This will be clearly visible in PostgreSQL performance benchmarks as a “ Sawtooth wave ” pattern observed by Vadim in his tests: As we can see, the throughput suddenly drops after every checkpoint due to heavy WAL writing and gradually picks up until the next checkpoint. But this comes with a considerable performance implication.
This is a complex topic, but to borrow from a recent post , web performance expands access to information and services by reducing latency and variance across interactions in a session, with a particular focus on the tail of the distribution (P75+). Consistent performance matters just as much as low average latency.
They can also bolster uptime and limit latency issues or potential downtimes. Adopting Infrastructure as Code (IaaC) makes transitioning to a multi-cloud architecture more efficient, allowing streamlined setup processes.
There was an excellent first benchmarking report of the Cluster GPU Instances by the folks at Cycle Computing - " A Couple More Nails in the Coffin of the Private Compute Cluster " The Top500 supercomputer list. The Cluster Compute and the Cluster GPU Instances are now supported by Amazon Elastic Map Reduce.
This includes all architectures, all compilers, all operating systems, and all system configurations. To show that I can criticize my own work as well, here I show that sustained memory bandwidth (using an approximation to the STREAM Benchmark ) is also inadequate as a single figure of metric. (It
Budgets are scaled to a benchmark network & device. One distinct trend is a belief that a JavaScript framework and Single-Page Architecture (SPA) is a must for PWA development. Deciding what benchmark to use for a performance budget is crucial. Performance budgets are set early in the life of the project. 400Kbps transfer.
In addition, such custom systems could only be benchmarked once they were deployed, so by the time multiple layers of management had each added a 50% safety margin to the initial SWAG , it was not unusual to see them running at 10% of capacity (but 150% of the lucky hardware salesman’s annual quota).
A recent performance benchmark completed by Intel and BlueData using the BigBench benchmarking kit has shown that the performance ratios for container-based Hadoop workloads on BlueData EPIC are equal to and in some cases, better than bare-metal Hadoop [7]. Performance.
I have a lot of historical data using my ReadOnly benchmark (as described in some of the earliest entries in this blog [link] A read-only access pattern removes the need to understand and explain the many complexities associated with the “streaming stores” typically used in the STREAM benchmark (e.g., Stay tuned!
Last time around we looked at the DeathStarBench suite of microservices-based benchmark applications and learned that microservices systems can be especially latency sensitive, and that hotspots can propagate through a microservices architecture in interesting ways. on end-to-end latency) and less than 0.15% on throughput.
In addition, such custom systems could only be benchmarked once they were deployed, so by the time multiple layers of management had each added a 50% safety margin to the initial SWAG , it was not unusual to see them running at 10% of capacity (but 150% of the lucky hardware salesman’s annual quota).
Put another way, the performance gap between what devices the wealthy carry and what budget shoppers carry grew more this year (252 points) than the year-over-year gains from process and architecture at the volume price point (174 points). That's where the good news ends.
Our customers who deployed Availability Groups were now using servers for primary and secondary replicas with 12+ core sockets and flash storage SSD arrays providing microsecond to low millisecond latencies. First, we looked at the overall architecture of the replica design. The results we achieved were remarkable.
It efficiently manages read and write operations, optimizes data access, and minimizes contention, resulting in high throughput and low latency to ensure that applications perform at their best. Doing extensive benchmarks will be the subject of a future blog post. Let Percona Actively Manage Your Databases To Achieve Peak Performance.
The talk will conclude with a discussion of near-term trends in HPC system balances and some ideas on the fundamental architectural changes that will be required if we ever want to obtain large reductions in cost and power consumption. The official announcement: SC16 Invited Talk Spotlight: Dr. John D.
For anyone benchmarking MySQL with HammerDB it is important to understand the differences from sysbench workloads as HammerDB is targeted at a testing a different usage model from sysbench. maximum transition latency: Cannot determine or is not supported. . HammerDB difference from Sysbench. hardware limits: 1000 MHz - 3.80
Likewise, object access paths must be heavily multi-threaded and avoid lock contention to minimize access latency and maximize throughput. For example, the IMDG must be able to efficiently create millions of objects in each server to make use of its huge storage capacity. Testing Scale-Up Performance.
