This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
To create a CPU core that can execute a large number of instructions in parallel, it is necessary to improve both the architecturewhich includes the overall CPU design and the instruction set architecture (ISA) designand the microarchitecture, which refers to the hardware design that optimizes instruction execution.
Key Takeaways Redis offers complex data structures and additional features for versatile data handling, while Memcached excels in simplicity with a fast, multi-threaded architecture for basic caching needs. Introduction Caching serves a dual purpose in web development – speeding up client requests and reducing server load.
Choosing a cloud DBMS: architectures and tradeoffs Tan et al., use the TPC-H benchmark to assess Redshift, Redshift Spectrum, Athena, Presto, Hive, and Vertica to find out what works best and the trade-offs involved. in the TPC-H Benchmark Standard for details of the queries). VLDB’19. System initialisation time.
To illustrate this, I ran the Sysbench-TPCC synthetic benchmark against two different GCP instances running a freshly installed Percona Server for MySQL version 8.0.31 In MySQL, considering the standard storage engine, InnoDB , the data cache is called Buffer Pool. In PostgreSQL, it is called shared buffers.
For most high-end processors these values have remained in the range of 75% to 85% of the peak DRAM bandwidth of the system over the past 15-20 years — an amazing accomplishment given the increase in core count (with its associated cache coherence issues), number of DRAM channels, and ever-increasing pipelining of the DRAMs themselves.
Most publications have simply reported the benchmark improvement claims, but if you stop to think about them, the numbers dont make sense based on a simplistic view of the technology changes. So first thing to understand is that the benchmark skips a generation and compares product that differs over about a two year interval.
Here’s some predictions I’m making: Jack Dongarra’s efforts to highlight the low efficiency of the HPCG benchmark as an issue will influence the next generation of supercomputer architectures to optimize for sparse matrix computations. Next generation architectures will use CXL3.0 petaflops, which is 0.8% of peak capacity.
When planning your database HA architecture, the size of your company is a great place to start to assess your needs. This base architecture keeps the database available for your applications in case the primary node goes down, whether that involves automatic failover in case of a disaster or planned switchover during a maintenance window.
When designing an architecture, many components need to be considered before deciding on the best solution. In this context, features like filtering, firewalling, or caching are redundant and may consume resources that could be allocated to scaling.
This includes all architectures, all compilers, all operating systems, and all system configurations. To show that I can criticize my own work as well, here I show that sustained memory bandwidth (using an approximation to the STREAM Benchmark ) is also inadequate as a single figure of metric. (It
Given all this, we thought it would be a good opportunity to see how we are doing relative to the competition, and in particular, relative to Microsoft’s AppFabric caching for Windows on-premise servers. One or more specified cache servers are unavailable, which could be caused by busy network or servers. …). Please retry later.
This overhead can be reduced by A) pcid, fully available in Linux 4.14, and B) Huge pages. - **Cache access pattern**: the overheads are exacerbated by certain access patterns that switch from caching well to caching a little less well. This can turn a 1% overhead (syscall cycles alone) into a 7% overhead. In more detail: ## 1.
Budgets are scaled to a benchmark network & device. One distinct trend is a belief that a JavaScript framework and Single-Page Architecture (SPA) is a must for PWA development. Deciding what benchmark to use for a performance budget is crucial. Performance budgets are set early in the life of the project. 400Kbps transfer.
This includes all architectures, all compilers, all operating systems, and all system configurations. To show that I can criticize my own work as well, here I show that sustained memory bandwidth (using an approximation to the STREAM Benchmark ) is also inadequate as a single figure of metric. (It
You can adjust what browser is used, the kind of network connection to employ, the locations to test from, whether or not the browser’s cache is empty or full, how frequently to take the measurements, and more. They are more of a benchmark than a true measurement of real user experience.
For most high-end processors these values have remained in the range of 75% to 85% of the peak DRAM bandwidth of the system over the past 15-20 years — an amazing accomplishment given the increase in core count (with its associated cache coherence issues), number of DRAM channels, and ever-increasing pipelining of the DRAMs themselves.