While this abundance of dashboards and information is by no means unique to Netflix, it certainly holds true within our microservices architecture. Telltale provides Edgar with latencybenchmarks that indicate if the individual trace’s latency is abnormal for this given service.
Many high-end disk subsystems provide high-speed cache facilities to reduce the latency of read and write operations. To learn more about the transaction log architecture, see “Transaction Log Logical Architecture” in SQL Server Books Online. This cache is often supported by a battery-powered backup facility.
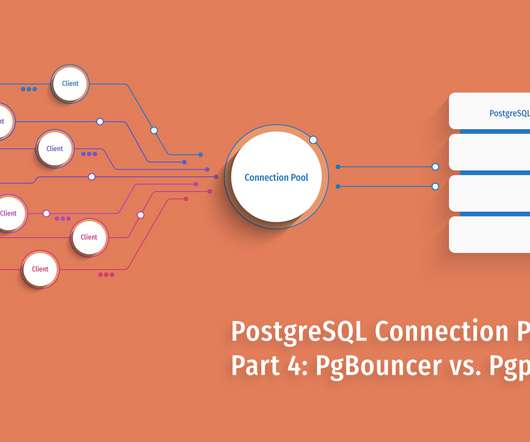
In our previous posts in this series, we spoke at length about using PgBouncer and Pgpool-II , the connection pool architecture and pros and cons of leveraging one for your PostgreSQL deployment. All of the PostgreSQL benchmark tests were run under the following conditions: Initialized pgbench using a scale factor of 100.
An open-source benchmark suite for microservices and their hardware-software implications for cloud & edge systems Gan et al., A typical architecture diagram for one of these services looks like this: Suitably armed with a set of benchmark microservices applications, the investigation can begin! ASPLOS’19.
On your first try, you can use it as a benchmark for optimizations later. Server caches help lower the latency between a Frontend and Backend; since key-value databases are faster than traditional relational SQL databases, it will significantly increase an API’s response time. Common Websocket Architecture. Caching Schemes.
Using a global ASP as a benchmark can further mislead thanks to the distorting effect of ultra-high-end prices rising while shipment volumes stagnate. Sadly, data on latency is harder to get, even from Google's perch, so progress there is somewhat more difficult to judge. Today, either method returns a similar answer.
Each of the two vector units can issue one FMA instruction per cycle, assuming that there are enough independent accumulators to tolerate the 6-cycle dependent-operation latency. Using the minimum number of accumulator registers needed to tolerate the pipeline latency (12), the assembly code for the inner loop is: B1.8:
Each of the two vector units can issue one FMA instruction per cycle, assuming that there are enough independent accumulators to tolerate the 6-cycle dependent-operation latency. Using the minimum number of accumulator registers needed to tolerate the pipeline latency (12), the assembly code for the inner loop is: B1.8:
Two of them are particularly gnarly: fine-tuning rules to perfection and managing a WAF over a multi-CDN architecture. Configuring and Maintaining WAF on a Multi-CDNâ€Multi-CDN architectures, the double-edged swords. Let's dive deep into these challenges.â€1. But instead of porridge, we're talking about WAF rules.Â
Two of them are particularly gnarly: fine-tuning rules to perfection and managing a WAF over a multi-CDN architecture. Configuring and Maintaining WAF on a Multi-CDNMulti-CDN architectures, the double-edged swords. Let's dive deep into these challenges.1. That's where Bot Detection comes in.
SLOG: serializable, low-latency, geo-replicated transactions Ren et al., That’s where SLOG (Serializable LOw-latency, Geo-replicated transactions) comes in. Current state-of-the-art geo-replicated systems force their users to give up one of: (1) strict serializability, (2) low-latency writes, (3) high transactional throughput.
Using this approach, we observed latencies ranging from 1 to 10 seconds, averaging 7.4 Investigation of a Workbench UI Latency Issue was originally published in Netflix TechBlog on Medium, where people are continuing the conversation by highlighting and responding to this story. The input to stdin is sent to the backend (i.e.,
Defining The Environment Choosing a framework, baseline performance cost, Webpack, dependencies, CDN, front-end architecture, CSR, SSR, CSR + SSR, static rendering, prerendering, PRPL pattern. Estimated Input Latency tells us if we are hitting that threshold, and ideally, it should be below 50ms. Large preview ).
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content