This overhead can be reduced by A) pcid, fully available in Linux 4.14, and B) Huge pages. - **Cache access pattern**: the overheads are exacerbated by certain access patterns that switch from caching well to caching a little less well. This can turn a 1% overhead (syscall cycles alone) into a 7% overhead. In more detail: ## 1.
Last time around we looked at the DeathStarBench suite of microservices-based benchmark applications and learned that microservices systems can be especially latency sensitive, and that hotspots can propagate through a microservices architecture in interesting ways. ASPLOS’19. Distributed tracing and instrumentation.
Stable media is commonly physical disk storage, but other devices and certain caching facilities qualify as well. Many high-end disk subsystems provide high-speed cache facilities to reduce the latency of read and write operations. This cache is often supported by a battery-powered backup facility.
The talk will conclude with a discussion of near-term trends in HPC system balances and some ideas on the fundamental architectural changes that will be required if we ever want to obtain large reductions in cost and power consumption. The official announcement: SC16 Invited Talk Spotlight: Dr. John D.
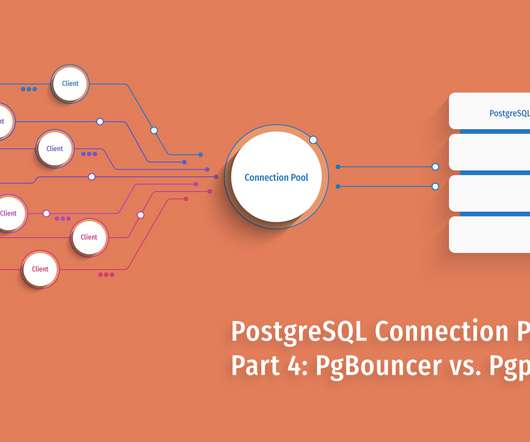
In our previous posts in this series, we spoke at length about using PgBouncer and Pgpool-II , the connection pool architecture and pros and cons of leveraging one for your PostgreSQL deployment. All of the PostgreSQL benchmark tests were run under the following conditions: Initialized pgbench using a scale factor of 100.
On your first try, you can use it as a benchmark for optimizations later. Active Memory Caching. When you want to get data that you already had quickly, you need to do caching — caching stores data that a user recently retrieved. Caching partially stores your data and is not used as permanent storage.
The focus of most published research in architecture is on applications implemented in high-performance, “ close-to-the-metal” languages essentially developed before computers got fast. I suggest it’s long past time to move beyond C and SPEC benchmarks and our exclusive focus on “metal” languages.
An open-source benchmark suite for microservices and their hardware-software implications for cloud & edge systems Gan et al., A typical architecture diagram for one of these services looks like this: Suitably armed with a set of benchmark microservices applications, the investigation can begin! ASPLOS’19.
A then-representative $200USD device had 4-8 slow (in-order, low-cache) cores, ~2GiB of RAM, and relatively slow MLC NAND flash storage. Using a global ASP as a benchmark can further mislead thanks to the distorting effect of ultra-high-end prices rising while shipment volumes stagnate. The Moto G4 , for example.
Intel officially moved on to what they call " Process- Architecture-Optimization (PAO) " in early 2016. AMD has capitalized on this with their Zen architecture , and new Zen 2 architecture , using a modular, 7nm manufacturing process from Taiwan Semiconductor Manufacturing Company (TSMC).
Defining The Environment Choosing a framework, baseline performance cost, Webpack, dependencies, CDN, front-end architecture, CSR, SSR, CSR + SSR, static rendering, prerendering, PRPL pattern. Geekbench CPU performance benchmarks for the highest selling smartphones globally in 2019. compared to early 2015. Shipped in Next.js
Geekbench CPU performance benchmarks for the highest selling smartphones globally in 2019. Still, after all these years, keeping progressive enhancement as the guiding principle of your front-end architecture and deployment is a safe bet. Consider using PRPL pattern and app shell architecture. Baseline performance cost matters.
Over time, costs for S3 and GCS became reasonable and with Egnyte’s storage plugin architecture, our customers can now bring in any storage backend of their choice. Edge caching. In general, Egnyte connect architecture shards and caches data at different levels based on: Amount of data. Nginx for disk based caching.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
































Let's personalize your content